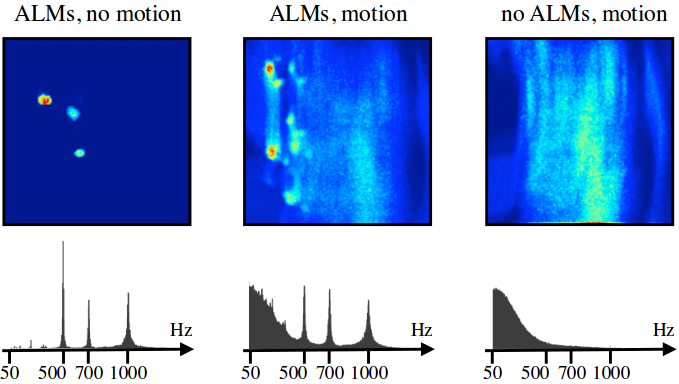
Event-based Vision, Event Cameras, Event Camera SLAM
Event cameras, such as the Dynamic Vision Sensor (DVS), are bio-inspired vision sensors that output pixel-level brightness changes instead of standard intensity frames. They offer significant advantages over standard cameras, namely a very high dynamic range, no motion blur, and a latency in the order of microseconds. However, because the output is composed of a sequence of asynchronous events rather than actual intensity images, traditional vision algorithms cannot be applied, so that new algorithms that exploit the high temporal resolution and the asynchronous nature of the sensor are required.
Do you want to know more about event cameras or play with them?
- Check out our survey paper, our tutorial on event cameras (PDF, PPT), and our event-camera dataset, which also includes intensity images, IMU, ground truth, synthetic data, as well as an event-camera simulator!
- Check out this list of event-based vision resources, which we started to collect information about this exciting technology.
CVPR 2023 Workshop on Event-based Vision
 On June 19th, 2023, Guillermo Gallego (TU Berlin), Davide Scaramuzza (UZH), and Kostas Daniilidis (UPENN), Cornelia Fermueller (Univ. of Maryland), Davide Migliore (Prophesee)
are organizing the 4rd International Workshop on Event-based Vision at CVPR 2023. The event will take place onsite.
On June 19th, 2023, Guillermo Gallego (TU Berlin), Davide Scaramuzza (UZH), and Kostas Daniilidis (UPENN), Cornelia Fermueller (Univ. of Maryland), Davide Migliore (Prophesee)
are organizing the 4rd International Workshop on Event-based Vision at CVPR 2023. The event will take place onsite.
CVPR 2021 Workshop on Event-based Vision
 On June 19th, 2021, Guillermo Gallego (TU Berlin), Davide Scaramuzza (UZH), and Kostas Daniilidis (UPENN), Cornelia Fermueller (Univ. of Maryland), Davide Migliore (Prophesee)
organized the 3rd International Workshop on Event-based Vision at CVPR 2021. The event took place online.
Check out the video recordings, slides, proceedings and live demos.
On June 19th, 2021, Guillermo Gallego (TU Berlin), Davide Scaramuzza (UZH), and Kostas Daniilidis (UPENN), Cornelia Fermueller (Univ. of Maryland), Davide Migliore (Prophesee)
organized the 3rd International Workshop on Event-based Vision at CVPR 2021. The event took place online.
Check out the video recordings, slides, proceedings and live demos.
CVPR 2019 Workshop on Event-based Vision and Smart Cameras
![]() On June 17th, 2019, Davide Scaramuzza (RPG), Guillermo Gallego (RPG), and Kostas Daniilidis (UPenn)
organized the 2nd International Workshop on Event-based Vision and Smart Cameras at CVPR in Long Beach.
Check out the video recordings, slides, proceedings and live demos.
On June 17th, 2019, Davide Scaramuzza (RPG), Guillermo Gallego (RPG), and Kostas Daniilidis (UPenn)
organized the 2nd International Workshop on Event-based Vision and Smart Cameras at CVPR in Long Beach.
