



Software/Datasets
A Hybrid ANN-SNN Architecture for Low-Power and Low-Latency Visual Perception
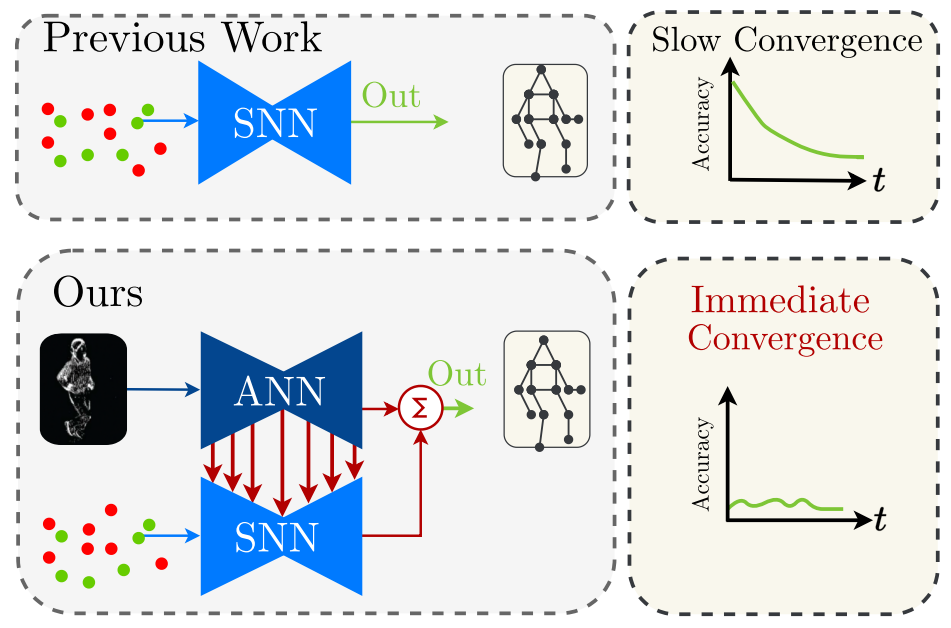
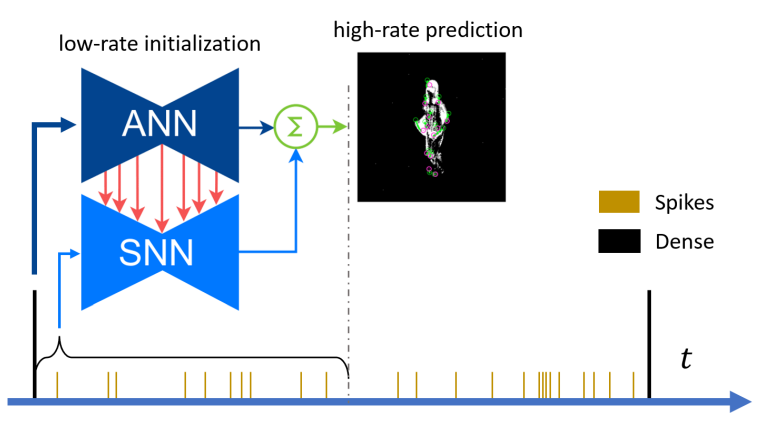
Spiking Neural Networks (SNN) are a class of bioinspired neural networks that promise to bring low-power and low-latency inference to edge-devices through the use of asynchronous and sparse processing. However, being temporal models, SNNs depend heavily on expressive states to generate predictions on par with classical artificial neural networks (ANNs). These states converge only after long transient time periods, and quickly decay in the absence of input data, leading to higher latency, power consumption, and lower accuracy. In this work, we address this issue by initializing the state with an auxiliary ANN running at a low rate. The SNN then uses the state to generate predictions with high temporal resolution until the next initialization phase. Our hybrid ANN-SNN model thus combines the best of both worlds: It does not suffer from long state transients and state decay thanks to the ANN, and can generate predictions with high temporal resolution, low latency, and low power thanks to the SNN. We show for the task of eventbased 2D and 3D human pose estimation that our method consumes 88% less power with only a 4% decrease in performance compared to its fully ANN counterparts when run at the same inference rate. Moreover, when compared to SNNs, our method achieves a 74% lower error. This research thus provides a new understanding of how ANNs and SNNs can be used to maximize their respective benefits.
References
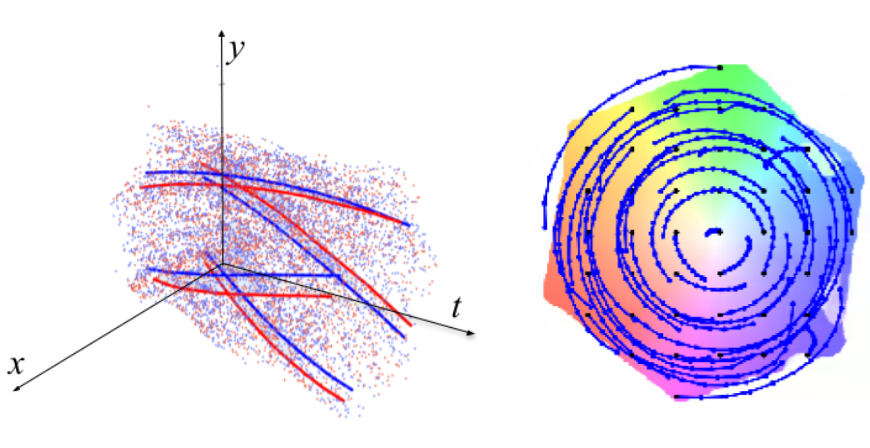
An N-Point Linear Solver for Line and Motion Estimation with Event Cameras
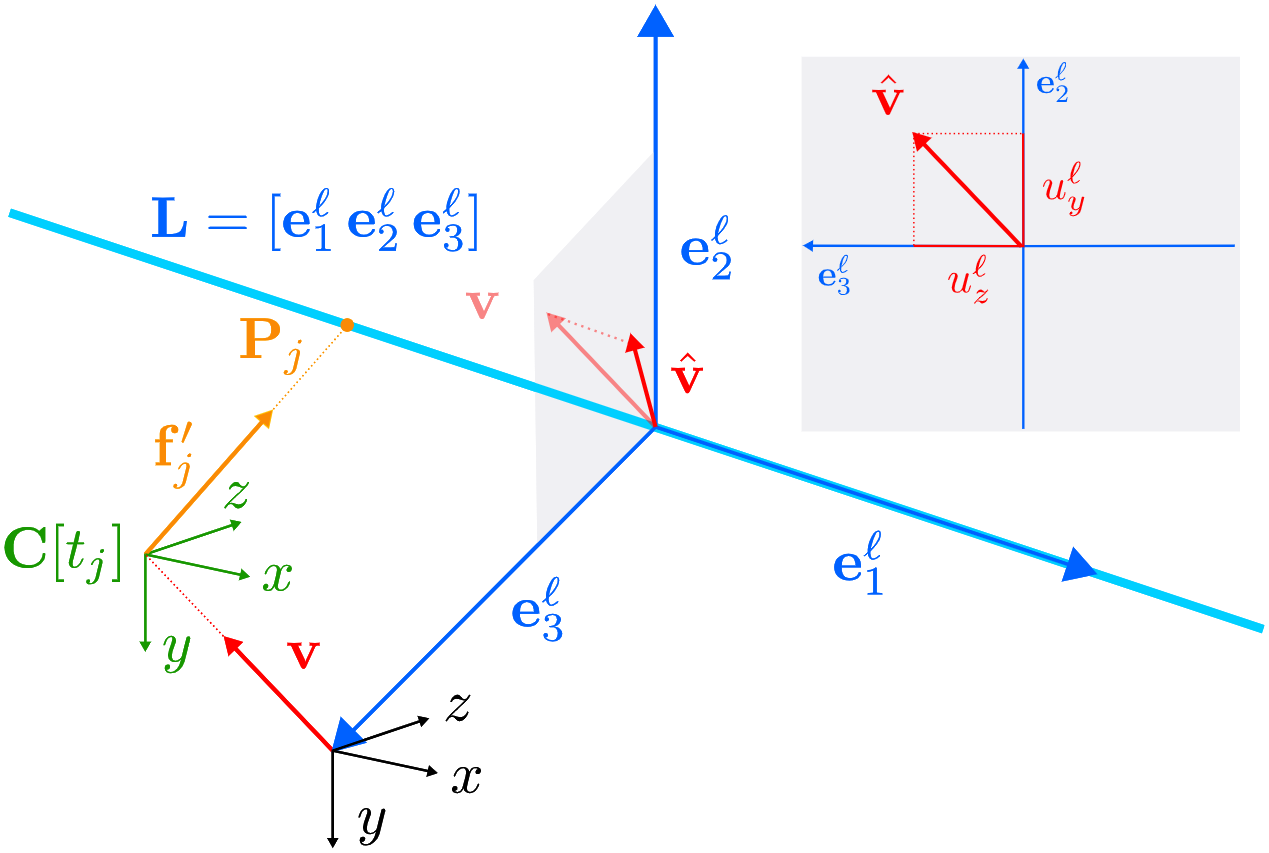
Event cameras respond primarily to edges-formed by strong gradients-and are thus particularly well-suited for line-based motion estimation. Recent work has shown that events generated by a single line each satisfy a polynomial constraint which describes a manifold in the space-time volume. Multiple such constraints can be solved simultaneously to recover the partial linear velocity and line parameters. In this work, we show that, with a suitable line parametrization, this system of constraints is actually linear in the unknowns, which allows us to design a novel linear solver. Unlike existing solvers, our linear solver (i) is fast and numerically stable since it does not rely on expensive root finding, (ii) can solve both minimal and overdetermined systems with more than 5 events (i.e. N >= 5), and (iii) admits the characterization of all degenerate cases and multiple solutions. The found line parameters are singularity-free and have a fixed scale, which eliminates the need for auxiliary constraints typically encountered in previous work. To recover the full linear camera velocity we fuse observations from multiple lines with a novel velocity averaging scheme that relies on a geometrically-motivated residual, and thus solves the problem more efficiently than previous schemes which minimize an algebraic residual. Extensive experiments in synthetic and real-world settings demonstrate that our method surpasses the previous work in numerical stability, and operates over 600 times faster.
References
An N-Point Linear Solver for Line and Motion Estimation with Event Cameras
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2024.
Oral Presentation.
State Space Models for Event Cameras
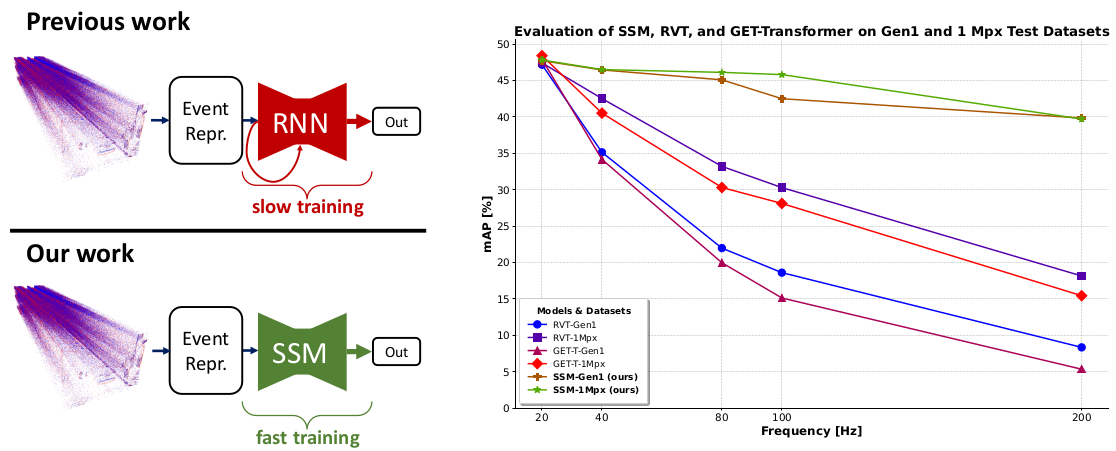
Today, state-of-the-art deep neural networks that process event-camera data first convert a temporal window of events into dense, grid-like input representations. As such, they exhibit poor generalizability when deployed at higher inference frequencies (i.e., smaller temporal windows) than the ones they were trained on. We address this challenge by introducing state-space models (SSMs) with learnable timescale parameters to event-based vision. This design adapts to varying frequencies without the need to retrain the network at different frequencies. Additionally, we investigate two strategies to counteract aliasing effects when deploying the model at higher frequencies. We comprehensively evaluate our approach against existing methods based on RNN and Transformer architectures across various benchmarks, including Gen1 and 1 Mpx event camera datasets. Our results demonstrate that SSM-based models train 33% faster and also exhibit minimal performance degradation when tested at higher frequencies than the training input. Traditional RNN and Transformer models exhibit performance drops of more than 20 mAP, with SSMs having a drop of 3.76 mAP, highlighting the effectiveness of SSMs in event-based vision tasks.
References
State Space Models for Event Cameras
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2024.
Mitigating Motion Blur in Neural Radiance Fields with Events and Frames
Neural Radiance Fields (NeRFs) have shown great potential in novel view synthesis. However, they struggle to render sharp images when the data used for training is affected by motion blur. On the other hand, event cameras excel in dynamic scenes as they measure brightness changes with microsecond resolution and are thus only marginally affected by blur. Recent methods attempt to enhance NeRF reconstructions under camera motion by fusing frames and events. However, they face challenges in recovering accurate color content or constrain the NeRF to a set of predefined camera poses, harming reconstruction quality in challenging conditions. This paper proposes a novel formulation addressing these issues by leveraging both model- and learning-based modules. We explicitly model the blur formation process, exploiting the event double integral as an additional model-based prior. Additionally, we model the event-pixel response using an end-to-end learnable response function, allowing our method to adapt to non-idealities in the real event-camera sensor. We show, on synthetic and real data, that the proposed approach outperforms existing deblur NeRFs that use only frames as well as those that combine frames and events by +6.13dB and +2.48dB, respectively.
References
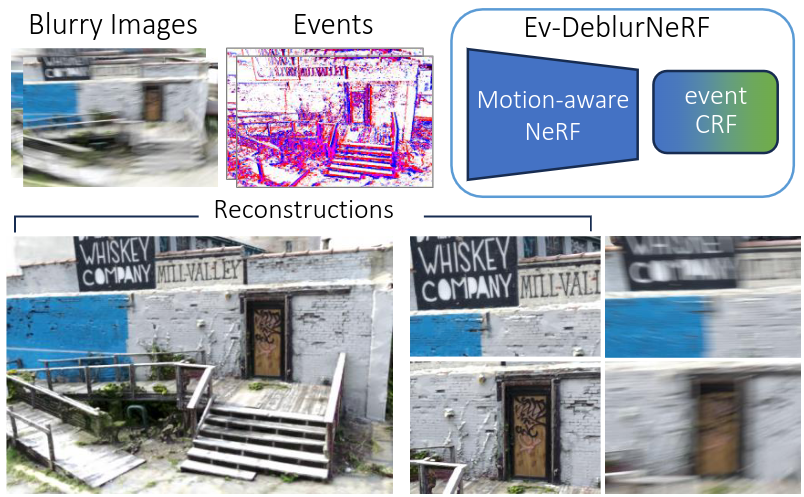
Mitigating Motion Blur in Neural Radiance Fields with Events and Frames
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2024.
Contrastive Initial State Buffer for Reinforcement Learning

In Reinforcement Learning, the trade-off between exploration and exploitation poses a complex challenge for achieving efficient learning from limited samples. While recent works have been effective in leveraging past experiences for policy updates, they often overlook the potential of reusing past experiences for data collection. Independent of the underlying RL algorithm, we introduce the concept of a Contrastive Initial State Buffer, which strategically selects states from past experiences and uses them to initialize the agent in the environment in order to guide it toward more informative states. We validate our approach on two complex robotic tasks without relying on any prior information about the environment: (i) locomotion of a quadruped robot traversing challenging terrains and (ii) a quadcopter drone racing through a track. The experimental results show that our initial state buffer achieves higher task performance than the nominal baseline while also speeding up training convergence.
References
Dense Continuous-Time Optical Flow from Events and Frames
We present a method for estimating dense continuous-time optical flow. Traditional dense optical flow methods compute the pixel displacement between two images. Due to missing information, these approaches cannot recover the pixel trajectories in the blind time between two images. In this work, we show that it is possible to compute per-pixel, continuous-time optical flow by additionally using events from an event camera. Events provide temporally fine-grained information about movement in image space due to their asynchronous nature and microsecond response time. We leverage these benefits to predict pixel trajectories densely in continuous-time via parameterized Bezier curves. To achieve this, we introduce multiple innovations to build a neural network with strong inductive biases for this task: First, we build multiple sequential correlation volumes in time using event data. Second, we use Bezier curves to index these correlation volumes at multiple timestamps along the trajectory. Third, we use the retrieved correlation to update the Bezier curve representations iteratively. Our method can optionally include image pairs to boost performance further. The proposed approach outperforms existing image-based and event-based methods by 11.5 % lower EPE on DSEC-Flow. Finally, we introduce a novel synthetic dataset MultiFlow for pixel trajectory regression on which our method is currently the only successful approach.
References
Dense Continuous-Time Optical Flow from Events and Frames
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024.
Revisiting Token Pruning for Object Detection and Instance Segmentation
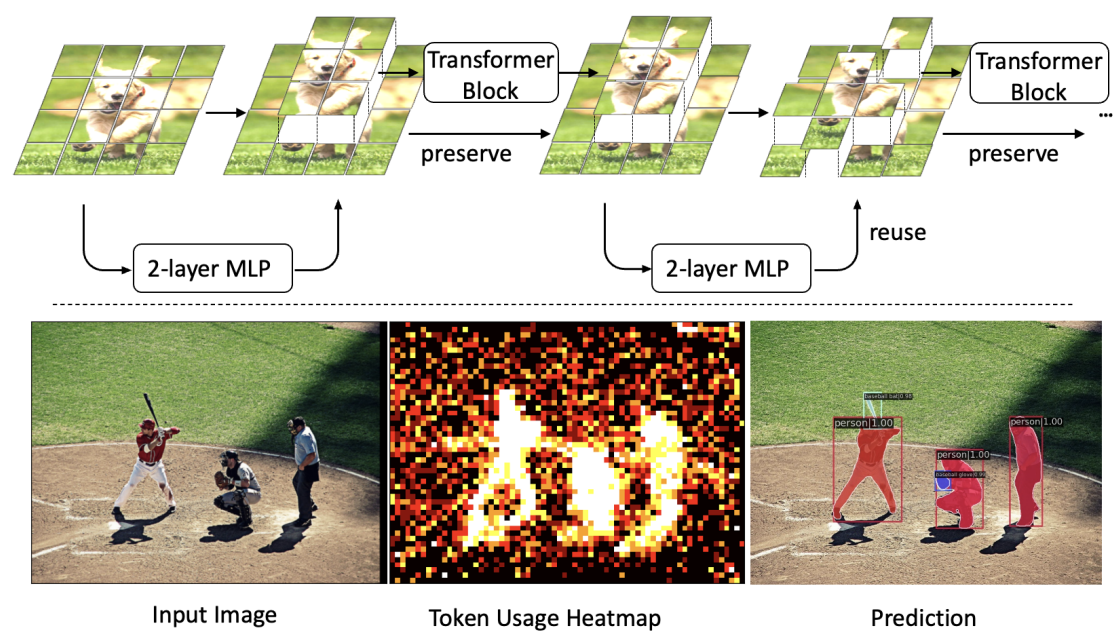
Vision Transformers (ViTs) have shown impressive performance in computer vision, but their high computational cost, quadratic in the number of tokens, limits their adoption in computation-constrained applications. However, this large number of tokens may not be necessary, as not all tokens are equally important. In this paper, we investigate token pruning to accelerate inference for object detection and instance segmentation, extending prior works from image classification. Through extensive experiments, we offer four insights for dense tasks: (i) tokens should not be completely pruned and discarded, but rather preserved in the feature maps for later use. (ii) reactivating previously pruned tokens can further enhance model performance. (iii) a dynamic pruning rate based on images is better than a fixed pruning rate. (iv) a lightweight, 2-layer MLP can effectively prune tokens, achieving accuracy comparable with complex gating networks with a simpler design. We evaluate the impact of these design choices on COCO dataset and present a method integrating these insights that outperforms prior art token pruning models, significantly reducing performance drop from ~1.5 mAP to ~0.3 mAP for both boxes and masks. Compared to the dense counterpart that uses all tokens, our method achieves up to 34% faster inference speed for the whole network and 46% for the backbone.
References