Check out the video recordings, slides, proceedings and live demos.
ICRA 2017 Workshop on Event-based Vision
 On June 2nd, 2017, Davide Scaramuzza (RPG), Guillermo Gallego (RPG), and Andrea Censi (ETH)
organized the 1st International Workshop on Event-based Vision at ICRA in Singapore.
Check out the slides and proceedings.
On June 2nd, 2017, Davide Scaramuzza (RPG), Guillermo Gallego (RPG), and Andrea Censi (ETH)
organized the 1st International Workshop on Event-based Vision at ICRA in Singapore.
Check out the slides and proceedings.
Event-based SLAM Benchmark for High-Speed Maneuvers

Event-based cameras are bio-inspired sensors with pixels that independently and asynchronously respond to brightness changes at microsecond resolution, offering the potential to handle visual tasks in high-speed maneuvering scenarios. Existing event-based approaches, although successful in mitigating motion blur caused by high-speed maneuvers, suffer from many limitations. Some of them highlight a success of pose tracking for a fronto-parallel fast shaking camera closed to the structure, while others assume pure (optionally aggressive) three-degreeof-freedom rotations. The former requires persistent local map visibility within the field of view (FOV), whereas the latter fails to generalize to six-degree-of-freedom (6-DoF) motions where both linear and angular velocities may be large. Consequently, current successes do not fully demonstrate that event-based state estimation under arbitrary aggressive maneuvers is a fully solved problem. To quantitatively assess the extent to which the potential of event cameras has been unlocked, we conduct a thorough analysis of state-of-the-art (SOTA) event-based visual odometry (VO)/visual-inertial odometry (VIO) methods and report shortcomings in current public datasets. Furthermore, we introduce a benchmarking framework for event-based state estimation, called EvSLAM, characterized by sufficient variation in data collection platforms, diverse extreme lighting scenarios, and a wide scope of challenging motion patterns under a clear and rigorous definition of high-speed maneuvers for mobile robots, along with a novel evaluation metric designed to fairly assess the operational limits of event-based solutions. This framework benchmarks state-ofthe-art methods, yielding insights into optimal architectures and persistent challenges.
References
Maximizing Asynchronicity in Event-based Neural Networks
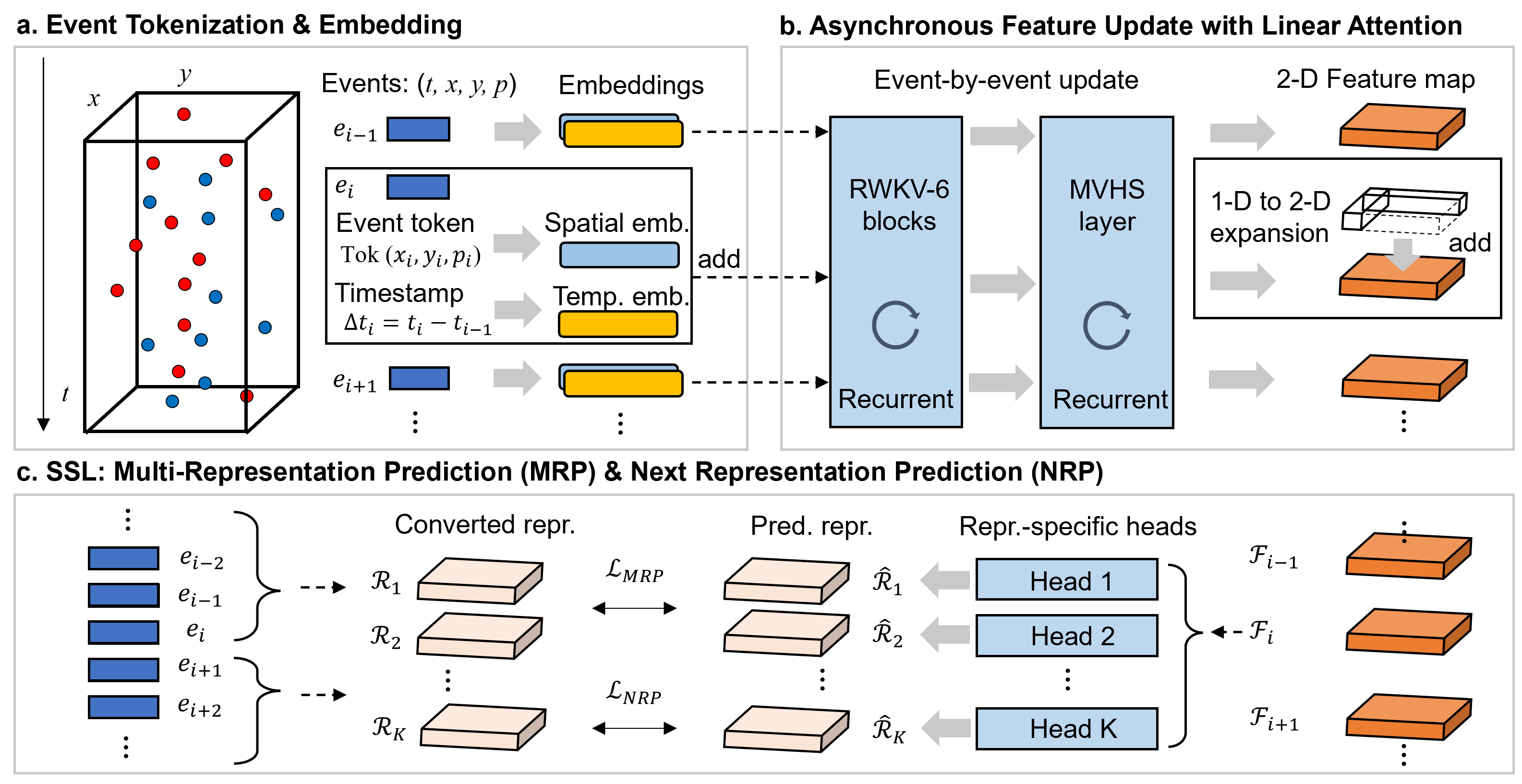
Event cameras deliver visual data with high temporal resolution, low latency, and minimal redundancy, yet their asynchronous, sparse sequential nature challenges standard tensor-based machine learning (ML). While the recent asynchronous-to-synchronous (A2S) paradigm aims to bridge this gap by asynchronously encoding events into learned features for ML pipelines, existing A2S approaches often sacrifice expressivity and generalizability compared to dense, synchronous methods. This paper introduces EVA (EVent Asynchronous feature learning), a novel A2S framework to generate highly expressive and generalizable event-by-event features. Inspired by the analogy between events and language, EVA uniquely adapts advances from language modeling in linear attention and self-supervised learning for its construction. In demonstration, EVA outperforms prior A2S methods on recognition tasks (DVS128-Gesture and N-Cars), and represents the first A2S framework to successfully master demanding detection tasks, achieving a 0.477 mAP on the Gen1 dataset. These results underscore EVA's potential for advancing real-time event-based vision applications.