From Chaos Comes Order: Ordering Event Representations for Object Recognition and Detection
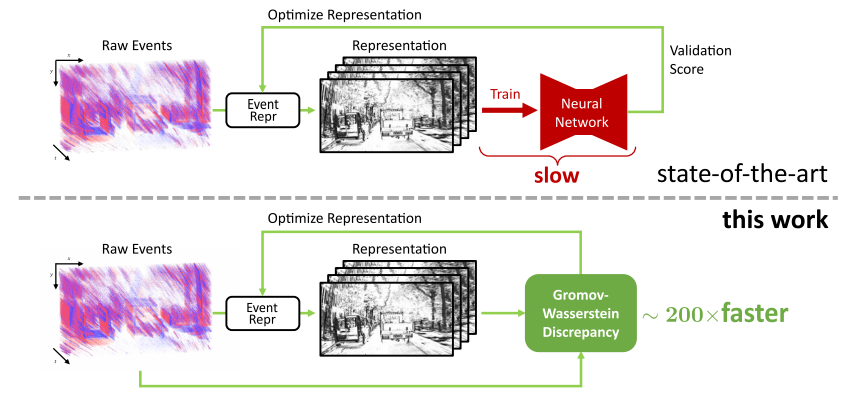
Selecting dense event representations for deep neural networks is exceedingly slow since it involves training a neural network for each representation and selecting the best one based on the validation score. In this work, we eliminate this bottleneck by selecting the representation based on the Gromov-Wasserstein Discrepancy (GWD) on the validation set. This metric is 200 times faster to compute and preserves the task performance ranking of event representations across multiple representations, network backbones, datasets and tasks. We use it to, for the first time, perform a hyperparameter search on a large family of event representations, revealing new and powerful event representations that exceed the state-of-the-art. Our optimized representations outperform existing representations by 1.7 mAP on the 1 Mpx dataset and 0.3 mAP on the Gen1 dataset, two established object detection benchmarks, and reach a 3.8% higher classification score on the mini N-ImageNet benchmark. Moreover, we outperform state-of-the-art by 2.1 mAP on Gen1 and state-of-the-art feed-forward methods by 6.0 mAP on the 1 Mpx datasets. This work opens a new unexplored field of explicit representation optimization for event-based learning.
References
Autonomous Power Line Inspection with Drones via Perception-Aware MPC

Drones have the potential to revolutionize power line inspection by increasing productivity, reducing inspection time, improving data quality, and eliminating the risks for human operators. Current state-of-the-art systems for power line inspection have two shortcomings: (i) control is decoupled from perception and needs accurate information about the location of the power lines and masts; (ii) collision avoidance is decoupled from the power line tracking, which results in poor tracking in the vicinity of the power masts, and, consequently, in decreased data quality for visual inspection. In this work, we propose a model predictive controller (MPC) that overcomes these limitations by tightly coupling perception and action. Our controller generates commands that maximize the visibility of the power lines while, at the same time, safely avoiding the power masts. For power line detection, we propose a lightweight learning-based detector that is trained only on synthetic data and is able to transfer zero-shot to real-world power line images. We validate our system in simulation and real-world experiments on a mock-up power line infrastructure. We release the code and dataset open-source.
References

Champion-level Drone Racing using Deep Reinforcement Learning

First-person view (FPV) drone racing is a televised sport in which professional competitors pilot high-speed aircraft through a three-dimensional circuit. Each pilot sees the environment from their drone's perspective via video streamed from an onboard camera. Reaching the level of professional pilots with an autonomous drone is challenging since the robot needs to fly at its physical limits while estimating its speed and location in the circuit exclusively from onboard sensors. Here we introduce Swift, an autonomous system that can race physical vehicles at the level of the human world champions. The system combines deep reinforcement learning in simulation with data collected in the physical world. Swift competed against three human champions, including the world champions of two international leagues, in real-world head-to-head races. Swift won multiple races against each of the human champions and demonstrated the fastest recorded race time. This work represents a milestone for mobile robotics and machine intelligence, which may inspire the deployment of hybrid learning-based solutions in other physical systems.
References

Champion-level Drone Racing using Deep Reinforcement Learning
Nature, 2023
Active Exposure Control for Robust Visual Odometry in HDR Environments

We propose an active exposure control method to improve the robustness of visual odometry in HDR (high dynamic range) environments. Our method evaluates the proper exposure time by maximizing a robust gradient-based image quality metric. The optimization is achieved by exploiting the photometric response function of the camera. Our exposure control method is evaluated in different real world environments and outperforms the built-in auto-exposure function of the camera. To validate the benefit of our approach, we adapt a state-of-the-art visual odometry pipeline (SVO) to work with varying exposure time and demonstrate improved performance using our exposure control method in challenging HDR environments. We release the code open-source.
References

Real-time Neural MPC: Deep Learning Model Predictive Control for Quadrotors and Agile Robotic Platforms

Model Predictive Control (MPC) has become a popular framework in embedded control for high-performance autonomous systems. However, to achieve good control performance using MPC, an accurate dynamics model is key. To maintain real-time operation, the dynamics models used on embedded systems have been limited to simple first-principle models, which substantially limits their representative power. In contrast to such simple models, machine learning approaches, specifically neural networks, have been shown to accurately model even complex dynamic effects, but their large computational complexity hindered combination with fast real-time iteration loops. With this work, we present Real-time Neural MPC, a framework to efficiently integrate large, complex neural network architectures as dynamics models within a model-predictive control pipeline. Our experiments, performed in simulation and the real world onboard a highly agile quadrotor platform, demonstrate the capabilities of the described system to run learned models with, previously infeasible, large modeling capacity using gradient-based online optimization MPC. Compared to prior implementations of neural networks in online optimization MPC we can leverage models of over 4000 times larger parametric capacity in a 50Hz real-time window on an embedded platform. Further, we show the feasibility of our framework on real-world problems by reducing the positional tracking error by up to 82% when compared to state-of-the-art MPC approaches without neural network dynamics.
References
Cracking Double-Blind Review: Authorship Attribution with Deep Learning
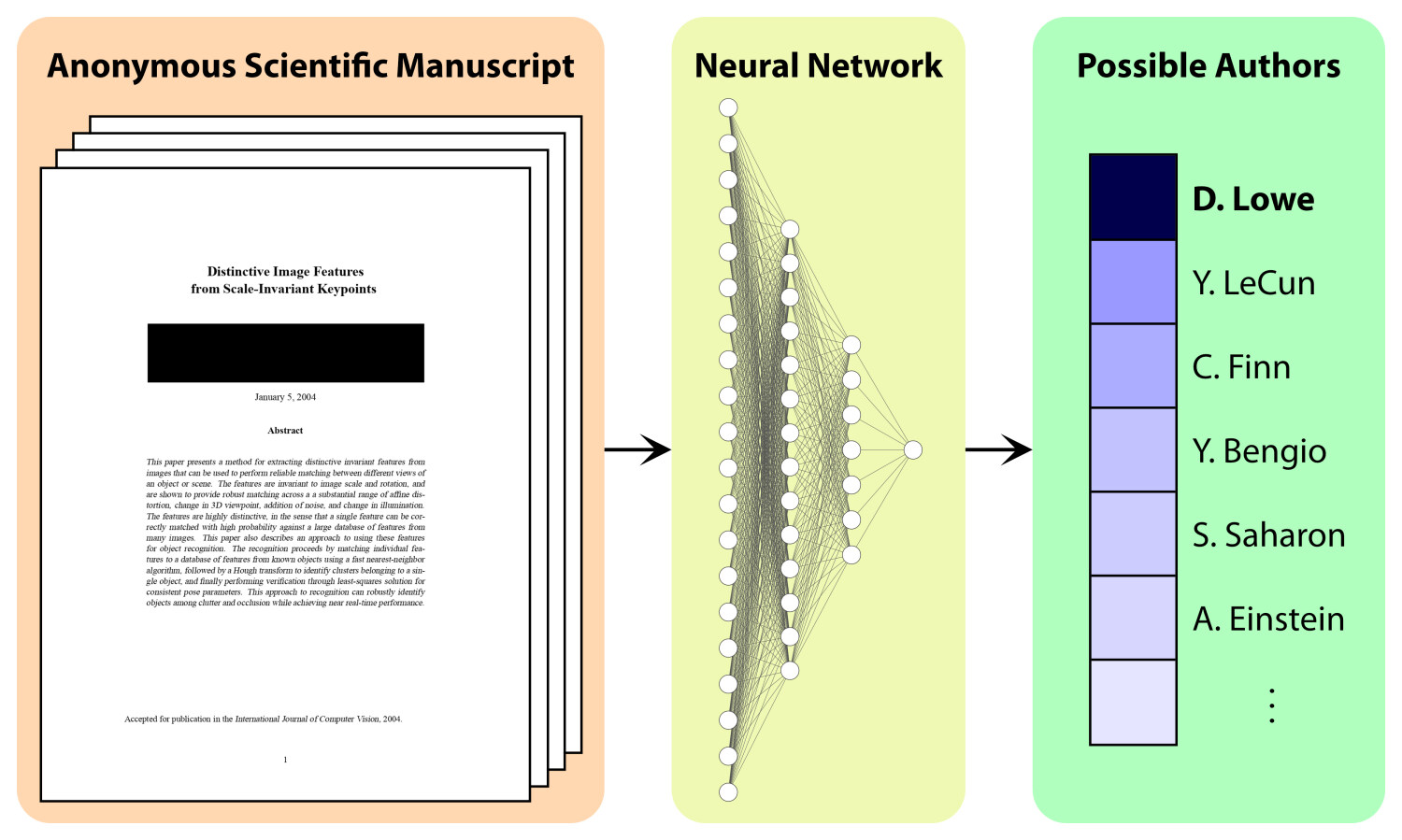
Double-blind peer review is considered a pillar of academic research because it is perceived to ensure a fair, unbiased, and fact-centered scientific discussion. Yet, experienced researchers can often correctly guess from which research group an anonymous submission originates, biasing the peer-review process. In this work, we present a transformer-based, neural-network architecture that only uses the text content and the author names in the bibliography to attribute an anonymous manuscript to an author. To train and evaluate our method, we created the largest authorship-identification dataset to date. It leverages all research papers publicly available on arXiv amounting to over 2 million manuscripts. In arXiv-subsets with up to 2,000 different authors, our method achieves an unprecedented authorship attribution accuracy, where up to 73% of papers are attributed correctly. We present a scaling analysis to highlight the applicability of the proposed method to even larger datasets when sufficient compute capabilities are more widely available to the academic community. Furthermore, we analyze the attribution accuracy in settings where the goal is to identify all authors of an anonymous manuscript. Thanks to our method, we are not only able to predict the author of an anonymous work but we also provide empirical evidence of the key aspects that make a paper attributable. We have open-sourced the necessary tools to reproduce our experiments.
References
Microgravity induces overconfidence in perceptual decision-making

Does gravity affect decision-making? This question comes into sharp focus as plans for interplanetary human space missions solidify. In the framework of Bayesian brain theories, gravity encapsulates a strong prior, anchoring agents to a reference frame via the vestibular system, informing their decisions and possibly their integration of uncertainty. What happens when such a strong prior is altered? We address this question using a self-motion estimation task in a space analog environment under conditions of altered gravity. Two participants were cast as remote drone operators orbiting Mars in a virtual reality environment on board a parabolic flight, where both hyper- and microgravity conditions were induced. From a first-person perspective, participants viewed a drone exiting a cave and had to first predict a collision and then provide a confidence estimate of their response. We evoked uncertainty in the task by manipulating the motion's trajectory angle. Post-decision subjective confidence reports were negatively predicted by stimulus uncertainty, as expected. Uncertainty alone did not impact overt behavioral responses (performance, choice) differentially across gravity conditions. However microgravity predicted higher subjective confidence, especially in interaction with stimulus uncertainty. These results suggest that variables relating to uncertainty affect decision-making distinctly in microgravity, highlighting the possible need for automatized, compensatory mechanisms when considering human factors in space research.
References

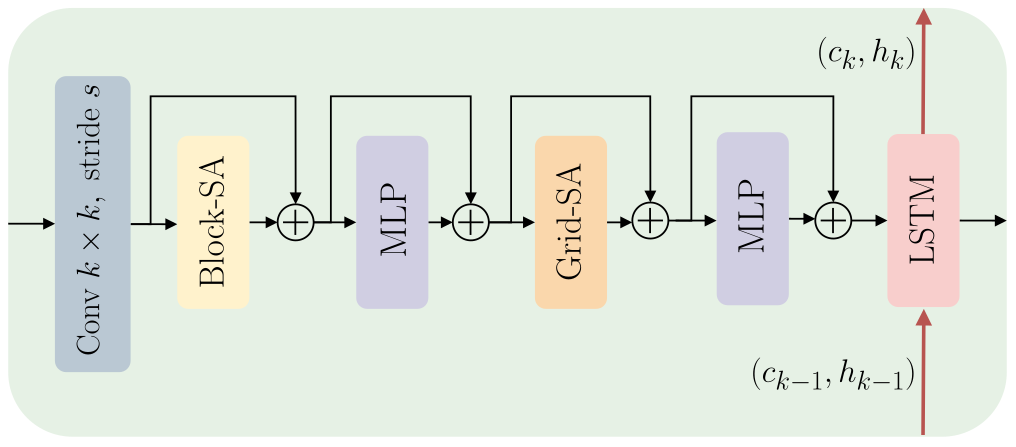
Recurrent Vision Transformers for Object Detection with Event Cameras
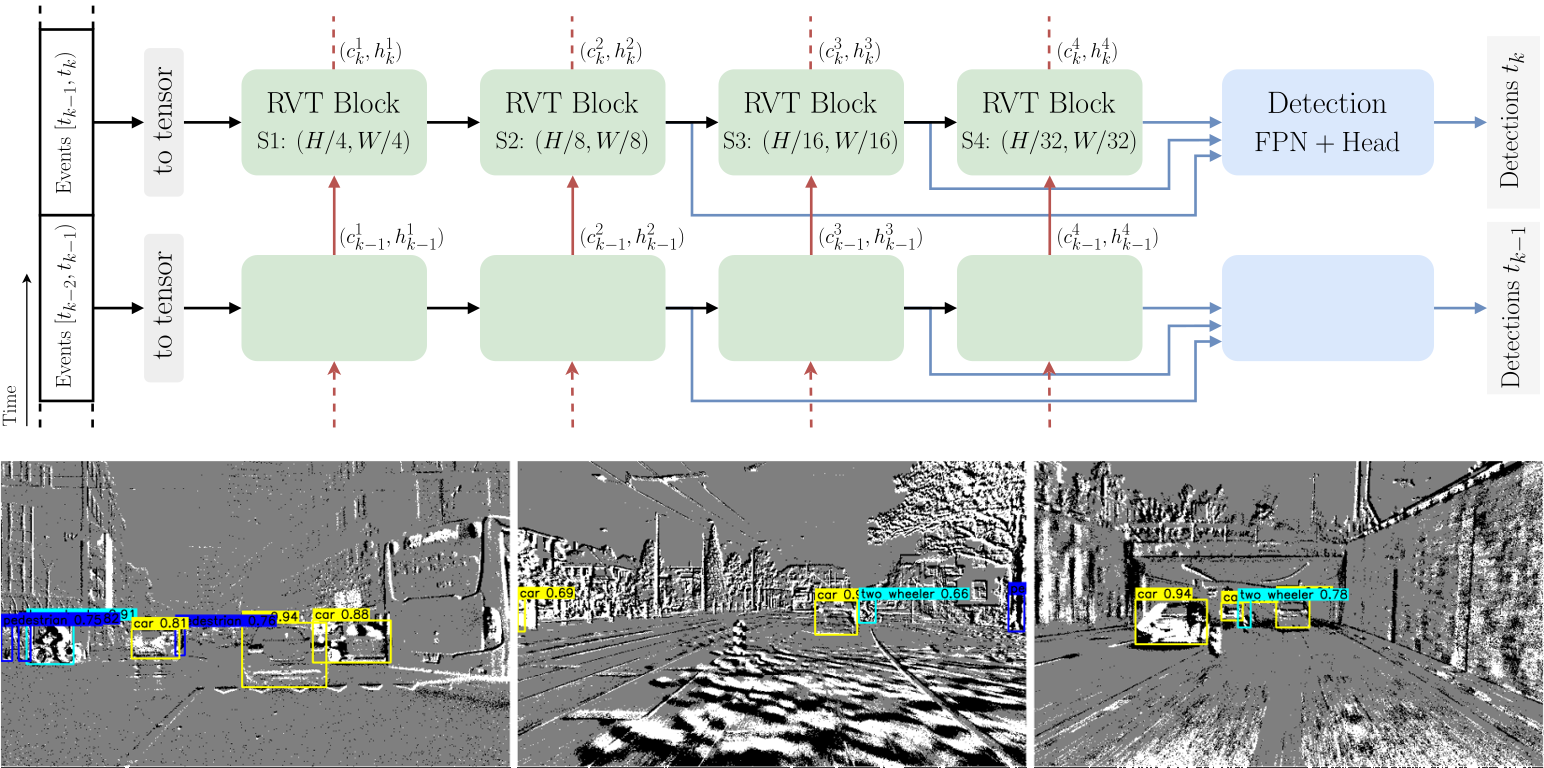
We present Recurrent Vision Transformers (RVTs), a novel backbone for object detection with event cameras. Event cameras provide visual information with sub-millisecond latency at a high-dynamic range and with strong robustness against motion blur. These unique properties offer great potential for low-latency object detection and tracking in time-critical scenarios. Prior work in event-based vision has achieved outstanding detection performance but at the cost of substantial inference time, typically beyond 40 milliseconds. By revisiting the high-level design of recurrent vision backbones, we reduce inference time by a factor of 5 while retaining similar performance. To achieve this, we explore a multi-stage design that utilizes three key concepts in each stage: First, a convolutional prior that can be regarded as a conditional positional embedding. Second, local- and dilated global self-attention for spatial feature interaction. Third, recurrent temporal feature aggregation to minimize latency while retaining temporal information. RVTs can be trained from scratch to reach state-of-the-art performance on event-based object detection - achieving an mAP of 47.2% on the Gen1 automotive dataset. At the same time, RVTs offer fast inference (12 ms on a T4 GPU) and favorable parameter efficiency (5 times fewer than prior art). Our study brings new insights into effective design choices that could be fruitful for research beyond event-based vision.
References
DSEC-Detection Dataset Release

State-of-the-art machine-learning methods for event cameras treat events as dense representations and process them with conventional deep neural networks. Thus, they fail to maintain the sparsity and asynchronous nature of event data, thereby imposing significant computation and latency constraints on downstream systems. A recent line of work tackles this issue by modeling events as spatiotemporally evolving graphs that can be efficiently and asynchronously processed using graph neural networks. These works showed impressive computation reductions, yet their accuracy is still limited by the small scale and shallow depth of their network, both of which are required to reduce computation. In this work, we break this glass ceiling by introducing several architecture choices which allow us to scale the depth and complexity of such models while maintaining low computation. On object detection tasks, our smallest model shows up to 3.7 times lower computation, while outperforming state-of-the-art asynchronous methods by 7.4 mAP. Even when scaling to larger model sizes, we are 13% more efficient than state-of-the-art while outperforming it by 11.5 mAP. As a result, our method runs 3.7 times faster than a dense graph neural network, taking only 8.4 ms per forward pass. This opens the door to efficient, and accurate object detection in edge-case scenarios.
References
Hilti-Oxford Dataset: A Millimetre-Accurate Benchmark for Simultaneous Localization and Mapping

References
Training Efficient Controllers via Analytic Policy Gradient

Control design for robotic systems is complex and often requires solving an optimization to follow a trajectory accurately. Online optimization approaches like Model Predictive Control (MPC) have been shown to achieve great tracking performance, but require high computing power. Conversely, learning-based offline optimization approaches, such as Reinforcement Learning (RL), allow fast and efficient execution on the robot but hardly match the accuracy of MPC in trajectory tracking tasks. In systems with limited compute, such as aerial vehicles, an accurate controller that is efficient at execution time is imperative. We propose an Analytic Policy Gradient (APG) method to tackle this problem. APG exploits the availability of differentiable simulators by training a controller offline with gradient descent on the tracking error. We address training instabilities that frequently occur with APG through curriculum learning and experiment on a widely used controls benchmark, the CartPole, and two common aerial robots, a quadrotor and a fixed-wing drone. Our proposed method outperforms both model-based and model-free RL methods in terms of tracking error. Concurrently, it achieves similar performance to MPC while requiring more than an order of magnitude less computation time. Our work provides insights into the potential of APG as a promising control method for robotics. To facilitate the exploration of APG, we open-source our code and make it publicly available.
References
Tightly-coupled Fusion of Global Positional Measurements in Optimization-based Visual-Inertial Odometry
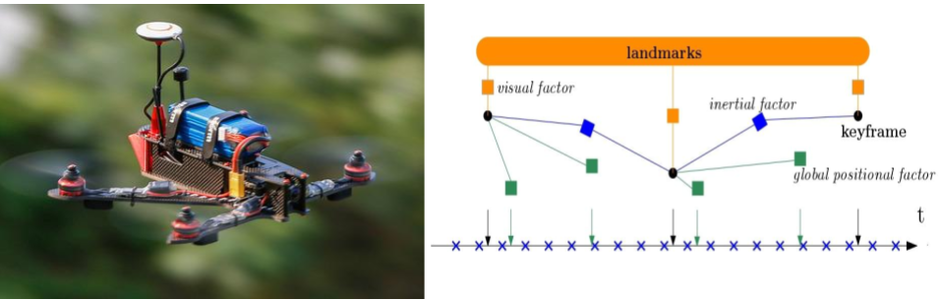
We are excited to release fully open-source our code to tightly fuse global positional measurements in visual-inertial odometry (VIO)! Motivated by the goal of achieving robust, drift-free pose estimation in long-term autonomous navigation, in this work we propose a methodology to fuse global positional information with visual and inertial measurements in a tightly-coupled nonlinear-optimization based estimator. Differently from previous works, which are loosely-coupled, the use of a tightly-coupled approach allows exploiting the correlations amongst all the measurements. A sliding window of the most recent system states is estimated by minimizing a cost function that includes visual re-projection errors, relative inertial errors, and global positional residuals. We use IMU preintegration to formulate the inertial residuals and leverage the outcome of such algorithm to efficiently compute the global position residuals. The experimental results show that the proposed method achieves accurate and globally consistent estimates, with negligible increase of the optimization computational cost. Our method consistently outperforms the loosely-coupled fusion approach. The mean position error is reduced up to 50% with respect to the loosely-coupled approach in outdoor Unmanned Aerial Vehicle (UAV) flights, where the global position information is given by noisy GPS measurements. To the best of our knowledge, this is the first work where global positional measurements are tightly fused in an optimization-based visual-inertial odometry algorithm, leveraging the IMU preintegration method to define the global positional factors.
References

Data-driven Feature Tracking for Event Cameras

Because of their high temporal resolution, increased resilience to motion blur, and very sparse output, event cameras have been shown to be ideal for low-latency and low-bandwidth feature tracking, even in challenging scenarios. Existing feature tracking methods for event cameras are either handcrafted or derived from first principles but require extensive parameter tuning, are sensitive to noise, and do not generalize to different scenarios due to unmodeled effects. To tackle these deficiencies, we introduce the first data-driven feature tracker for event cameras, which leverages low-latency events to track features detected in a grayscale frame. We achieve robust performance via a novel frame attention module, which shares information across feature tracks. By directly transferring zero-shot from synthetic to real data, our data-driven tracker outperforms existing approaches in relative feature age by up to 120 % while also achieving the lowest latency. This performance gap is further increased to 130 % by adapting our tracker to real data with a novel self-supervision strategy.
References
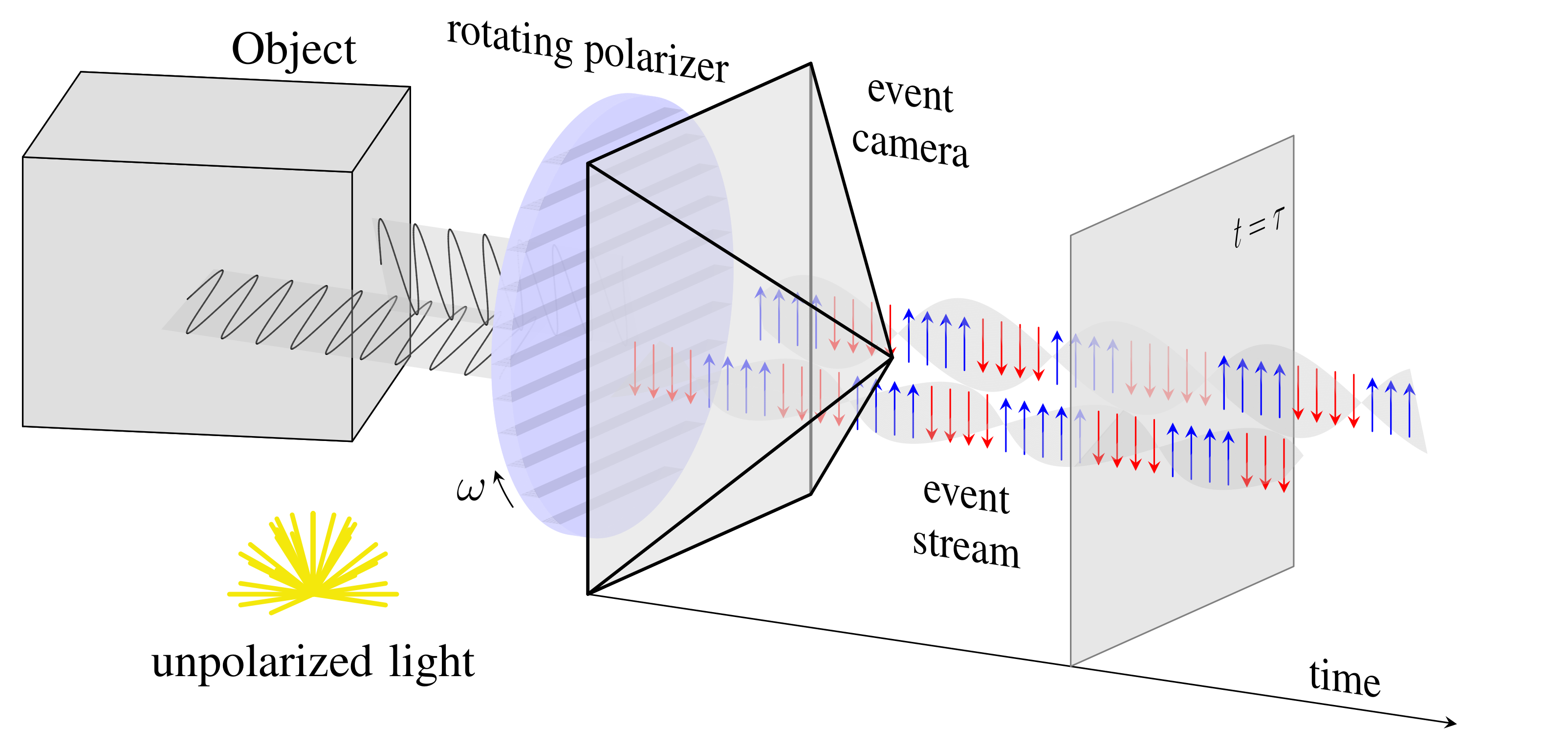
Event-based Shape from Polarization
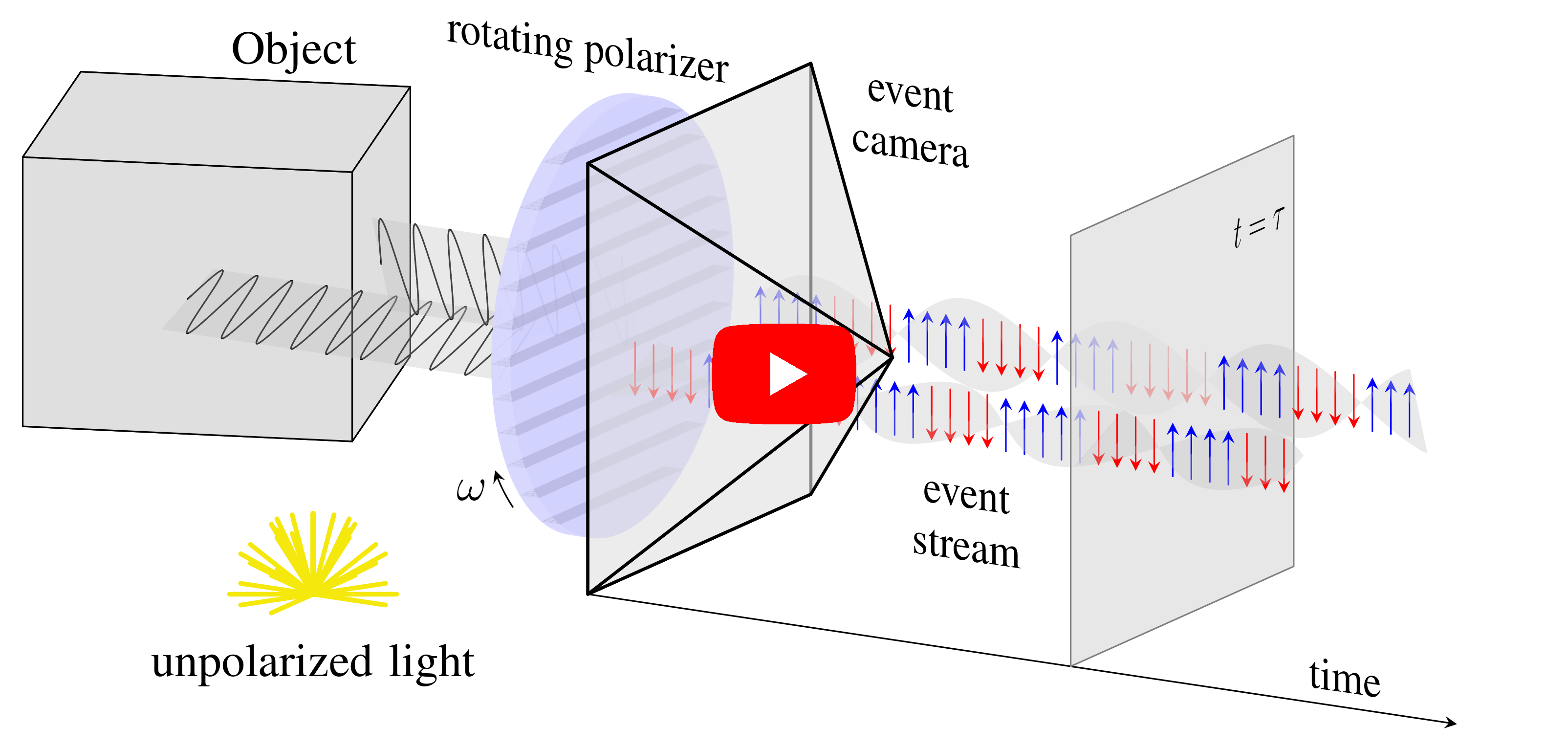
State-of-the-art solutions for Shape-from-Polarization (SfP) suffer from a speed-resolution tradeoff: they either sacrifice the number of polarization angles measured or necessitate lengthy acquisition times due to framerate constraints, thus compromising either accuracy or latency. We tackle this tradeoff using event cameras. Event cameras operate at microseconds resolution with negligible motion blur, and output a continuous stream of events that precisely measures how light changes over time asynchronously. We propose a setup that consists of a linear polarizer rotating at high-speeds in front of an event camera. Our method uses the continuous event stream caused by the rotation to reconstruct relative intensities at multiple polarizer angles. Experiments demonstrate that our method outperforms physics-based baselines using frames, reducing the MAE by 25% in synthetic and real-world dataset. In the real world, we observe, however, that the challenging conditions (i.e., when few events are generated) harm the performance of physics-based solutions. To overcome this, we propose a learning-based approach that learns to estimate surface normals even at low event-rates, improving the physics-based approach by 52% on the real world dataset. The proposed system achieves an acquisition speed equivalent to 50 fps (>twice the framerate of the commercial polarization sensor) while retaining the spatial resolution of 1MP. Our evaluation is based on the first large-scale dataset for event-based SfP.
References
Event-based Shape from Polarization
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
Event-based Agile Object Catching with a Quadrupedal Robot

Quadrupedal robots are conquering various applications in indoor and outdoor environments due to their capability to navigate challenging uneven terrains. Exteroceptive information greatly enhances this capability since perceiving their surroundings allows them to adapt their controller and thus achieve higher levels of robustness. However, sensors such as LiDARs and RGB cameras do not provide sufficient information to quickly and precisely react in a highly dynamic environment since they suffer from a bandwidth-latency tradeoff. They require significant bandwidth at high frame rates while featuring significant perceptual latency at lower frame rates, thereby limiting their versatility on resource constrained platforms. In this work, we tackle this problem by equipping our quadruped with an event camera, which does not suffer from this tradeoff due to its asynchronous and sparse operation. In levering the low latency of the events, we push the limits of quadruped agility and demonstrating high-speed ball catching with a net for the first time. We show that our quadruped equipped with an event-camera can catch objects at maximum speeds of 15 m/s from 4 meters, with a success rate of 83%. With a VGA event camera, our method runs at 100 Hz on an NVIDIA Jetson Orin.
References

Learned Inertial Odometry for Autonomous Drone Racing

Inertial odometry is an attractive solution to the problem of state estimation for agile quadrotor flight. It is inexpensive, lightweight, and it is not affected by perceptual degradation. However, only relying on the integration of the inertial measurements for state estimation is infeasible. The errors and time-varying biases present in such measurements cause the accumulation of large drift in the pose estimates. Recently, inertial odometry has made significant progress in estimating the motion of pedestrians. State-of-the-art algorithms rely on learning a motion prior that is typical of humans but cannot be transferred to drones. In this work, we propose a learning-based odometry algorithm that uses an inertial measurement unit (IMU) as the only sensor modality for autonomous drone racing tasks. The core idea of our system is to couple a model-based filter, driven by the inertial measurements, with a learning-based module that has access to the thrust measurements. We show that our inertial odometry algorithm is superior to the state-of-the-art filter-based and optimization-based visual-inertial odometry as well as the state-of-the-art learned-inertial odometry in estimating the pose of an autonomous racing drone. Additionally, we show that our system is comparable to a visual-inertial odometry solution that uses a camera and exploits the known gate location and appearance. We believe that the application in autonomous drone racing paves the way for novel research in inertial odometry for agile quadrotor flight. We release the code open-source.
References
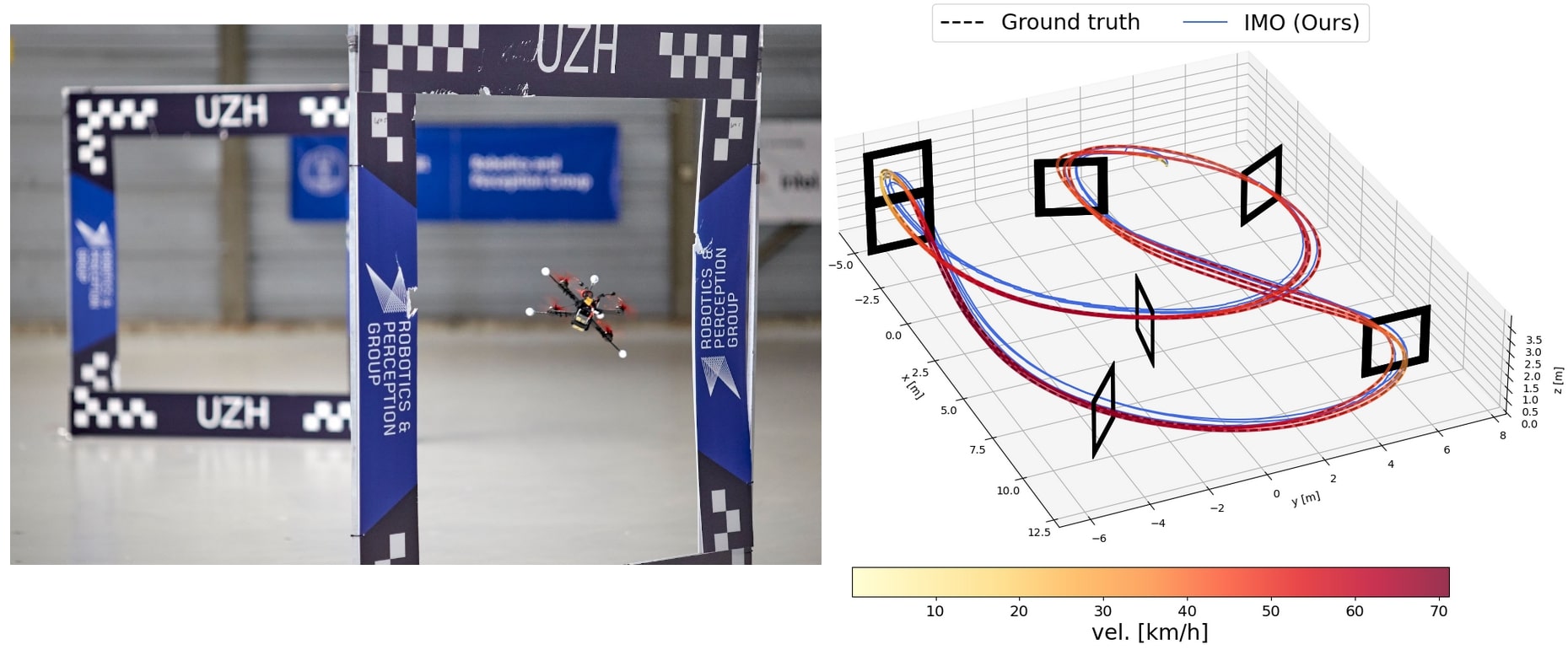
Learned Inertial Odometry for Autonomous Drone Racing
IEEE Robotics and Automation Letters (RA-L), 2023.
Agilicious: Open-Source and Open-Hardware Agile Quadrotor for Vision-Based Flight

We are excited to present Agilicious, a co-designed hardware and software framework tailored to autonomous, agile quadrotor flight. It is completely open-source and open-hardware and supports both model-based and neural-network-based controllers. Also, it provides high thrust-to-weight and torque-to-inertia ratios for agility, onboard vision sensors, GPU-accelerated compute hardware for real-time perception and neural-network inference, a real-time flight controller, and a versatile software stack. In contrast to existing frameworks, Agilicious offers a unique combination of flexible software stack and high-performance hardware. We compare Agilicious with prior works and demonstrate it on different agile tasks, using both modelbased and neural-network-based controllers. Our demonstrators include trajectory tracking at up to 5 g and 70 km/h in a motion-capture system, and vision-based acrobatic flight and obstacle avoidance in both structured and unstructured environments using solely onboard perception. Finally, we demonstrate its use for hardware-in-the-loop simulation in virtual-reality environments. Thanks to its versatility, we believe that Agilicious supports the next generation of scientific and industrial quadrotor research. For more details check our paper, video and webpage.
References
Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Cars