References
Generative Event Pretraining with Foundation Model Alignment
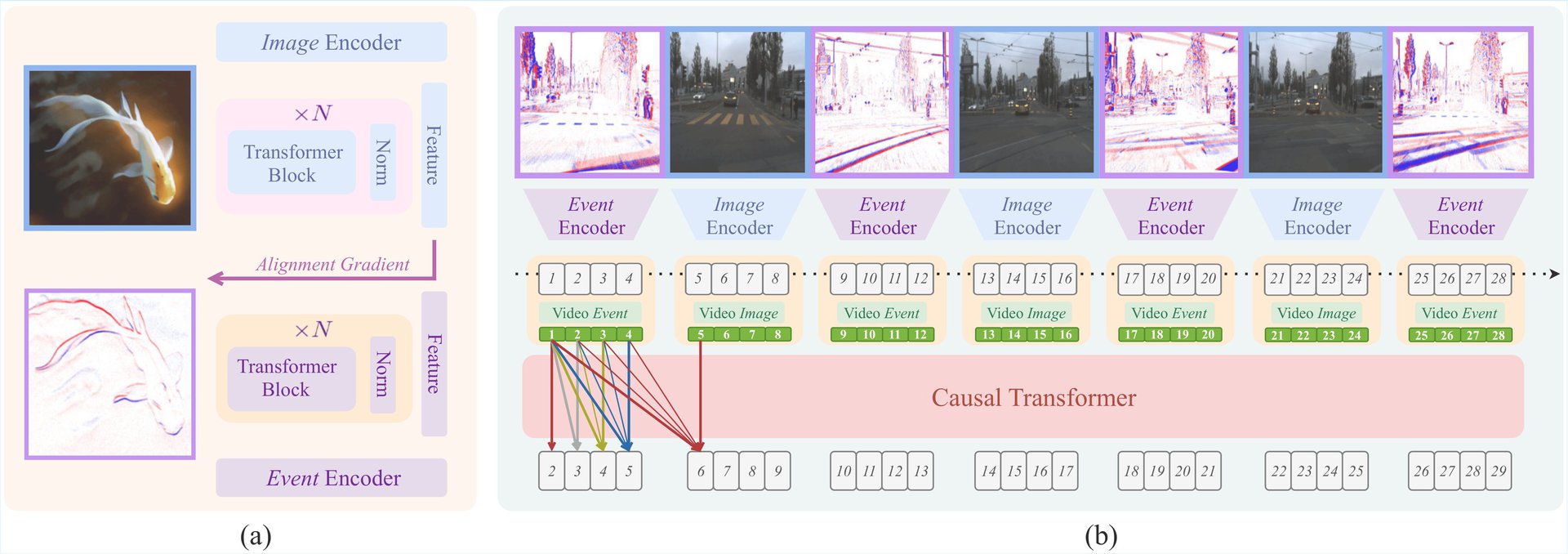
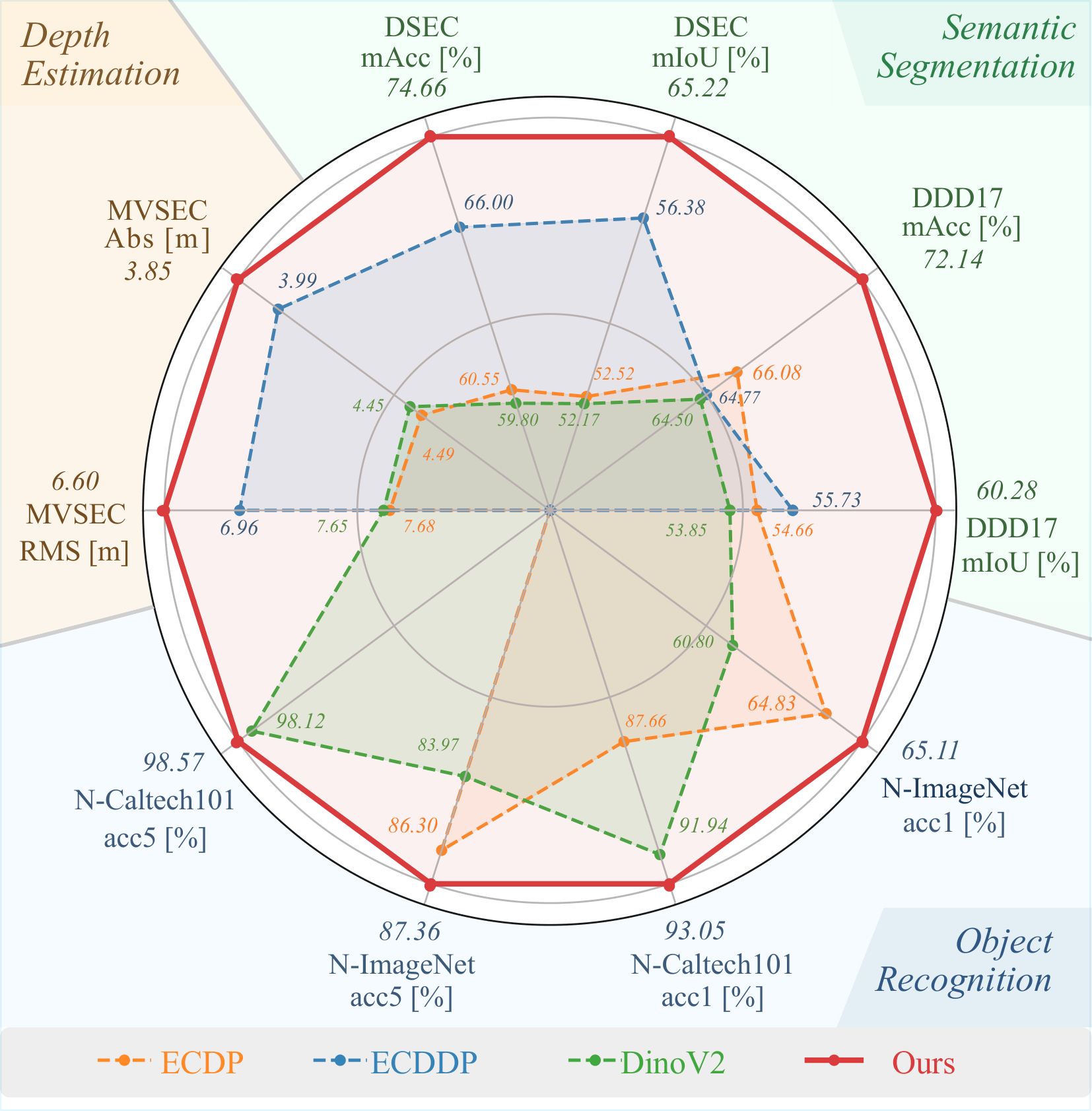
Event cameras provide robust visual signals under fast motion and challenging illumination thanks to their microsec- ond latency and high dynamic range. However, their unique sensing characteristics and limited labeled data make it challenging to train event-based visual foundation models (VFMs), which are crucial for learning visual features transferable across tasks. To tackle this problem, we propose GEP (Generative Event Pretraining), a two-stage framework that transfers semantic knowledge learned from internet-scale image datasets to event data while learning event-specific temporal dynamics. First, an event encoder is aligned to a frozen VFM through a joint regression-contrastive objective, grounding event features in image semantics. Second, a transformer backbone is autoregressively pretrained on mixed event-image sequences to capture the temporal structure unique to events. Our approach outperforms state-of-the-art event pretraining methods on a diverse range of downstream tasks, including object recognition, segmentation, and depth estimation. Together, VFM-guided alignment and generative sequence modeling yield a semantically rich, temporally aware event model that generalizes robustly across domains.
References
Low-latency Event-based Object Detection with Spatially-Sparse Linear Attention