Event cameras are bio-inspired vision sensors that naturally capture the dynamics of a scene, filtering out redundant information. This paper presents a deep neural network approach that unlocks the potential of event cameras on a challenging motion-estimation task: prediction of a vehicle's steering angle. To make the best out of this sensor-algorithm combination, we adapt state-of-the-art convolutional architectures to the output of event sensors and extensively evaluate the performance of our approach on a publicly available large scale event-camera dataset (~1000 km). We present qualitative and quantitative explanations of why event cameras allow robust steering prediction even in cases where traditional cameras fail, e.g. challenging illumination conditions and fast motion. Finally, we demonstrate the advantages of leveraging transfer learning from traditional to event-based vision, and show that our approach outperforms state-of-the-art algorithms based on standard cameras.
References
Data-Efficient Collaborative Decentralized Thermal-Inertial Odometry
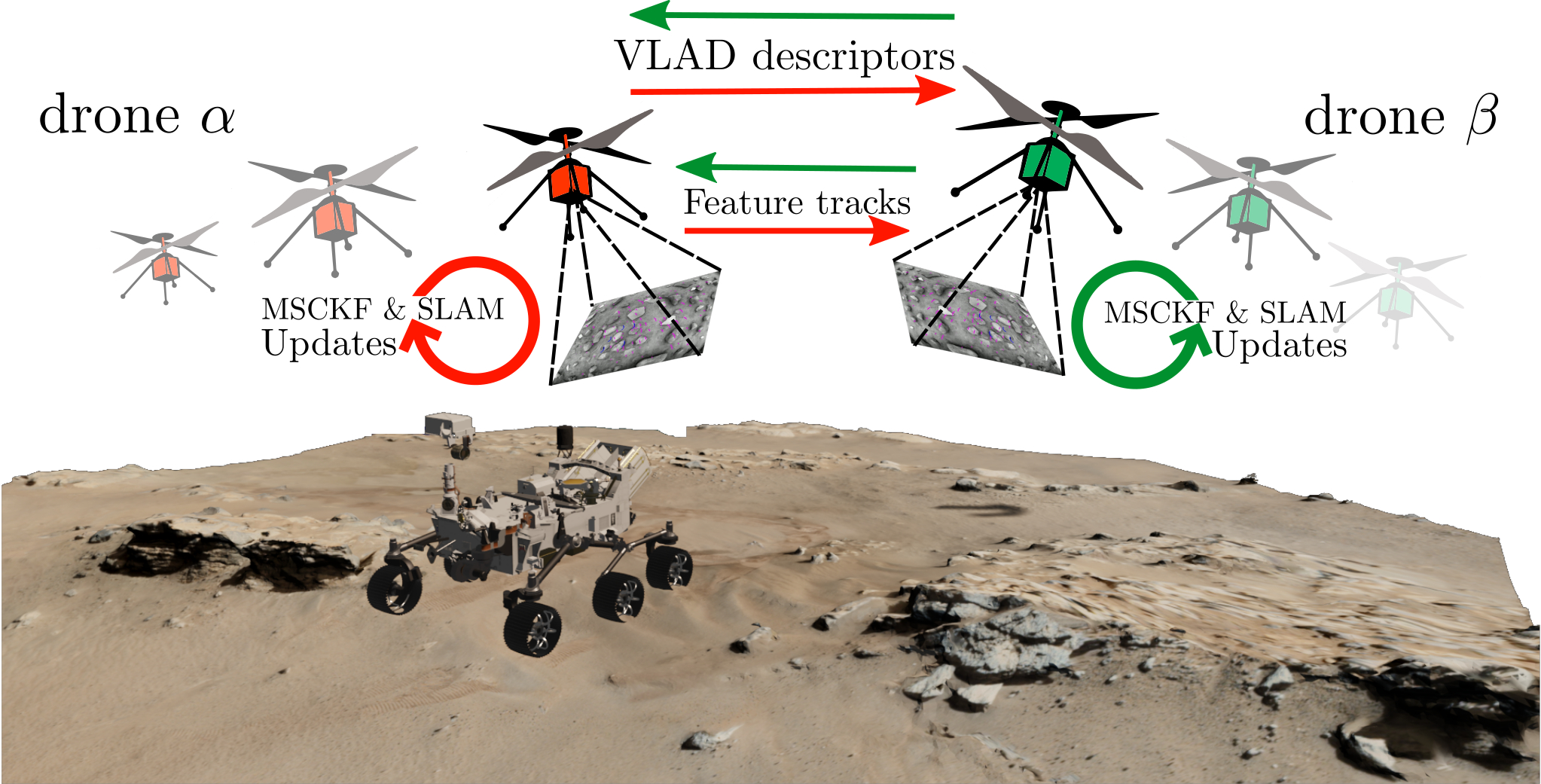
We propose a system solution to achieve data-efficient, decentralized state estimation for a team of flying robots using thermal images and inertial measurements. Each robot can fly independently, and exchange data when possible to refine its state estimate. Our system front-end applies an online photometric calibration to refine the thermal images so as to enhance feature tracking and place recognition. Our system back-end uses a covariance intersection fusion strategy to neglect the cross-correlation between agents so as to lower memory usage and computational cost. The communication pipeline uses Vector of Locally Aggregated Descriptors (VLAD) to construct a request-response policy that requires low bandwidth usage. We test our collaborative method on both synthetic and real-world data. Our results show that the proposed method improves by up to 46% trajectory estimation with respect to an individual-agent approach, while reducing up to 89% the communication exchange. Datasets and code are released to the public, extending the already-public JPL xVIO library.
References

Data-Efficient Collaborative Decentralized Thermal-Inertial Odometry
IEEE Robotics and Automation Letters (RA-L), 2022
The Hilti SLAM Challenge Dataset

We release the Hilti SLAM Challenge Dataset! The sensor platform used to collect this dataset contains a number of visual, lidar and inertial sensors which have all been rigorously calibrated. All data is temporally aligned to support precise multi-sensor fusion. Each dataset includes accurate ground truth to allow direct testing of SLAM results. Raw data as well as intrinsic and extrinsic sensor calibration data from twelve datasets in various environments is provided. Each environment represents common scenarios found in building construction sites in various stages of completion. For more details, check out our paper.
References
ESS: Learning Event-based Semantic Segmentation from Still Images
References
Exploring Event Camera-based Odometry for Planetary Robots
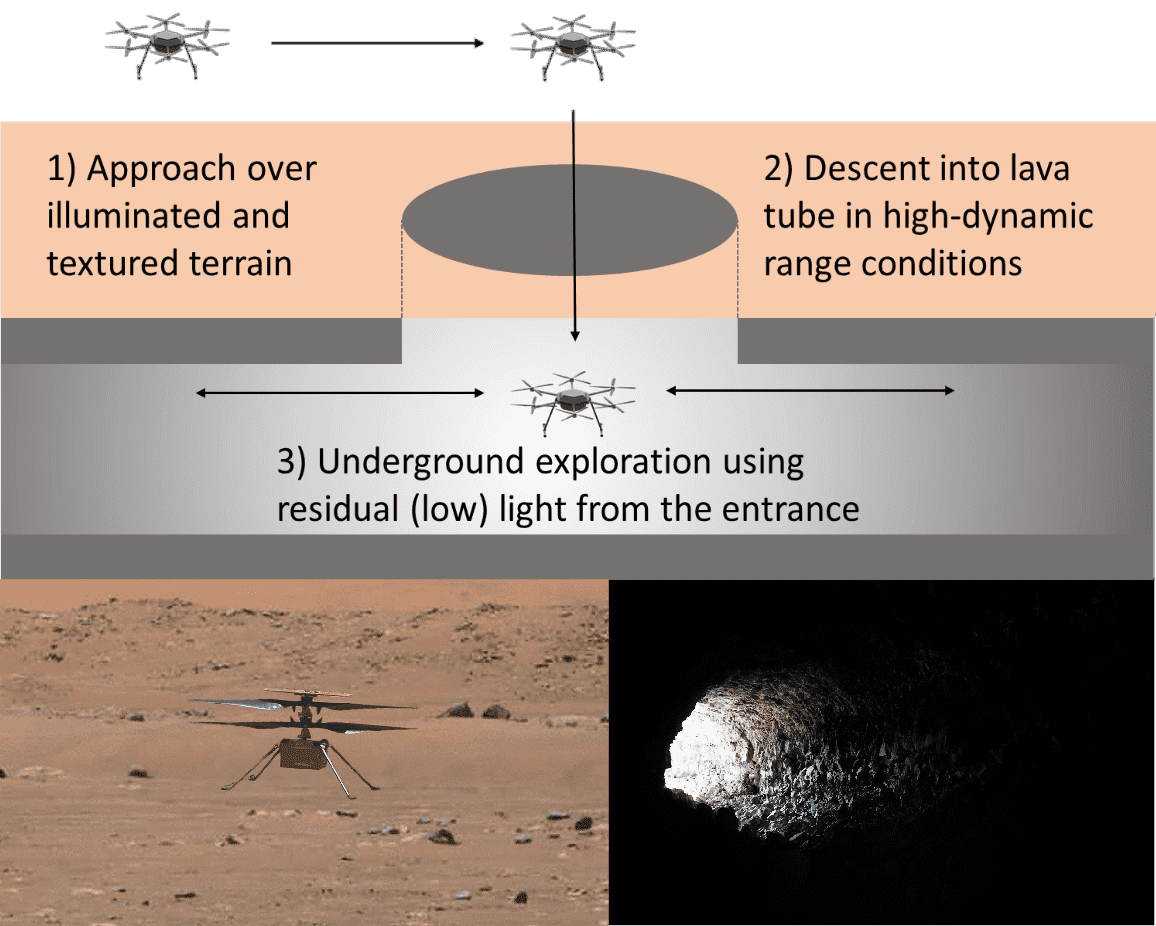
References
Exploring Event Camera-based Odometry for Planetary Robots
Robotics and Automation Letters (RAL), 2022
Ultimate SLAM? Combining Events, Images, and IMU for Robust Visual SLAM in HDR and High Speed Scenarios
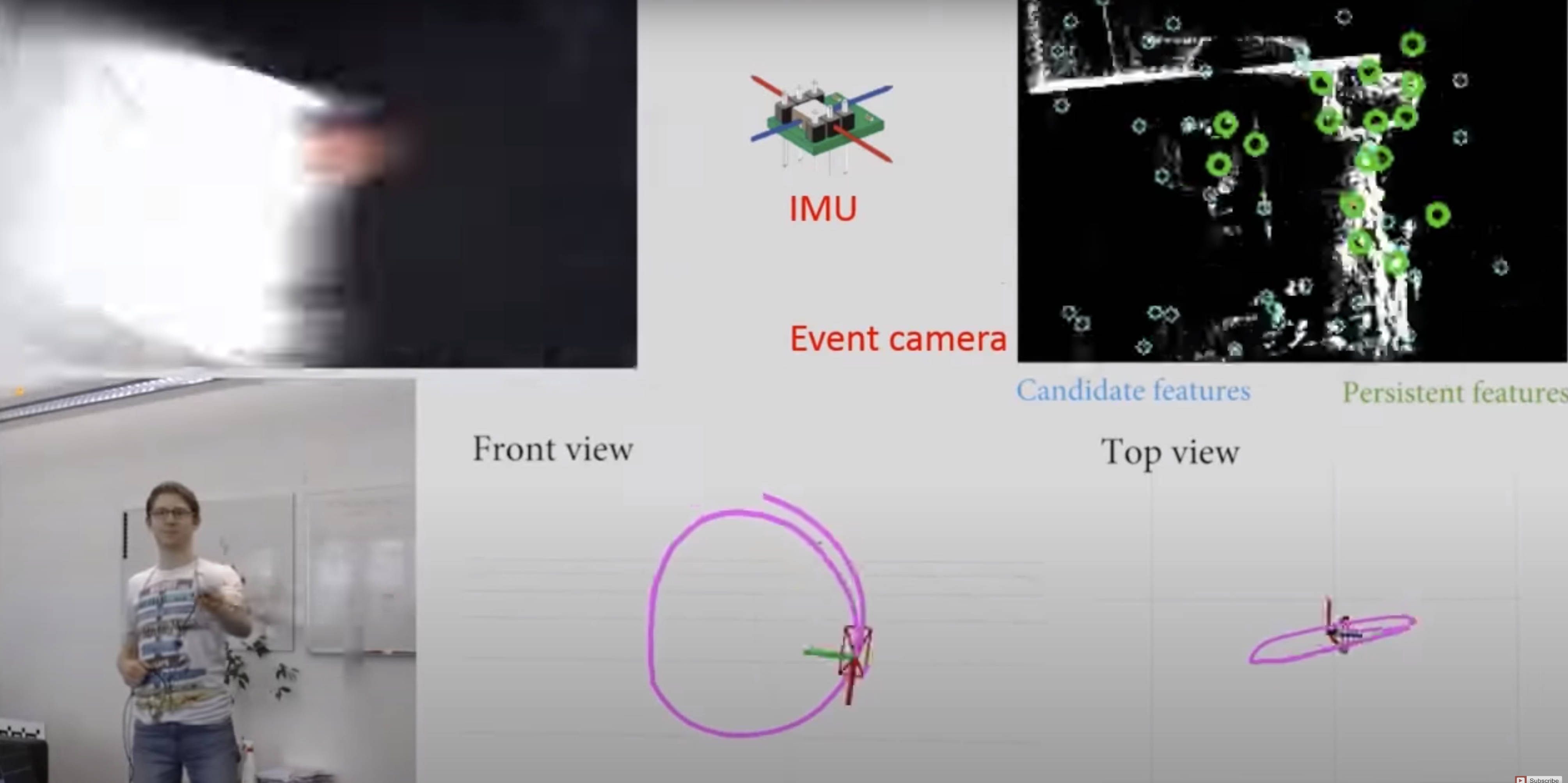
In this paper, we present the first state estimation pipeline that leverages the complementary advantages of a standard camera with an event camera by fusing in a tightly-coupled manner events, standard frames, and inertial measurements. We show on the Event Camera Dataset that our hybrid pipeline leads to an accuracy improvement of 130% over event-only pipelines, and 85% over standard-frames only visual-inertial systems, while still being computationally tractable.
Furthermore, we use our pipeline to demonstrate - to the best of our knowledge - the first autonomous quadrotor flight using an event camera for state estimation, unlocking flight scenarios that were not reachable with traditional visual inertial odometry, such as low-light environments and high dynamic range scenes.
References

Ultimate SLAM? Combining Events, Images, and IMU for Robust Visual SLAM in HDR and High Speed Scenarios
IEEE Robotics and Automation Letters (RA-L), 2018.
PDF YouTube ICRA18 Video Pitch Poster Results (raw trajectories) Project Webpage Source Code
Event-aided Direct Sparse Odometry

We introduce EDS, a direct monocular visual odometry using events and frames. Our algorithm leverages the event generation model to track the camera motion in the blind time between frames. The method formulates a direct probabilistic approach of observed brightness increments. Per-pixel brightness increments are predicted using a sparse number of selected 3D points and are compared to the events via the brightness increment error to estimate camera motion. The method recovers a semi-dense 3D map using photometric bundle adjustment. EDS is the first method to perform 6-DOF VO using events and frames with a direct approach. By design it overcomes the problem of changing appearance in indirect methods. We also show that, for a target error performance, EDS can work at lower frame rates than state-of-the-art frame-based VO solutions. This opens the door to low-power motion-tracking applications where frames are sparingly triggered "on demand'' and our method tracks the motion in between. We release code and datasets to the public.
References
Time Lens++: Event-based Frame Interpolation with Parametric Non-linear Flow and Multi-scale Fusion

References
Time Lens++: Event-based Frame Interpolation with Parametric Non-linear Flow and Multi-scale Fusion
IEEE Conference of Computer Vision and Pattern Recognition (CVPR), 2022, New Orleans, USA.
AEGNN: Asynchronous Event-based Graph Neural Networks

References

AEGNN: Asynchronous Event-based Graph Neural Networks
IEEE Conference of Computer Vision and Pattern Recognition (CVPR), 2022, New Orleans, USA.
Visual Attention Prediction Improves Performance of Autonomous Drone Racing Agents

Humans race drones faster than neural networks trained for end-to-end autonomous flight. This may be related to the ability of human pilots to select task-relevant visual information effectively. This work investigates whether neural networks capable of imitating human eye gaze behavior and attention can improve neural network performance for the challenging task of vision-based autonomous drone racing. We hypothesize that gaze-based attention prediction can be an efficient mechanism for visual information selection and decision making in a simulator-based drone racing task. We test this hypothesis using eye gaze and flight trajectory data from 18 human drone pilots to train a visual attention prediction model. We then use this visual attention prediction model to train an end-to-end controller for vision-based autonomous drone racing using imitation learning. We compare the drone racing performance of the attention-prediction controller to those using raw image inputs and image-based abstractions (i.e., feature tracks). Comparing success rates for completing a challenging race track by autonomous flight, our results show that the attention-prediction based controller (88% success rate) outperforms the RGB-image (61% success rate) and feature-tracks (55% success rate) controller baselines. Furthermore, visual attention-prediction and feature-track based models showed better generalization performance than image-based models when evaluated on hold-out reference trajectories. Our results demonstrate that human visual attention prediction improves the performance of autonomous vision-based drone racing agents and provides an essential step towards vision-based, fast, and agile autonomous flight that eventually can reach and even exceed human performances.
References
Minimum-Time Quadrotor Waypoint Flight in Cluttered Environments

Planning minimum-time trajectories in cluttered environments with obstacles is a challenging problem. The quadrotor has to fly on the edge of its capabilities and, at the same time, avoid obstacles. However, planning such trajectories is vital for applications like search and rescue, where after disasters, it is essential to search for survivors as quickly as possible. Nevertheless, planning minimum-time trajectories in cluttered environments has not been addressed before in its entirety, using the full quadrotor model that can leverage the full actuation of the platform. We address this problem by using a hierarchical, sampling-based method with an incrementally more complex quadrotor model. The proposed method outperforms all related baselines in cluttered environments and is further validated in real-world flights at over 60km/h.
References
Continuous-Time vs. Discrete-Time Vision-based SLAM: A Comparative Study
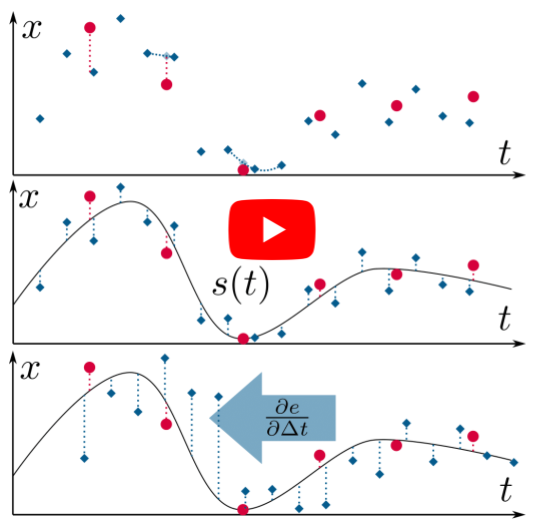
References
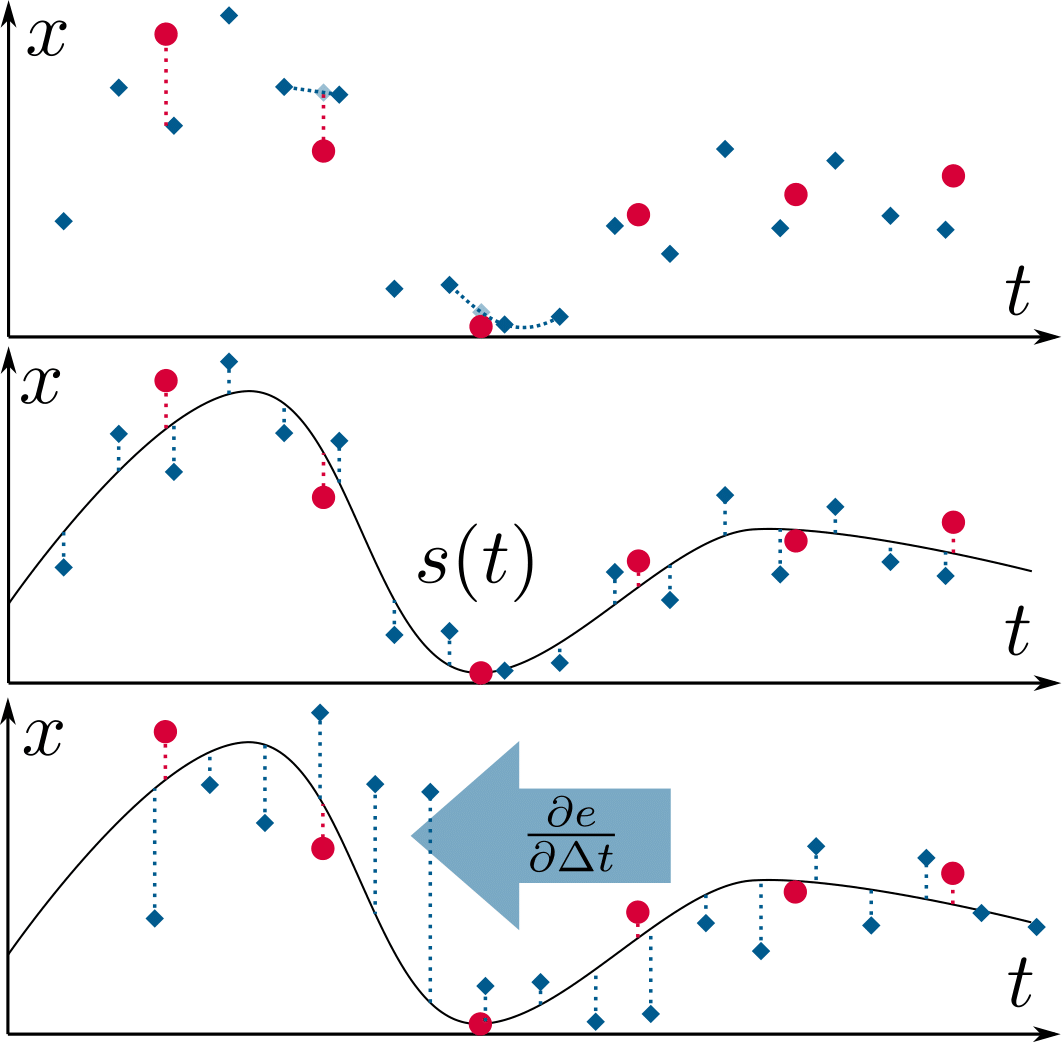
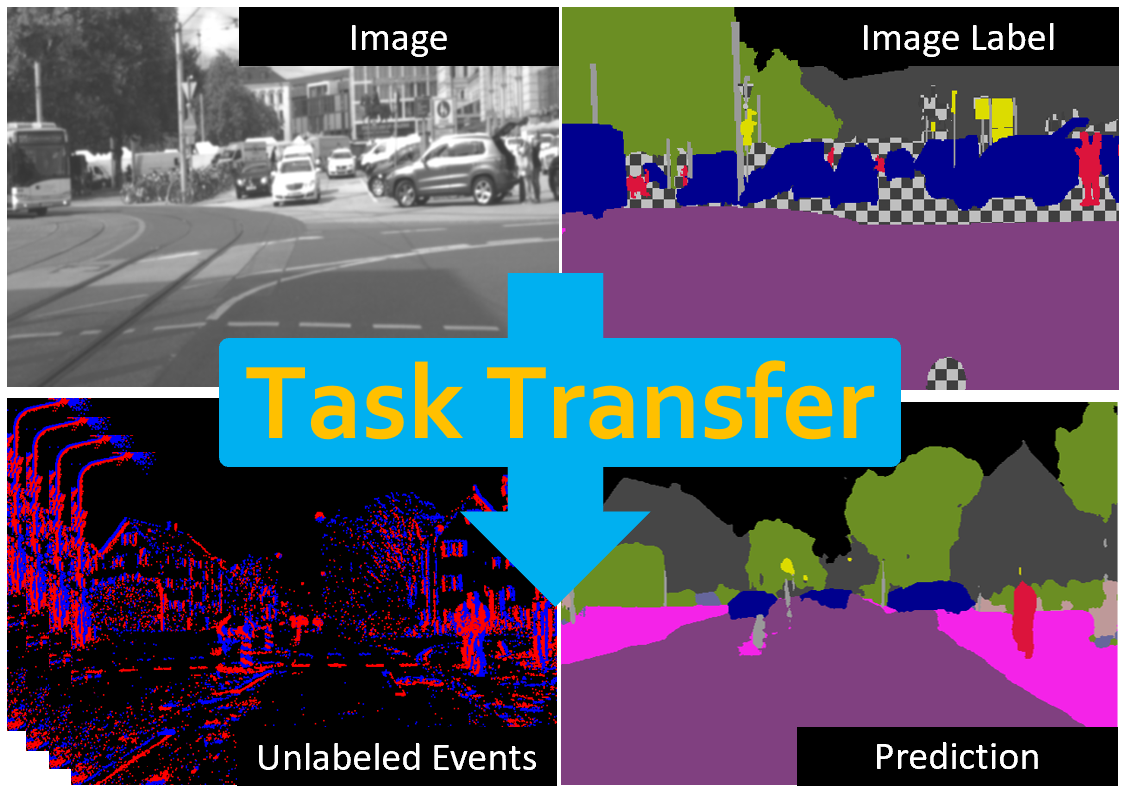
Bridging the Gap between Events and Frames through Unsupervised Domain Adaptation

Event cameras are novel sensors with outstanding properties such as high temporal resolution and high dynamic range. Despite these characteristics, event-based vision has been held back by the shortage of labeled datasets due to the novelty of event cameras. To overcome this drawback, we propose a task transfer method that allows models to be trained directly with labeled images and unlabeled event data. Compared to previous approaches, (i) our method transfers from single images to events instead of high frame rate videos, and (ii) does not rely on paired sensor data. To achieve this, we leverage the generative event model to split event features into content and motion features. This feature split enables to efficiently match the latent space for events and images, which is crucial for a successful task transfer. Thus, our approach unlocks the vast amount of existing image datasets for the training of event-based neural networks. Our task transfer method consistently outperforms methods applicable in the Unsupervised Domain Adaptation setting for object detection by 0.26 mAP (increase by 93%) and classification by 2.7% accuracy.
References
Perception-Aware Perching on Powerlines with Multirotors

Multirotor aerial robots are becoming widely used for the inspection of powerlines. To enable continuous, robust inspection without human intervention, the robots must be able to perch on the powerlines to recharge their batteries. Highly versatile perching capabilities are necessary to adapt to the variety of configurations and constraints that are present in real powerline systems. This paper presents a novel perching trajectory generation framework that computes perception-aware, collision-free, and dynamically-feasible maneuvers to guide the robot to the desired final state. Trajectory generation is achieved via solving a Nonlinear Programming problem using the Primal-Dual Interior Point method. The problem considers the full dynamic model of the robot down to its single rotor thrusts and minimizes the final pose and velocity errors while avoiding collisions and maximizing the visibility of the powerline during the maneuver. The generated maneuvers consider both the perching and the posterior recovery trajectories. The framework adopts costs and constraints defined by efficient mathematical representations of powerlines, enabling online onboard execution in resource-constrained hardware. The method is validated on-board an agile quadrotor conducting powerline inspection and various perching maneuvers with final pitch values of up to 180 degrees.
References
Policy Search for Model Predictive Control with Application to Agile Drone Flight
Policy Search and Model Predictive Control (MPC) are two different paradigms for robot control: policy search has the strength of automatically learning complex policies using experienced data, while MPC can offer optimal control performance using models and trajectory optimization. An open research question is how to leverage and combine the advantages of both approaches. In this work, we provide an answer by using policy search for automatically choosing high-level decision variables for MPC, which leads to a novel policy-search-for-model-predictive-control framework. Specifically, we formulate the MPC as a parameterized controller, where the hard-to-optimize decision variables are represented as high-level policies. Such a formulation allows optimizing policies in a self-supervised fashion. We validate this framework by focusing on a challenging problem in agile drone flight: flying a quadrotor through fast-moving gates. Experiments show that our controller achieves robust and real-time control performance in both simulation and the real world. The proposed framework offers a new perspective for merging learning and control.
References

Policy Search for Model Predictive Control with Application to Agile Drone Flight
IEEE Transactions on Robotics (T-RO), 2022.
SVO Pro

We are excited to release fully open source SVO Pro! SVO Pro is the latest version of SVO developed over the past few years in our lab. SVO Pro features the support of different camera models, active exposure control, a sliding window based backend, and global bundle adjustment with loop closure. Check out the project page and the code on github!
References

ESL: Event-based Structured Light
References

ESL: Event-based Structured Light
International Conference on 3D Vision (3DV), 2021.
E-RAFT: Dense Optical Flow from Event Cameras

We propose to incorporate feature correlation and sequential processing into dense optical flow estimation from event cameras. Modern frame-based optical flow methods heavily rely on matching costs computed from feature correlation. In contrast, there exists no optical flow method for event cameras that explicitly computes matching costs. Instead, learning-based approaches using events usually resort to the U-Net architecture to estimate optical flow sparsely. Our key finding is that introducing correlation features significantly improves results compared to previous methods that solely rely on convolution layers. Compared to the state-of-the-art, our proposed approach computes dense optical flow and reduces the end-point error by 23% on MVSEC. Furthermore, we show that all existing optical flow methods developed so far for event cameras have been evaluated on datasets with very small displacement fields with a maximum flow magnitude of 10 pixels. We introduce a new real-world dataset that exhibits displacement fields with magnitudes up to 210 pixels and 3 times higher camera resolution based on this observation. Our proposed approach reduces the end-point error on this dataset by 66%.
References

Learning High-Speed Flight in the Wild

This is the algorithm presented in our Science Robotics paper Learning High-Speed Flight in the Wild. Check out the code here. The code allows you to train end-to-end navigation policies to fly drones in previously unknown, challenging environments (snowy terrains, derailed trains, ruins, thick vegetation, and collapsed buildings), with only onboard sensing and computation. For more details, check out our paper.
References

Learning High-Speed Flight in the Wild
Science Robotics, 2021.
Time-Optimal Planning for Quadrotor Waypoint Flight

This is the planning algorithm presented in our Science Robotics paper Time-Optimal Planning for Quadrotor Waypoint Flight. Check out the code here, it comes with a simple example! This is the first method to allow planning time-optimal trajectories at the boundary of the performance envelope, correctly accounting for the single rotor limits of a quadrotor vehicle. For more details, check out our paper.
References
Powerline Tracking with Event Cameras

We release the event-based line tracker algorithm from our IROS paper Powerline Tracking with Event Cameras. Check out the code here! Our algorithm identifies lines in the stream of events by detecting planes in the spatio-temporal signal, and tracks them throughtime. The implementation runs onboard resource constrained quadrotors and is capable of detecting multiple distinct lines in real time with rates of up to 320 thousand events per second. The tracker is able to persistently track the powerlines, with a mean lifetime of the line 10x longer than existing approaches. For more details, check out our paper.
References
EVO: Event-based, 6-DOF Parallel Tracking and Mapping in Real-Time
We release EVO, an Event-based Visual Odometry algorithm from our RA-L paper EVO: Event-based, 6-DOF Parallel Tracking and Mapping in Real-Time. The code is implemented in C++ and runs in real-time on a laptop. Try it out for yourself on GitHub! Our algorithm successfully leverages the outstanding properties of event cameras to track fast camera motions while recovering a semi-dense 3D map of the environment. The implementation outputs up to several hundred pose estimates per second. Due to the nature of event cameras, our algorithm is unaffected by motion blur and operates very well in challenging, high dynamic range conditions with strong illumination changes.
References
NeuroBEM: Hybrid Aerodynamic Quadrotor Model
We release the full dataset associated with our upcoming RSS paper NeuroBEM: Hybrid Aerodynamic Quadrotor Model. The dataset features over 1h15min of highly aggressive maneuvers recorded at high accuracy in one of the worlds largest optical tracking volumes. We provide time-aligned quadrotor state and motor-commands recorded at 400Hz in a curated dataset. For more details, check out our paper and dataset.
References

GPU-Accelerated Frontend for High-Speed VIO now as ROS node

The recent introduction of powerful embedded GPUs has enabled algorithms to run well above the standard video rates, yielding higher information processing capability and reduced latency. This code introduces an enhanced FAST feature detector that applies a GPU-specific non-maxima suppression, imposes spatial feature distribution and extracts features simultaneously. It comes as a ROS node, runs on most modern NVIDIA CUDA-capable GPUS, but is further specialized with the Jetson TX2 platform in mind, on which it performs more than 1000fps throughput.
References

Faster than FAST: GPU-Accelerated Frontend for High-Speed VIO
IEEE International Conference on Intelligent Robots and Systems, 2020.
TimeLens: Event-based Video Frame Interpolation

References

TimeLens: Event-based Video Frame Interpolation
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, 2021.
How to Calibrate Your Event Camera

References
AutoTune: Controller Tuning for High-Speed Flight

The following code allows you to automatically tune your controller on the task of high speed flight, where our approach obtains superior performance than the state of the art. In contrast to previous work, our algorithm does not assume any prior knowledge of the drone or of the optimization function and can deal with the multi-modal characteristics of the parameters' optimization space.
We propose AutoTune, a sampling method based on Metropolis-Hasting sampling that can tune controller to fly faster than ever before. Among others, AutoTune improves tracking error when flying a physical platform with respect to parameters tuned by a human expert.
References
DSEC: A Stereo Event Camera Dataset for Driving Scenarios

References

DSEC: A Stereo Event Camera Dataset for Driving Scenarios
IEEE Robotics and Automation Letters (RA-L), 2021.
PDF Project Page and Dataset Code Teaser ICRA 2021 Video Pitch Slides
Human-Piloted Drone Racing: Visual Processing and Control

Humans race drones faster than algorithms, despite being limited to a fixed camera angle, body rate control, and response latencies in the order of hundreds of milliseconds. A better understanding of the ability of human pilots of selecting appropriate motor commands from highly dynamic visual information may provide key insights for solving current challenges in vision-based autonomous navigation. This paper investigates the relationship between human eye movements, control behavior, and flight performance in a drone racing task. We collected a multimodal dataset from 21 experienced drone pilots using a highly realistic drone racing simulator, also used to recruit professional pilots. Our results show task-specific improvements in drone racing performance over time. In particular, we found that eye gaze tracks future waypoints (i.e., gates), with first fixations occurring on average 1.5 seconds and 16 meters before reaching the gate. Moreover, human pilots consistently looked at the inside of the future flight path for lateral (i.e., left and right turns) and vertical maneuvers (i.e., ascending and descending). Finally, we found a strong correlation between pilots eye movements and the commanded direction of quadrotor flight, with an average visual-motor response latency of 220 ms. These results highlight the importance of coordinated eye movements in human-piloted drone racing. We make our dataset publicly available.
References
ESIM: an Open Event Camera Simulator now with GPU support!
Event cameras are revolutionary sensors that work radically differently from standard cameras. Instead of capturing intensity images at a fixed rate, event cameras measure changes of intensity asynchronously, in the form of a stream of events, which encode per-pixel brightness changes. In the last few years, their outstanding properties (asynchronous sensing, no motion blur, high dynamic range) have led to exciting vision applications, with very low-latency and high robustness.
We present ESIM: an efficient event camera simulator implemented in C++ and available open source now with additional python bindings and GPU support! ESIM can simulate arbitrary camera motion in 3D scenes, while providing events, standard images, inertial measurements, with full ground truth information including camera pose, velocity, as well as depth and optical flow maps.
References

ESIM: an Open Event Camera Simulator
Conference on Robot Learning (CoRL), Zurich, 2018.
Combining Events and Frames using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction
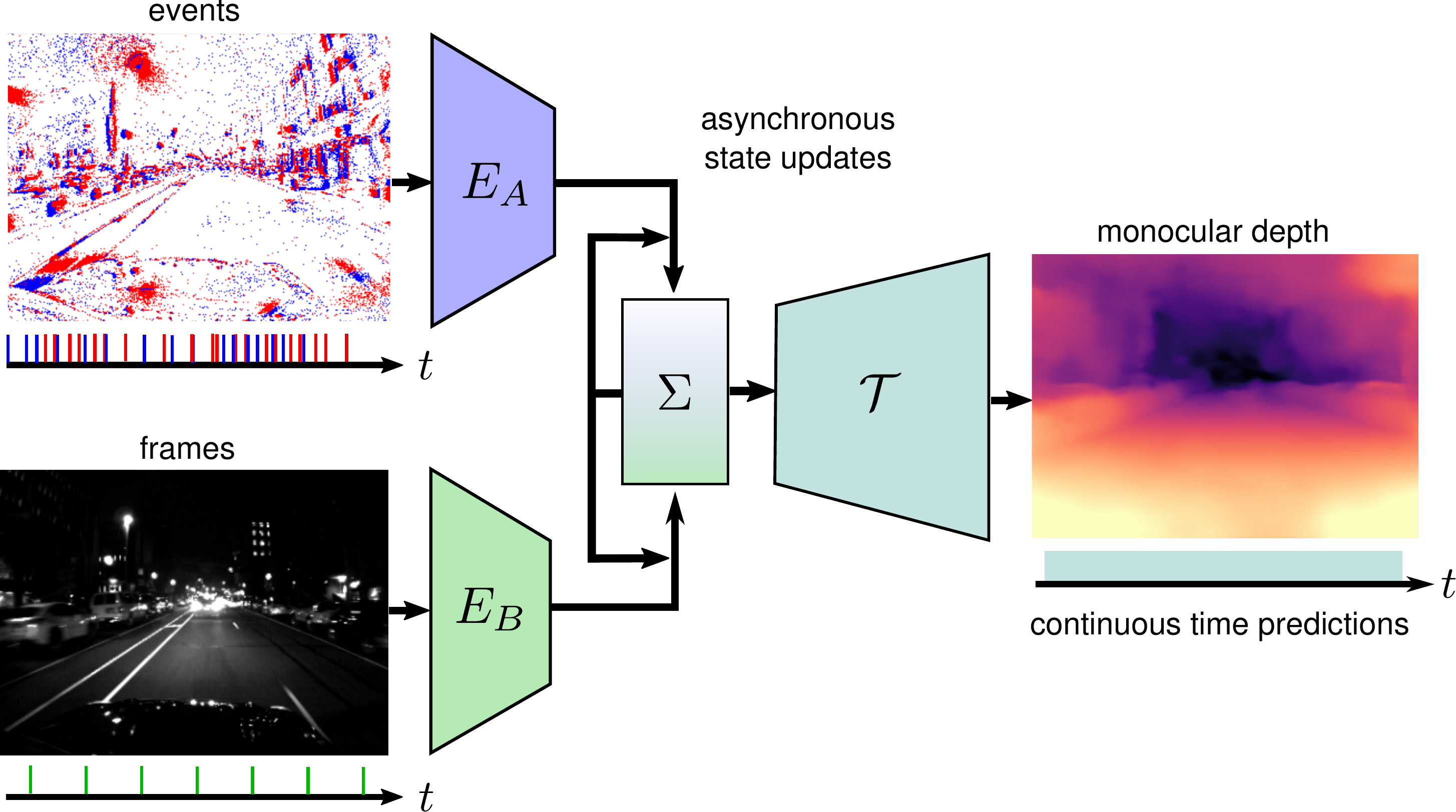
Event cameras are novel vision sensors that report per-pixel brightness changes as a stream of asynchronous "events". They offer significant advantages compared to standard cameras due to their high temporal resolution, high dynamic range and lack of motion blur. However, events only measure the varying component of the visual signal, which limits their ability to encode scene context. By contrast, standard cameras measure absolute intensity frames, which capture a much richer representation of the scene. Both sensors are thus complementary. However, due to the asynchronous nature of events, combining them with synchronous images remains challenging, especially for learning-based methods. This is because traditional recurrent neural networks (RNNs) are not designed for asynchronous and irregular data from additional sensors. To address this challenge, we introduce Recurrent Asynchronous Multimodal (RAM) networks, which generalize traditional RNNs to handle asynchronous and irregular data from multiple sensors. Inspired by traditional RNNs, RAM networks maintain a hidden state that is updated asynchronously and can be queried at any time to generate a prediction. We apply this novel architecture to monocular depth estimation with events and frames where we show an improvement over state-of-the-art methods by up to 30\% in terms of mean absolute depth error. To enable further research on multimodal learning with events, we release EventScape, a new dataset with events, intensity frames, semantic labels, and depth maps recorded in the CARLA simulator.
References
Combining Events and Frames using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction
IEEE Robotics and Automation Letters (RA-L), 2021.
Data-Driven MPC for Quadrotors

Aerodynamic forces render accurate high-speed trajectory tracking with quadrotors extremely challenging. These complex aerodynamic effects become a significant disturbance at high speeds, introducing large positional tracking errors, and are extremely difficult to model. To fly at high speeds, feedback control must be able to account for these aerodynamic effects in real-time. This necessitates a modelling procedure that is both accurate and efficient to evaluate. Therefore, we present an approach to model aerodynamic effects using Gaussian Processes, which we incorporate into a Model Predictive Controller to achieve efficient and precise real-time feedback control, leading to up to 70% reduction in trajectory tracking error at high speeds. We verify our method by extensive comparison to a state-of-the-art linear drag model in synthetic and real-world experiments at speeds of up to 14m/s and accelerations beyond 4g.
References
Autonomous Quadrotor Flight despite Rotor Failure with Onboard Vision Sensors
You can check out our source code of a fault-tolerant flight controller to control a quadrotor after motor failure, using the nonlinear dynamic inversion approach. You can test our control algorithm in a simulator or real flights. The source code includes a vision-based state estimator for pose estimate, despite the quadrotor fast spins at over 20 rad/s. We also release data logged from an onboard camera together with the IMU measurements.
References

Autonomous Quadrotor Flight despite Rotor Failure with Onboard Vision Sensors: Frames vs.
Events
and View Synthesis
IEEE Robotics and Automation Letters (RA-L), 2021.
Reference Pose Verification and Generation for Visual Localization
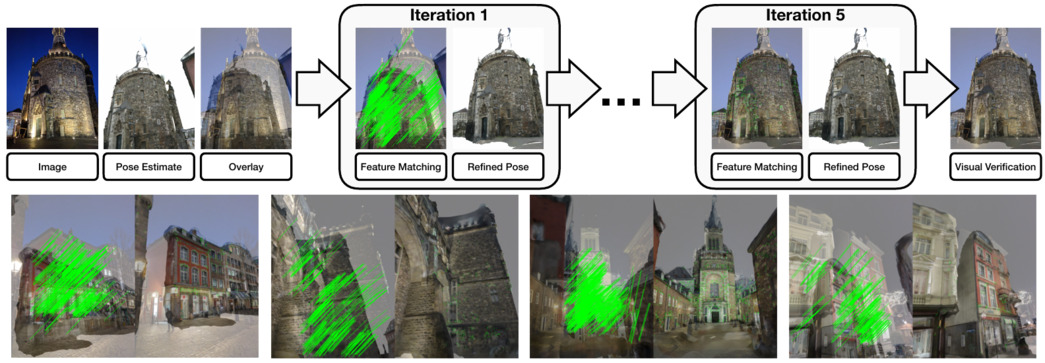
High quality datasets with accurate 6 Degree-of-Freedom (DoF) reference poses are the foundation for benchmarking and improving existing visual localization methods. While it is not a trivial task (e.g., images may be taken under drastically different conditions), there is little work focusing on the generation of reference poses. By making use of learned local features and view synthesis, we propose a framework to verify/refine the reference poses of existing datasets and generate new reference poses. Using our framework, we greatly improve the reference pose accuracy of the popular Aachen Day-Night dataset and extend the dataset with new nighttime imags. The new dataset, namely the Aachen Day-Night v1.1 dataset, has been integrated into the online visual localization benchmarking service
Aachen Day-Night dataset v1.1 on the Visual Localization Benchmark
References