Event cameras provide sequential visual data with spatial sparsity and high temporal resolution, making them attractive for low-latency object detection. Existing asynchronous event-based neural networks realize this low-latency advantage by updating predictions event-by-event, but still suffer from two bottlenecks: recurrent architectures are difficult to train efficiently on long sequences, and improving accuracy often increases per-event computation and latency. Linear attention is appealing in this setting because it supports parallel training and recurrent inference. However, standard linear attention updates a global state for every event, yielding a poor accuracy-efficiency trade-off, which is problematic for object detection, where fine-grained representations and thus states are preferred. The key challenge is therefore to introduce sparse state activation that exploits event sparsity while preserving efficient parallel training. We propose Spatially-Sparse Linear Attention (SSLA), which introduces a mixture-of-spaces state decomposition and a scatter-compute-gather training procedure, enabling state-level sparsity as well as training parallelism. Built on SSLA, we develop an end-to-end asynchronous linear attention model, SSLA-Det, for event-based object detection. On Gen1 and N-Caltech101, SSLA-Det achieves state-of-the-art accuracy among asynchronous methods, reaching 0.375 mAP and 0.515 mAP, respectively, while reducing per-event computation by more than 20 times compared to the strongest prior asynchronous baseline, demonstrating the potential of linear attention for low-latency event-based vision.