Reference Pose Generation for Long-term Visual Localization via Learned Features
and View Synthesis
International Journal of Computer Vision (IJCV), 2020.
Reducing the Sim-to-Real Gap for Event Cameras

Event cameras are paradigm-shifting novel sensors that report asynchronous, per-pixel brightness changes called events with unparalleled low latency. This makes them ideal for high speed, high dynamic range scenes where conventional cameras would fail. Recent work has demonstrated impressive results using Convolutional Neural Networks (CNNs) for video reconstruction and optic flow with events. We present strategies for improving training data for event based CNNs that result in 20-40% boost in performance of existing state-of-the-art (SOTA) video reconstruction networks retrained with our method, and up to 15% for optic flow networks. A challenge in evaluating event based video reconstruction is lack of quality ground truth images in existing datasets. To address this, we present a new High Quality Frames (HQF) dataset, containing events and ground truth frames from a DAVIS240C that are well-exposed and minimally motion-blurred. We evaluate our method onHQF + several existing major event camera datasets.
References

Reducing the Sim-to-Real Gap for Event Cameras
European Conference on Computer Vision (ECCV), Glasgow, 2020.
Fast Image Reconstruction with an Event Camera
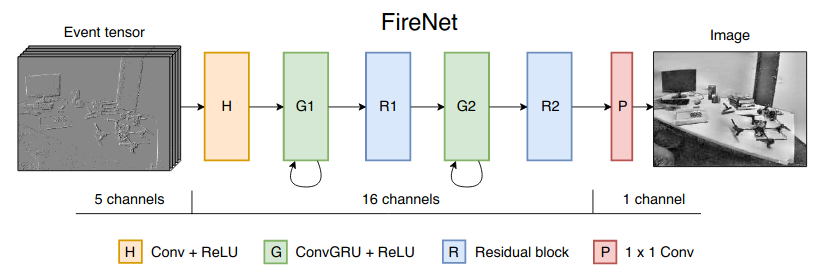
Event cameras are powerful new sensors able to capture high dynamic range with microsecond temporal resolution and no motion blur. Their strength is detecting brightness changes (called events) rather than capturing direct brightness images; however, algorithms can be used to convert events into usable image representations for applications such as classification. Previous works rely on hand-crafted spatial and temporal smoothing techniques to reconstruct images from events. State-of-the-art video reconstruction has recently been achieved using neural networks that are large (10M parameters) and computationally expensive, requiring 30ms for a forward-pass at 640 x 480 resolution on a modern GPU. We propose a novel neural network architecture for video reconstruction from events that is smaller (38k vs. 10M parameters) and faster (10ms vs. 30ms) than state-of-the-art with minimal impact to performance.
References
Fast Image Reconstruction with an Event Camera
IEEE Winter Conference on Applications of Computer Vision (WACV), 2020.
Learning Monocular Dense Depth from Events
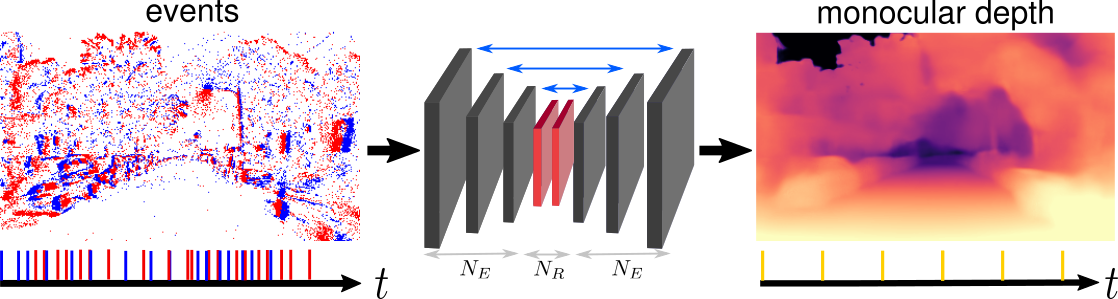
If you are interested in deep learning and event cameras, you should try our code out! We propose a recurrent architecture to solve the depth prediction task and show significant improvement over standard feed-forward methods. In particular, our method generates dense depth predictions using a monocular setup, which has not been shown previously. We pretrain our model using a new dataset containing events and depth maps recorded in the CARLA simulator. We test our method on the Multi Vehicle Stereo Event Camera Dataset (MVSEC). The code allows you to benchmark our model and generate new training data.
References

Primal-Dual Mesh Convolutional Neural Networks
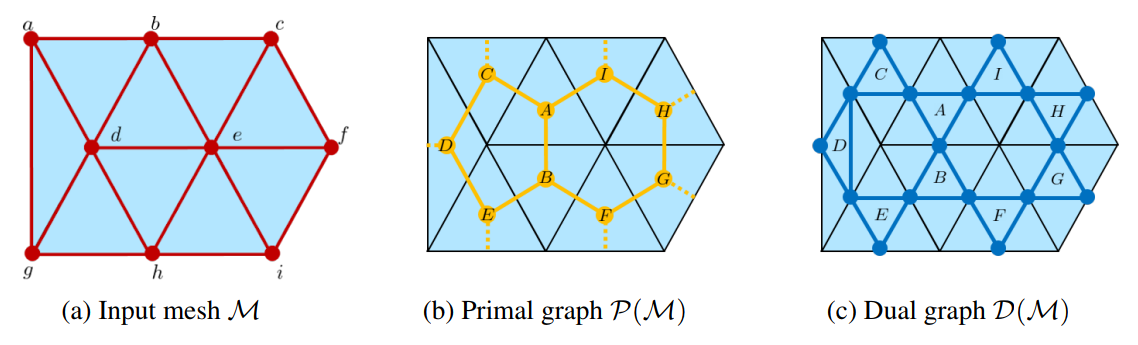
The following code allows you to train and test our Primal-Dual Mesh Convolutional Neural Network on the tasks of shape classification and shape segmentation, where our approach obtains superior performance than the state of the art. Existing mesh processing algorithms either consider the input mesh as a graph, and do not exploit specific geometric properties of meshes for feature aggregation and downsampling, or are specialized for meshes, but rely on a rigid definition of convolution that does not properly capture the local topology of the mesh.
We propose a method that combines the advantages of both types of approaches, while addressing their limitations: we extend a primal-dual framework drawn from the graph-neural-network literature to triangle meshes, and define convolutions on two types of graphs constructed from an input mesh. If you are interested in 3D data processing and geometric deep learning, you should try our code out!
References
Flightmare: A Flexible Quadrotor Simulator

We release a new modular quadrotor simulator: Flightmare. Flightmare is composed of two main components: a configurable rendering engine built on Unity and a flexible physics engine for dynamics simulation. Those two components are totally decoupled and can run independently from each other. Flightmare comes with several desirable features: (i) a large multi-modal sensor suite, including an interface to extract the 3D point-cloud of the scene; (ii) an API for reinforcement learning which can simulate hundreds of quadrotors in parallel; and (iii) an integration with a virtual-reality headset for interaction with the simulated environment. Flightmare can be used for various applications, including path-planning, reinforcement learning, visual-inertial odometry, deep learning, human-robot interaction, etc.
References

Flightmare: A Flexible Quadrotor Simulator
Conference on Robot Learning (CoRL), 2020
Fisher Information Field: an Efficient and Differentiable Map for Perception-aware Planning

We provide an implementation of the Fisher Information Field (FIF), a map representation designed for perception-aware planning. The core function of the map is to evaluate the visual localization quality at a given 6 DoF pose in a known environment. It can be used with different motion planning algorithms (e.g., RRT*, trajectory optimization) to take localization quality into consideration, in addition to common planning objectives. FIF is efficient: it is >10x faster than using the landmarks directly. It is also differentiable, making it suitable to be used in gradient-based optimization.
References
VIMO: Simultaneous Visual Inertial Model-based Odometry and Force Estimation
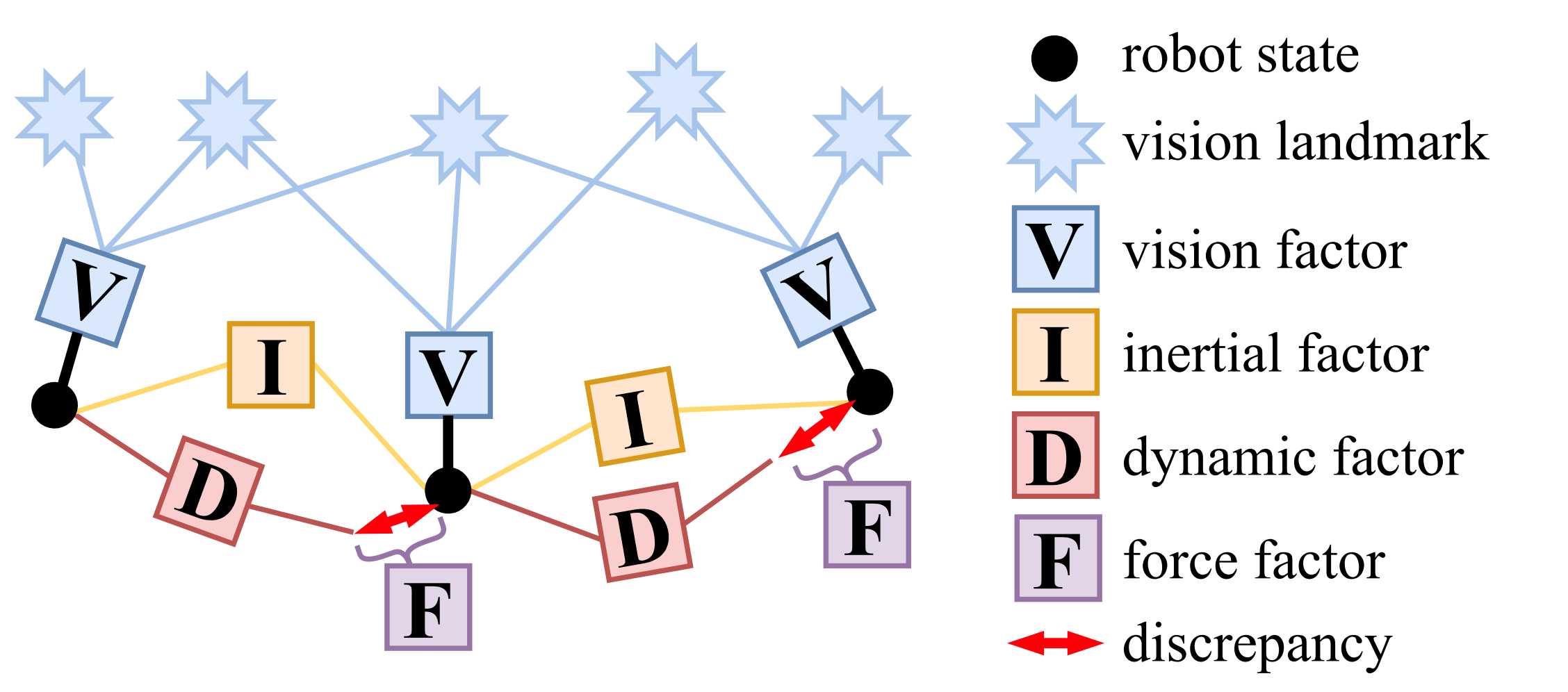
For many robotic applications, it is often essential to sense the external force acting on the system due to, for example, interactions, contacts, and disturbances. VIMO extends the capability of a typical optimization-based Visual-Inertial Odometry framework to jointly estimate external forces in addition to the robot state and IMU bias, at no extra computational cost. The results also show up to 30% increase in the accuracy of the estimator.
References
Deep Drone Acrobatics

The following code allows you training end-to-end control policies to fly acrobatic maneuvers with drones. Training is done exclusively in simulation with imitation learning from a priviledged expert. Thanks to a sensor abstraction procedure, the policies trained in simulation can be applied to a real platform without any fine-tuning on real data!
Code is available at this page. Take care, acrobatics maneuvers might push the platform to its physical limits! This approach was develop in the context of our RSS paper Deep Drone Acrobatics.
References

Are We Ready for Autonomous Drone Racing? The UZH-FPV Drone Racing Dataset
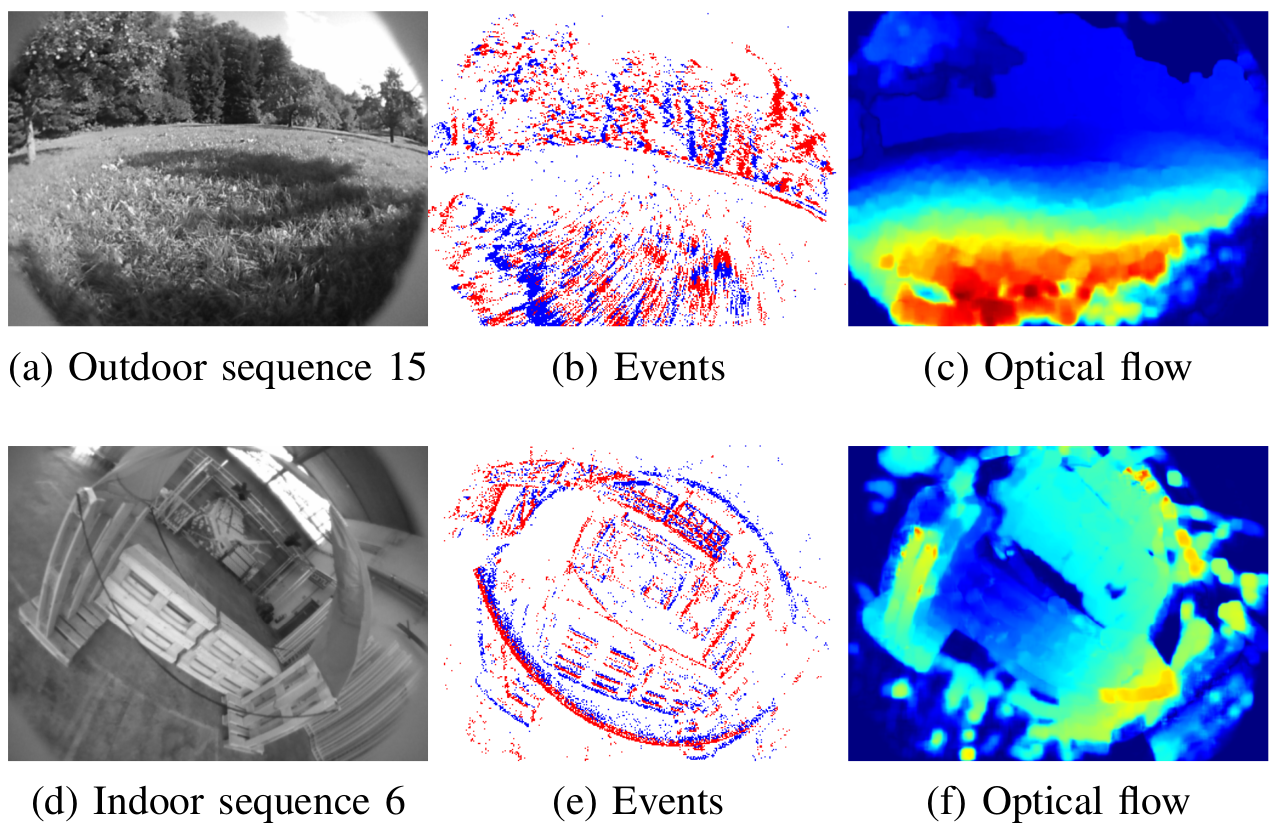
Despite impressive results in visual-inertial state estimation in recent years, high speed trajectories with six degree of freedom motion remain challenging for existing estimation algorithms. Aggressive trajectories feature large accelerations and rapid rotational motions, and when they pass close to objects in the environment, this induces large apparent motions in the vision sensors, all of which increase the difficulty in estimation. Existing benchmark datasets do not address these types of trajectories, instead focusing on slow speed or constrained trajectories, targeting other tasks such as inspection or driving.
We introduce the UZH-FPV Drone Racing dataset, consisting of over 27 sequences, with more than 10 km of flight distance, captured on a first-person-view (FPV) racing quadrotor flown by an expert pilot. The dataset features camera images, inertial measurements, event-camera data, and precise ground truth poses. These sequences are faster and more challenging, in terms of apparent scene motion, than any existing dataset. Our goal is to enable advancement of the state of the art in aggressive motion estimation by providing a dataset that is beyond the capabilities of existing state estimation algorithms.
References

Are We Ready for Autonomous Drone Racing? The UZH-FPV Drone Racing Dataset
IEEE International Conference on Robotics and Automation (ICRA), 2019.
Video to Events: Recycling Video Dataset for Event Cameras
Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. They offer significant advantages with respect to conventional cameras: high dynamic range (HDR), high temporal resolution, and no motion blur. Recently, novel learning approaches operating on event data have achieved impressive results. Yet, these methods require a large amount of event data for training, which is hardly available due the novelty of event sensors in computer vision research. In this paper, we present a method that addresses these needs by converting any existing video dataset recorded with conventional cameras to \emph{synthetic} event data. This unlocks the use of a virtually unlimited number of existing video datasets for training networks designed for real event data. We evaluate our method on two relevant vision tasks, i.e., object recognition and semantic segmentation, and show that models trained on synthetic events have several benefits: (i) they generalize well to real event data, even in scenarios where standard-camera images are blurry or overexposed, by inheriting the outstanding properties of event cameras; (ii) they can be used for fine-tuning on real data to improve over state-of-the-art for both classification and semantic segmentation.
References

Video to Events: Bringing Modern Computer Vision Closer to Event Cameras
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2020.
GPU-Accelerated Frontend for High-Speed VIO
The recent introduction of powerful embedded GPUs has enabled algorithms to run well above the standard video rates, yielding higher information processing capability and reduced latency. This code introduces an enhanced FAST feature detector that applies a GPU-specific non-maxima suppression, imposes spatial feature distribution and extracts features simultaneously. It runs on most modern NVIDIA CUDA-capable GPUS, but is further specialized with the Jetson TX2 platform in mind, on which it performs more than 1000fps throughput.
References
Faster than FAST: GPU-Accelerated Frontend for High-Speed VIO
Submitted to IEEE International Conference on Intelligent Robots and Systems, 2020.
Event-Based Angular Velocity Regression with Spiking Networks
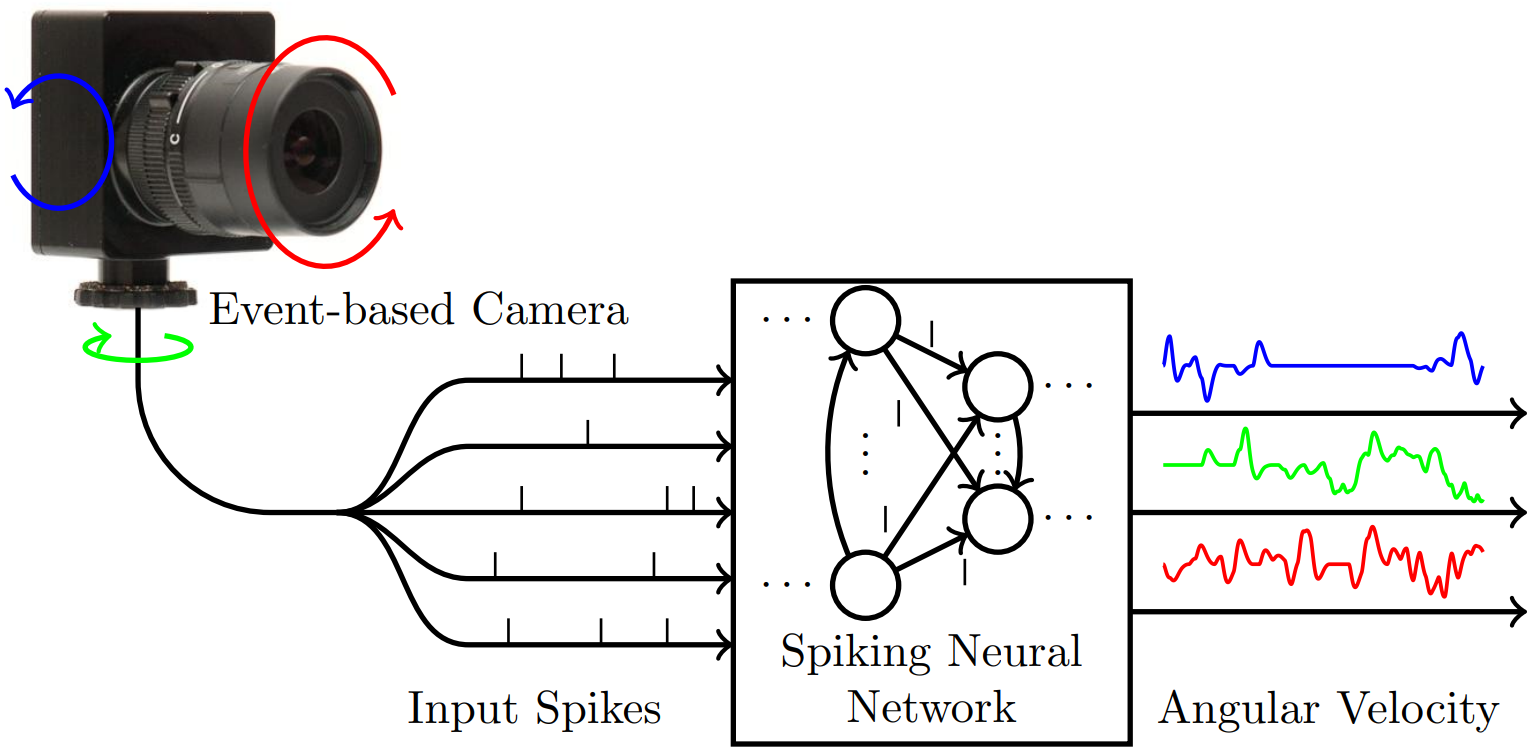
Spiking Neural Networks (SNNs) are bio-inspired networks that process information conveyed as temporal spikes rather than numeric values. These highly-parallelizable event-based networks are a prime candidate to learn patterns of spatio-temporal data as received from event cameras. The following code implements a spiking network that was trained to perform continuous-time regression of angular velocities directly from event-based data.
References
A General Framework for Uncertainty Estimation in Deep Learning

The following code presents a general framework for uncertainty estimation of deep neural network predictions. Our framework can compute uncertainties for every network architecture, does not require changes in the optimization process, and can be applied to already trained networks. Our framework's code is available at this page! This framework was develop in the context of our RA-L and ICRA 2020 paper A General Framework for Uncertainty Estimation in Deep Learning.
References

A General Framework for Uncertainty Estimation in Deep Learning
Robotics And Automation Letters, 2020.
Event Camera Driving Sequences

The following driving dataset was recorded in the context of the paper High Speed and High Dynamic Range Video with an Event Camera. The datasets consists of a number of sequences that were recorded with a VGA (640x480) event camera (Samsung DVS Gen3) and a conventional RGB camera (Huawei P20 Pro) placed on the windshield of a car driving through Zurich.
We provide all event sequences as binary rosbag files for use with the Robot Operating System (ROS). The format is the one used by the RPG DVS ROS driver.
The driving datasets are available at this page.
References

High Speed and High Dynamic Range Video with an Event Camera
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
EKLT: Event-based KLT
Event cameras are revolutionary sensors that work radically different from standard cameras. Instead of capturing intensity images at a fixed rate, event cameras measure changes of intensity asynchronously, in the form of a stream of events, which encode per-pixel brightness changes. In the last few years, their outstanding properties (asynchronous sensing, no motion blur, high dynamic range) have led to exciting vision applications, with very low-latency and high robustness.
We release EKLT, an event-based feature tracker published in our recent IJCV paper. It leverages the complementarity of event cameras and standard cameras to track visual features with low latency and in the blind time between two frames. The code is implemented in C++ and available under this link. We also provide a tool to evaluate event-based feature trackers and provide functionality to evaluate them tracks in real and simulated environments. The code is implemented in Python and can be used to easily generate paper-ready plots and videos.
References
EKLT: Asynchronous, Photometric Feature Tracking using Events and Frames
International Journal of Computer Vision (IJCV), 2019.
Deep Drone Racing: From Simulation to Reality with Domain Randomization
Dynamically changing environments, unreliable state estimation, and operation under severe resource constraints are fundamental challenges for robotics, which still limit the deployment of small autonomous drones. We address these challenges in the context of autonomous, vision-based drone racing in dynamic environments. A racing drone must traverse a track with possibly moving gates at high speed. We enable this functionality by combining the performance of a state-of-the-art path-planning and control system with the perceptual awareness of a convolutional neural network (CNN). The CNN directly maps raw images to a desired waypoint and speed. Given the CNN output, the planner generates a short minimum-jerk trajectory segment that is tracked by a model-based controller to actuate the drone towards the waypoint. The resulting modular system has several desirable features: (i) it can run fully on-board, (ii) it does not require globally consistent state estimation, and (iii) it is both platform and domain independent. We extensively test the precision and robustness of our system, both in simulation and on a physical platform. In both domains, our method significantly outperforms the prior state of the art. In order to understand the limits of our approach, we additionally compare against professional human drone pilots with different skill levels.
References

Deep Drone Racing: From Simulation to Reality with Domain Randomization
IEEE Transactions on Robotics, 2019
SIPs: Succinct Interest Points from Unsupervised Inlierness Probability Learning

A wide range of computer vision algorithms rely on identifying sparse interest points in images and establishing correspondences between them. However, only a subset of the initially identified interest points results in true correspondences (inliers). In this paper, we seek a detector that finds the minimum number of points that are likely to result in an application-dependent "sufficient" number of inliers k. To quantify this goal, we introduce the "k-succinctness" metric. Extracting a minimum number of interest points is attractive for many applications, because it can reduce computational load, memory, and data transmission. Alongside succinctness, we introduce an unsupervised training methodology for interest point detectors that is based on predicting the probability of a given pixel being an inlier. In comparison to previous learned detectors, our method requires the least amount of data pre-processing. Our detector and other state-of-the-art detectors are extensively evaluated with respect to succinctness on popular public datasets covering both indoor and outdoor scenes, and both wide and narrow baselines. In certain cases, our detector is able to obtain an equivalent amount of inliers with as little as 60% of the amount of points of other detectors.
References

SIPs: Succinct Interest Points from Unsupervised Inlierness Probability Learning
IEEE International Conference on 3D Vision (3DV), 2019.
Matching Features without Descriptors: Implicitly Matched Interest Points

The extraction and matching of interest points is a prerequisite for many geometric computer vision problems. Traditionally, matching has been achieved by assigning descriptors to interest points and matching points that have similar descriptors. In this paper, we propose a method by which interest points are instead already implicitly matched at detection time. With this, descriptors do not need to be calculated, stored, communicated, or matched any more. This is achieved by a convolutional neural network with multiple output channels and can be thought of as a collection of a variety of detectors, each specialised to specific visual features. This paper describes how to design and train such a network in a way that results in successful relative pose estimation performance despite the limitation on interest point count. While the overall matching score is slightly lower than with traditional methods, the approach is descriptor free and thus enables localization systems with a significantly smaller memory footprint and multi-agent localization systems with lower bandwidth requirements. The network also outputs the confidence for a specific interest point resulting in a valid match. We evaluate performance relative to state-of-the-art alternatives.
References

Matching Features without Descriptors:
Implicitly Matched Interest Points
British Machine Vision Conference (BMVC), Cardiff, 2019.
High Speed and High Dynamic Range with an Event Camera

Event cameras are novel sensors that report brightness changes in the form of a stream of asynchronous events instead of intensity frames. They offer significant advantages with respect to conventional cameras: high temporal resolution, high dynamic range, and no motion blur. While the stream of events encodes in principle the complete visual signal, the reconstruction of an intensity image from a stream of events is an ill-posed problem in practice. Existing reconstruction approaches are based on hand-crafted priors and strong assumptions about the imaging process as well as the statistics of natural images.
In this work we propose to learn to reconstruct intensity images from event streams directly from data instead of relying on any hand-crafted priors. We propose a novel recurrent network to reconstruct videos from a stream of events, and train it on a large amount of simulated event data. During training we propose to use a perceptual loss to encourage reconstructions to follow natural image statistics. We further extend our approach to synthesize color images from color event streams.
Our quantitative experiments show that our network surpasses state-of-the-art reconstruction methods by a large margin in terms of image quality (> 20%), while comfortably running in real-time. We show that the network is able to synthesize high framerate videos (> 5,000 frames per second) of high-speed phenomena (e.g. a bullet hitting an object) and is able to provide high dynamic range reconstructions in challenging lighting conditions. As an additional contribution, we demonstrate the effectiveness of our reconstructions as an intermediate representation for event data. We show that off-the-shelf computer vision algorithms can be applied to our reconstructions for tasks such as object classification and visual-inertial odometry and that this strategy consistently outperforms algorithms that were specifically designed for event data. We release the reconstruction code and a pre-trained model to enable further research.
References
High Speed and High Dynamic Range Video with an Event Camera
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
CED: Color Event Camera Dataset

Event cameras are novel, bio-inspired visual sensors, whose pixels output asynchronous and independent timestamped spikes at local intensity changes, called "events". Event cameras offer advantages over conventional frame-based cameras in terms of latency, high dynamic range (HDR) and temporal resolution. Until recently, event cameras have been limited to outputting events in the intensity channel, however, recent advances have resulted in the development of color event cameras, such as the Color DAVIS346.
In this work, we present and release the first Color Event Camera Dataset (CED), containing 50 minutes of footage with both color frames and events. CED features a wide variety of indoor and outdoor scenes, which we hope will help drive forward event-based vision research. We also present an extension of the event camera simulator ESIM that enables simulation of color events. Finally, we present an evaluation of three state-of-the-art image reconstruction methods that can be used to convert the Color DAVIS346 into a continuous-time, HDR, color video camera to visualise the event stream, and for use in downstream vision applications.
References
Event-based, Direct Camera Tracking from a Photometric 3D Map using Nonlinear Optimization
Event cameras are revolutionary sensors that work radically differently from standard cameras. Instead of capturing intensity images at a fixed rate, event cameras measure changes of intensity asynchronously, in the form of a stream of events, which encode per-pixel brightness changes. In the last few years, their outstanding properties (asynchronous sensing, no motion blur, high dynamic range) have led to exciting vision applications, with very low-latency and high robustness.
We release the datasets and photometric 3D maps used to evaluate our direct event-camera tracking algorithms. Every dataset consists of one or more trajectories of an event camera (stored as a rosbag) and corresponding photometric 3D map in the form of a point cloud for real data and a textured mesh for simulated scenes. All datasets contain ground truth provided by a motion capture system (for indoor recordings), SVO (for outdoor ones) or the simulator itself. The respective calibration data is provided as well (both the raw data used for calibration as well as the resulting intrinsic and extrinsic parameters).
References

Event-based, Direct Camera Tracking from a Photometric 3D Map using Nonlinear Optimization
IEEE International Conference on Robotics and Automation (ICRA), 2019.
EMVS: Event-based Multi-View Stereo
Event cameras are revolutionary sensors that work radically differently from standard cameras. Instead of capturing intensity images at a fixed rate, event cameras measure changes of intensity asynchronously, in the form of a stream of events, which encode per-pixel brightness changes. In the last few years, their outstanding properties (asynchronous sensing, no motion blur, high dynamic range) have led to exciting vision applications, with very low-latency and high robustness.
We release the code of our 3-D Event-based Multi-View Stereo (EMVS), that is, for 3D reconstruction with a moving event camera. Our method elegantly exploits two inherent properties of event cameras: (1) their ability to respond to scene edges (which naturally provide semi-dense geometric information) and (2) the fact that they provide continuous measurements as they move. The code provided is implemented in C++ and produces accurate, semi-dense depth maps without requiring any explicit data association or intensity estimation. The code is computationally efficient and runs in real-time on a CPU.
References
EMVS: Event-Based Multi-View Stereo - 3D Reconstruction with an Event Camera in Real-Time
International Journal of Computer Vision, 2017.
ESIM: an Open Event Camera Simulator
Event cameras are revolutionary sensors that work radically differently from standard cameras. Instead of capturing intensity images at a fixed rate, event cameras measure changes of intensity asynchronously, in the form of a stream of events, which encode per-pixel brightness changes. In the last few years, their outstanding properties (asynchronous sensing, no motion blur, high dynamic range) have led to exciting vision applications, with very low-latency and high robustness.
We present ESIM: an efficient event camera simulator implemented in C++ and available open source. ESIM can simulate arbitrary camera motion in 3D scenes, while providing events, standard images, inertial measurements, with full ground truth information including camera pose, velocity, as well as depth and optical flow maps.
References
ESIM: an Open Event Camera Simulator
Conference on Robot Learning (CoRL), Zurich, 2018.
Semi-Dense 3D Reconstruction with a Stereo Event Camera
Event cameras are bio-inspired sensors that offer several advantages, such as low latency, high-speed and high dynamic range, to tackle challenging scenarios in computer vision. This paper presents a solution to the problem of 3D reconstruction from data captured by a stereo event-camera rig moving in a static scene, such as in the context of stereo Simultaneous Localization and Mapping.
We release the datasets used to evaluate our stereo event-based 3D reconstruction method. Every dataset consists events from two DAVIS cameras (stored as a rosbag) and ground truth camera trajectory provided by a motion capture system or by a simulator. The respective calibration data is also provided (both the raw data used for calibration and the resulting intrinsic and extrinsic parameters).
References

Semi-Dense 3D Reconstruction with a Stereo Event Camera
European Conference on Computer Vision (ECCV), Munich, 2018.
A Tutorial on Quantitative Trajectory Evaluation for Visual(-Inertial) Odometry
In this tutorial, we provide principled methods to quantitatively evaluate the quality of an estimated trajectory from visual(-inertial) odometry (VO/VIO), which is the foundation of benchmarking the accuracy of different algorithms. First, we show how to determine the transformation type to use in trajectory alignment based on the specific sensing modality (i.e., monocular, stereo and visual-inertial). Second, we describe commonly used error metrics (i.e., the absolute trajectory error and the relative error) and their strengths and weaknesses. To make the methodology presented for VO/VIO applicable to other setups, we also generalize our formulation to any given sensing modality. To facilitate the reproducibility of related research, we publicly release our implementation of the methods described in this tutorial.
References
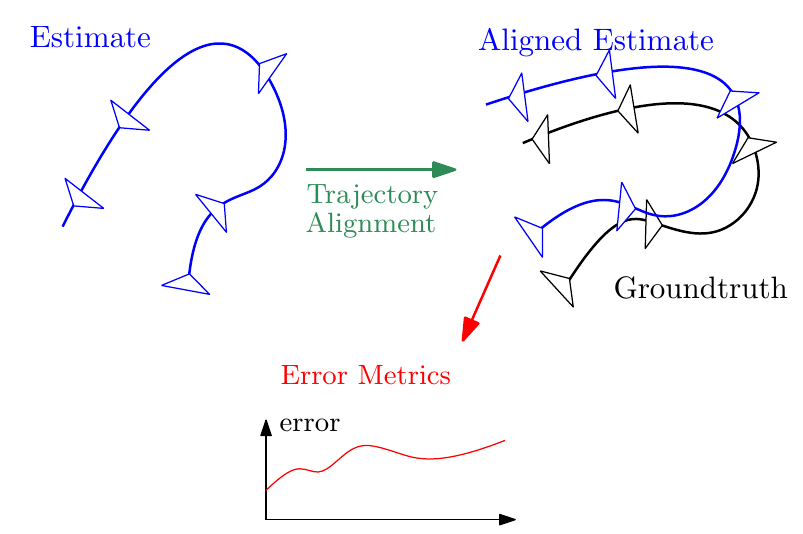
A Tutorial on Quantitative Trajectory Evaluation for Visual(-Inertial) Odometry
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, 2018.
On the Comparison of Gauge Freedom Handling in Optimization-based Visual-Inertial State Estimation
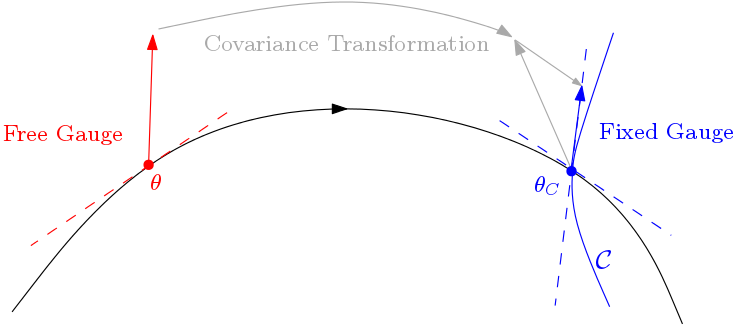
It is well known that visual-inertial state estimation is possible up to a four degrees-of-freedom (DoF) transformation (rotation around gravity and translation), and the extra DoFs ("gauge freedom") have to be handled properly. While different approaches for handling the gauge freedom have been used in practice, no previous study has been carried out to systematically analyze their differences. In this paper, we present the first comparative analysis of different methods for handling the gauge freedom in optimization-based visual-inertial state estimation. We experimentally compare three commonly used approaches: fixing the unobservable states to some given values, setting a prior on such states, or letting the states evolve freely during optimization. Specifically, we show that (i) the accuracy and computational time of the three methods are similar, with the free gauge approach being slightly faster; (ii) the covariance estimation from the free gauge approach appears dramatically different, but is actually tightly related to the other approaches. Our findings are validated both in simulation and on real-world datasets and can be useful for designing optimization-based visual-inertial state estimation algorithms.
Open-Source Code for Covariance Transformation
References
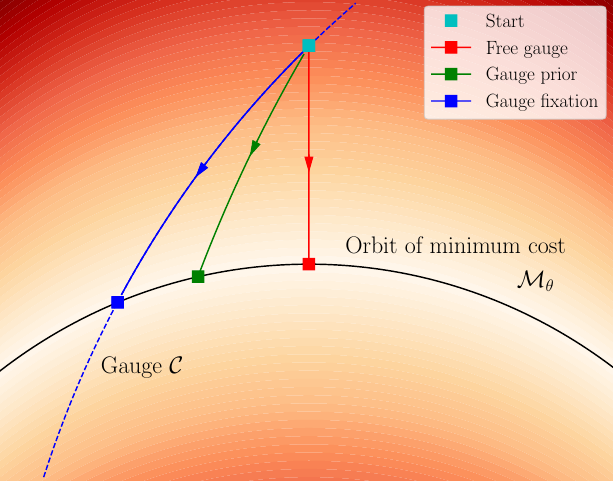
DroNet: Learning to Fly by Driving
Civilian drones are soon expected to be used in a wide variety of tasks, such as aerial surveillance, delivery, or monitoring of existing architectures. Nevertheless, their deployment in urban environments has so far been limited. Indeed, in unstructured and highly dynamic scenarios drones face numerous challenges to navigate autonomously in a feasible and safe way. In contrast to the traditional map-localize-plan methods, this paper explores a data-driven approach to cope with the above challenges. To do this, we propose DroNet, a convolutional neural network that can safely drive a drone through the streets of a city. Designed as a fast 8-layers residual network, DroNet produces, for each single input image, two outputs: a steering angle, to keep the drone navigating while avoiding obstacles, and a collision probability, to let the UAV recognize dangerous situations and promptly react to them. But how to collect enough data in an unstructured outdoor environment, such as a city? Clearly, having an expert pilot providing training trajectories is not an option given the large amount of data required and, above all, the risk that it involves for others vehicles or pedestrians moving in the streets. Therefore, we propose to train a UAV from data collected by cars and bicycles, which, already integrated into urban environments, would expose other cars and pedestrians to no danger. Although trained on city streets, from the viewpoint of urban vehicles, the navigation policy learned by DroNet is highly generalizable. Indeed, it allows a UAV to successfully fly at relative high altitudes, and even in indoor environments, such as parking lots and corridors.
References

DroNet: Learning to Fly by Driving
IEEE Robotics and Automation Letters (RA-L), 2018.
PDF YouTube Software and DatasetsRPG Quadrotor MPC and Perception-Aware MPC
We released an implementation of our Model Predictive Control (MPC) framework, which integrates with our open-source Quadrotor Control Framework. It is capable of predicting and optimizing a receding horizon to control a quadrotor towards a reference pose or along a reference trajectory. Furthermore, it includes our PAMPC, based on our publication "PAMPC: Perception Aware Model Predictive Control", combining optimization for action and perception objectives. It uses the reprojection of a point of interest in the camera frame as a cost to keep it visible during complicated maneuvers. This allows to not only drop the yaw control to the PAMPC, but also to modify an reshape trajectories to facilitate visibility of points and plan within the dynamics and actuation limits of the platform. The implementation uses ROS on Linux and is optimized to run in real-time on an ARM computer, like an Odroid XU4 or similar. It has a latency of <2ms (from calling an iteration to availability of control command) and needs an overall processing time of <5ms. Typically it runs at 50-100 Hz returning bodyrates and collective thrust to a faster low-level controller (i.e. commercial flight controller) as used in our platform example. We use the ACADO Toolkit, developed by the Optimization in Engineering Center (OPTEC) under supervision of Moritz Diehl. Our source code is release und GPLv3.
References

PAMPC: Perception-Aware Model Predictive Control for Quadrotors
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, 2018.
NetVLAD in Python/TensorFlow
NetVLAD (website, paper) is a place recognition neural network which takes an
image as input and produces a vector as output. If two images are taken in the same place, the Euclidean
between these vectors is small, otherwise not. Using nearest-neighbours search on these vectors, the authors
have shown excellent place recognition performance, even under severe appearance changes.
Unfortunately, the full network has officially so far only been implemented in Matlab, rendering deployment on non-desktop PCs
and robots tedious.
We are happy to announce a Python/Tensorflow port of the FULL network, approved by the original authors and
available here. The repository contains code which
allows plug-and-play python deployment of the best off-the-shelf model made available by the authors. We
have thoroughly tested that the ported model produces a similar output to the original Matlab
implementation, as well as excellent place recognition performance on KITTI 00. The repository does not
contain code to train the network, however, it should be easy to adapt to other models trained in Matlab.
In our own research, we have previously used NetVLAD here and here, and will continue to use it extensively.
References

Data-Efficient Decentralized Visual SLAM
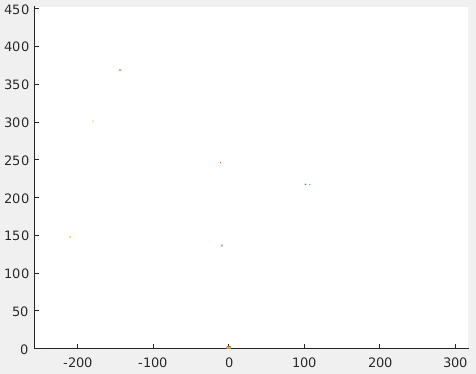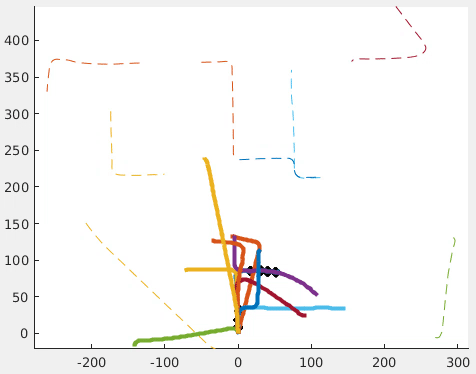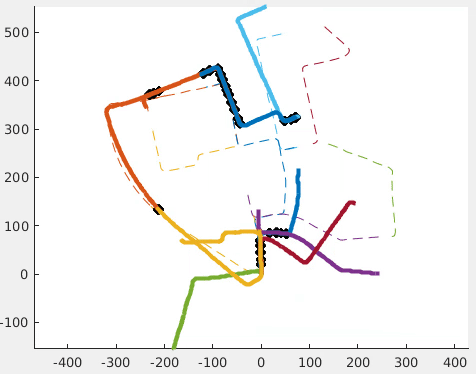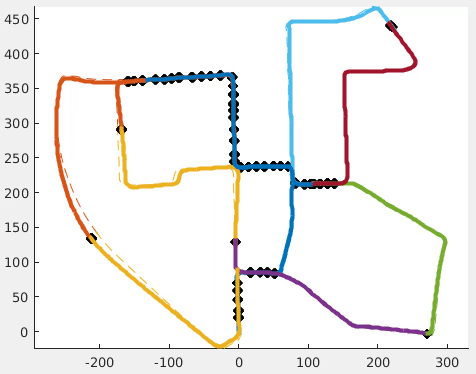
Decentralized visual simultaneous localization and mapping (SLAM) is a powerful tool for multi-robot applications in environments where absolute positioning is not available. Being visual, it relies on cheap, lightweight and versatile cameras, and, being decentralized, it does not rely on communication to a central entity. In this work, we integrate state-of-theart decentralized SLAM components into a new, complete decentralized visual SLAM system. To allow for data association and optimization, existing decentralized visual SLAM systems exchange the full map data among all robots, incurring large data transfers at a complexity that scales quadratically with the robot count. In contrast, our method performs efficient data association in two stages: first, a compact full-image descriptor is deterministically sent to only one robot. Then, only if the first stage succeeded, the data required for relative pose estimation is sent, again to only one robot. Thus, data association scales linearly with the robot count and uses highly compact place representations. For optimization, a state-of-theart decentralized pose-graph optimization method is used. It exchanges a minimum amount of data which is linear with trajectory overlap. We characterize the resulting system and identify bottlenecks in its components. The system is evaluated on publicly available datasets and we provide open access to the code.
References
Data-Efficient Decentralized Visual SLAM
IEEE International Conference on Robotics and Automation (ICRA), 2018.
Fast Event-based Corner Detection
Inspired by frame-based pre-processing techniques that reduce an image to a set of features, which are typically the input to higher-level algorithms, we propose a method to reduce an event stream to a corner event stream. Our goal is twofold: extract relevant tracking information (corners do not suffer from the aperture problem) and decrease the event rate for later processing stages. Our event-based corner detector is very efficient due to its design principle, which consists of working on the Surface of Active Events (a map with the timestamp of the latest event at each pixel) using only comparison operations. Our method asynchronously processes event by event with very low latency. Our implementation is capable of processing millions of events per second on a single core (less than a micro-second per event) and reduces the event rate by a factor of 10 to 20.
References

Fast Event-based Corner Detection
British Machine Vision Conference (BMVC), London, 2017.
RPG Quadrotor Control Framework

We provide a complete framework for flying quadrotors based on control algorithms developed by the Robotics and Perception Group. We also provide an interface to the RotorS Gazebo plugins to use our algorithms in simulation. Together with the provided simple trajectory generation library, this can be used to test and use our sofware in simulation only. We also provide some utility to command a quadrotor with a gamepad through our framework as well as some calibration routines to compensate for varying battery voltage. Finally, we provide an interface to communicate with flight controllers used for First-Person-View racing.
SVO 2.0: Semi-Direct Visual Odometry
We provide the binaries of our semi-direct visual odometry algorithm, SVO 2.0. It can run up to 400 frames per second on a modern laptop and execute at 60 frames per second on a smartphone processor. The provided binaries suppport different camera models (pinhole, fisheye and catadioptric) and setups (monocular, stereo).
Image Reconstruction from an Event Camera

We provide code for brightness image reconstruction from a rotating event camera. For simplicity, we assume that the orientation of the camera is given, e.g., it is provided by a pose-tracking algorithm or by ground truth camera poses. The algorithm uses a per-pixel Extended Kalman Filter (EKF) approach to estimate the brightness image or gradient map that caused the events.
Event Lifetime
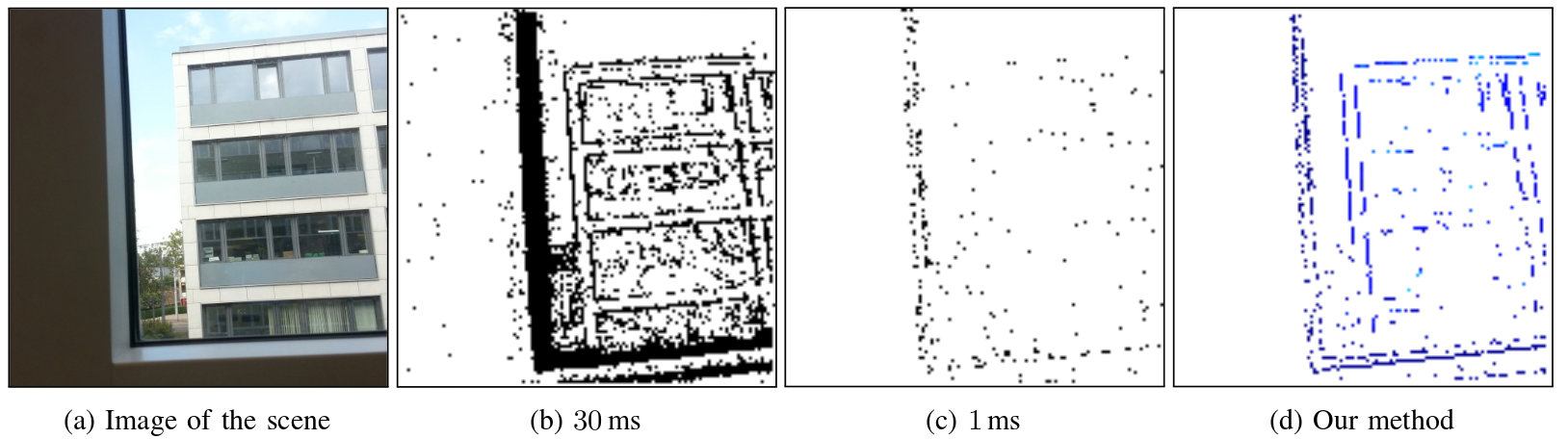
The lifetime of an event is the time that it takes for the moving brightness gradient causing the event to travel a distance of 1 pixel. The provided algorithm augments each event with its lifetime, which is computed from the event's velocity on the image plane. The generated stream of augmented events gives a continuous representation of events in time, hence enabling the design of new algorithms that outperform those based on the accumulation of events over fixed, artificially-chosen time intervals. A direct application of this augmented stream is the construction of sharp gradient (edge-like) images at any time instant.
References
The Zurich Urban Micro Aerial Vehicle Dataset
This dataset presents the world's first collection of data recorded with an camera-equipped drone in urban streets at low altitudes (5-15m). The 2 km dataset consists of time synchronized aerial high-resolution images, GPS and IMU data, ground-level Google Street-View images, and ground truth, for a total of 28GB of data. The dataset is ideal to evaluate and benchmark appearance-based localization, monocular visual odometry, simultaneous localization and mapping (SLAM), and online 3D reconstruction algorithms for MAVs in urban environments. The data also include intensity images, inertial measurements, and ground truth from a motion-capture system. An event-based camera is a revolutionary vision sensor with three key advantages: a measurement rate that is almost 1 million times faster than standard cameras, a latency of 1 microsecond, and a high dynamic range of 130 decibels (standard cameras only have 60 dB). These properties enable the design of a new class of algorithms for high-speed robotics, where standard cameras suffer from motion blur and high latency. All the data are released both as text files and binary (i.e., rosbag) files.
More information on the dataset website.
References
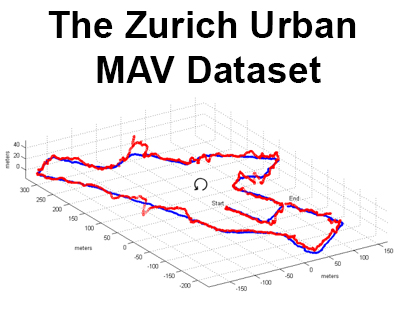
The Event-Camera Dataset and Simulator
This dataset presents the world's first collection of datasets with an event-based camera for high-speed robotics. The data also include intensity images, inertial measurements, and ground truth from a motion-capture system. An event-based camera is a revolutionary vision sensor with three key advantages: a measurement rate that is almost 1 million times faster than standard cameras, a latency of 1 microsecond, and a high dynamic range of 130 decibels (standard cameras only have 60 dB). These properties enable the design of a new class of algorithms for high-speed robotics, where standard cameras suffer from motion blur and high latency. All the data are released both as text files and binary (i.e., rosbag) files.
More information on the dataset website.
References
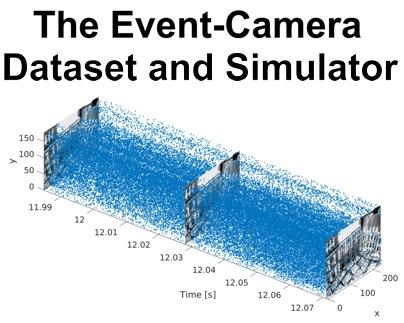
The Event-Camera Dataset and Simulator: Event-based Data for Pose Estimation, Visual Odometry, and SLAM
International Journal of Robotics Research, Vol. 36, Issue 2, pages 142-149, Feb. 2017.
Information Gain Based Active Reconstruction Framework
The Information Gain Based Active Reconstruction Framework is a modular, robot-agnostic, software package for performing next-best-view planning for volumetric object reconstruction using a range sensor. Our implementation can be easily adapted to any mobile robot equipped with any camera-based range sensor (e.g stereo camera, structured light sensor) to iteratively observe an object to generate a volumetric map and a point cloud model. The algorithm allows the user to define the information gain metric for choosing the next best view, and many formulations for these metrics are evaluated and compared in our ICRA paper. This framework is released open source as a ROS-compatible package for autonomous 3D reconstruction tasks.
Download the code from GitHub.
Check out a video of the system in action on YouTube.
References

Fisheye and Catadioptric Synthetic Datasets for Visual Odometry
We provide two synthetic scenes (vehicle moving in a city, and flying robot hovering in a confined room). For each scene, three different optics were used (perspective, fisheye and catadioptric), but the same sensor is used (keeping the image resolution constant). These datasets were generated using Blender, using a custom omnidirectional camera model, which we release as an open-source patch for Blender.
Download the datasets from here.
References

Benefit of Large Field-of-View Cameras for Visual Odometry
IEEE International Conference on Robotics and Automation (ICRA), Stockholm, 2016.
PDF YouTube Research page (datasets and software) C++ omnidirectional camera model
Indoor Dataset of Quadrotor with Down-Looking Camera

This dataset contains the recording of the raw images, IMU measurements as well as the ground truth poses of a quadrotor flying a circular trajectory in a office size environment.
REMODE: Real-time, Probabilistic, Monocular, Dense Reconstruction
REMODE is a novel method to estimate dense and accurate depth maps from a single moving camera. A probabilistic depth measurement is carried out in real time on a per-pixel basis and the computed uncertainty is used to reject erroneous estimations and provide live feedback on the reconstruction progress. REMODE uses a novel approach to depth map computation that combines Bayesian estimation and recent development on convex optimization for image processing. In the reference paper below, we demonstrate that our method outperforms state-of-the-art techniques in terms of accuracy, while exhibiting high efficiency in memory usage and computing power. Our CUDA-based implementation runs at 50Hz on a laptop computer and is released as open-source software (code here).
Download the code from GitHub.
References

SVO: Semi-direct Visual Odometry
SVO is a Semi-direct, monocular Visual Odometry algorithm that is precise, robust, and faster than current state-of-the-art methods. The semi-direct approach eliminates the need of costly feature extraction and robust matching techniques for motion estimation. SVO operates directly on pixel intensities, which results in subpixel precision at high frame-rates. A probabilistic mapping method that explicitly models outlier and depth uncertainty is used to estimate 3D points, which results in fewer outliers and more reliable points. Precise and high frame-rate motion estimation brings increased robustness in scenes of little, repetitive, and high-frequency texture. The algorithm is applied to micro-aerial-vehicle state-estimation in GPS-denied environments and runs at 55 frames per second on the onboard embedded computer and at more than 400 frames per second on anm i7 consumer laptop and more than 70 frames per second on a smartphone computer (e.g., Odroid or Samsung Galaxy phones).
Download the code from GitHub.
Reference
ROS Driver and Calibration Tool for the Dynamic Vision Sensor (DVS)
The RPG DVS ROS Package allow to use the Dynamic Vision Sensor (DVS) within the Robot Operating System (ROS). It also contains a calibration tool for intrinsic and stereo calibration using a blinking pattern.
The code with instructions on how to use it is hosted on GitHub.
Authors: Elias Mueggler, Basil Huber, Luca Longinotti, Tobi Delbruck
References
E. Mueggler, B. Huber, D. Scaramuzza Event-based, 6-DOF Pose Tracking for High-Speed Maneuvers, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Chicago, 2014. [ PDF ]
A. Censi, J. Strubel, C. Brandli, T. Delbruck, D. Scaramuzza Low-latency localization by Active LED Markers tracking using a Dynamic Vision Sensor, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, 2013. (PDF) [ PDF ]
P. Lichtsteiner, C. Posch, T. Delbruck A 128x128 120dB 15us Latency Asynchronous Temporal Contrast Vision Sensor, IEEE Journal of Solid State Circuits, Feb. 2008, 43(2), 566-576. [ PDF ]
A Monocular Pose Estimation System based on Infrared LEDs
Mutual localization is a fundamental component for multi-robot missions. Our monocular pose estimation system consists of multiple infrared LEDs and a camera with an infrared-pass filter. The LEDs are attached to the robot that we want to track, while the observing robot is equipped with the camera.
The code with instructions on how to use it is hosted on GitHub.
Reference
Matthias Faessler, Elias Mueggler, Karl Schwabe and Davide Scaramuzza, A Monocular Pose Estimation System based on Infrared LEDs, Proc. IEEE International Conference on Robotics and Automation (ICRA), 2014, Hong Kong. [ PDF ]
Torque Control of a KUKA youBot Arm
Existing control schemes for the KUKA youBot arm, such as directly controlling joint positions or velocities, are not suited for close tracking of end effector trajectories. A torque controller, based on the dynamical model of the youBot arm, was implemented to overcome this limitation. Complementary to the controller, a framework to automatically generate trajectories was developed.
The code with instructions on how to use it is hosted on GitHub. Details are provided in the Master Thesis of Benjamin Keiser.
Authors: Benjamin Keiser, Matthias Faessler, Elias Mueggler
Reference
B. Keiser, E. Mueggler, M. Faessler, D. Scaramuzza Torque Control of a KUKA youBot Arm, Master Thesis, University of Zurich, September, 2013. [ PDF ]
Dataset: Air-Ground Matching of Airborne images with Google Street View data
Matching airborne images to ground level ones is a challenging problem since in this case extreme changes in viewpoint and scale can be found between the aerial Micro Aerial Vehicle (MAV) images and the ground-level images, aside the challenges present in ground visual search algorithms used in UGV applications, such as illumination, lens distortions, over season variation of the vegetation, and scene changes between the query and the database images.
Our dataset consists of image data captured with a small quadroctopter flying in the streets of Zurich (up to 15 meters from the ground), along a path of 2km, including: (1) aerial MAV Images, (2) ground-level Google Street View Images, (3) ground-truth confusion matrix, and (4) GPS data (geotags) for every database image.
Authors: Andras Majdik and Yves Albers-Schoenberg
Reference
A.L. Majdik, D. Verda, Y. Albers-Schoenberg, D. Scaramuzza Air-ground Matching: Appearance-based GPS-denied Urban Localization of Micro Aerial Vehicles Journal of Field Robotics, 2015. [ PDF ]
A. L. Majdik, D. Verda, Y. Albers-Schoenberg, D. Scaramuzza Micro Air Vehicle Localization and Position Tracking from Textured 3D Cadastral Models IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, 2014. [ PDF ]
A. Majdik, Y. Albers-Schoenberg, D. Scaramuzza. MAV Urban Localization from Google Street View Data, IROS'13, IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS'13, 2013. [ PDF ] [ PPT ]
Perspective 3-Point (P3P) Algorithm
The Perspective-Three-Point (P3P) problem aims at determining the position and orientation of a camera in the world reference frame from three 2D-3D point correspondences. Most solutions attempt to first solve for the position of the points in the camera reference frame, and then compute the point aligning transformation between the camera and the world frame. In contrast, this work proposes a novel closed-form solution to the P3P problem, which computes the aligning transformation directly in a single stage, without the intermediate derivation of the points in the camera frame. This is made possible by introducing intermediate camera and world reference frames, and expressing their relative position and orientation using only two parameters. The projection of a world point into the parametrized camera pose then leads to two conditions and finally a quartic equation for finding up to four solutions for the parameter pair. A subsequent backsubstitution directly leads to the corresponding camera poses with respect to the world reference frame. The superior computational efficiency is particularly suitable for any RANSAC-outlier-rejection step, which is always recommended before applying PnP or non-linear optimization of the final solution.
Author: Laurent Kneip
Reference
L. Kneip, D. Scaramuzza, R. Siegwart. A Novel Parameterization of the Perspective-Three-Point Problem for a Direct Computation of Absolute Camera Position and Orientation. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, USA, 2011. [ PDF ]
OCamCalib: Omnidirectional Camera Calibration Toolbox for Matlab

Omnidirectional Camera Calibration Toolbox for Matlab (for Windows, MacOS, and Linux) for catadioptric and fisheye cameras up to 195 degrees.
Code, tutorials, and datasets can be found here.
Author: Davide Scaramuzza
Reference
D. Scaramuzza, A. Martinelli, R. Siegwart. A Toolbox for Easily Calibrating Omnidirectional Cameras. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2006), Beijing, China, October 2006. [ PDF ]
D. Scaramuzza, A. Martinelli, R. Siegwart. A Flexible Technique for Accurate Omnidirectional Camera Calibration and Structure from Motion. IEEE International Conference on Computer Vision Systems (ICVS 2006), New York, USA, January 2006. [ PDF ]