References

Approximate Imitation Learning for Event-based Quadrotor Flight in Cluttered Environments
Event cameras offer high temporal resolution and low latency, making them ideal sensors for high-speed robotic applications where conventional cameras suffer from image degradations such as motion blur. In addition, their low power consumption can enhance endurance, which is critical for resource-constrained platforms. Motivated by these properties, we present a novel approach that enables a quadrotor to fly through cluttered environments at high speed by perceiving the environment with a single event camera. Our proposed method employs an end-to-end neural network trained to map event data directly to control commands, eliminating the reliance on standard cameras. To enable efficient training in simulation, where rendering synthetic event data is computationally expensive, we propose Approximate Imitation Learning, a novel imitation learning framework. Our a pproach leverages a large-scale offline dataset to learn a task-specific representation space. Subsequently, the policy is trained through online interactions that rely solely on lightweight, simulated state information, eliminating the need to render events during training. This enables the efficient training of event-based control policies for fast quadrotor flight, highlighting the potential of our framework for other modalities where data simulation is costly or impractical. Our approach outperforms standard imitation learning baselines in simulation and demonstrates robust performance in real-world flight tests, achieving speeds up to 9.8 m/s in cluttered environments.
References

Motion-aware Event Suppression for Event Cameras
Event cameras report asynchronously per-pixel brightness changes with microsecond latency, encoding dynamic visual information as a sparse stream of events. However, their extreme temporal resolution floods perception systems with entangled events from ego-motion and independently moving objects (IMOs), which existing solutions fail to efficiently decouple, relying instead on prohibitive dense 3D reconstructions or limited hand-tuned filters. In this work, we introduce the first framework for Motionaware Event Suppression, which learns to filter events triggered by IMOs and ego-motion in real time. Our model jointly segments IMOs in the current event stream while predicting their future motion, enabling anticipatory suppression of dynamic events before they occur. Our lightweight architecture achieves 173 Hz inference on consumer-grade GPUs with less than 1 GB of memory usage, outperforming previous state-of-the-art methods on the challenging EVIMO benchmark by 67% in segmentation accuracy while operating at a 53% higher inference rate. Moreover, we demonstrate significant benefits for downstream applications: our method accelerates Vision Transformer inference by 83% via token pruning and improves event-based visual odometry accuracy, reducing Absolute Trajectory Error (ATE) by 13%.
References

Event-Aided Sharp Radiance Field Reconstruction for Fast-Flying Drones
Fast-flying aerial robots promise rapid inspection under limited battery constraints, with direct applications in infrastructure inspection, terrain exploration, and search and rescue. However, high speeds lead to severe motion blur in images and induce significant drift and noise in pose estimates, making dense 3D reconstruction with Neural Radiance Fields (NeRFs) particularly challenging due to their high sensitivity to such degradations. In this work, we present a unified framework that leverages asynchronous event streams alongside motion-blurred frames to reconstruct high-fidelity radiance fields from agile drone flights. By embedding event-image fusion into NeRF optimization and jointly refining event-based visual-inertial odometry priors using both event and frame modalities, our method recovers sharp radiance fields and accurate camera trajectories without ground-truth supervision. We validate our approach on both synthetic data and real-world sequences captured by a fast-flying drone. Despite highly dynamic drone flights, where RGB frames are severely degraded by motion blur and pose priors become unreliable, our method reconstructs high-fidelity radiance fields and preserves fine scene details, delivering a performance gain of over 50% on real-world data compared to state-of-the-art methods.
References

Low-Latency Event-Based Velocimetry for Quadrotor Control in a Narrow Pipe
Autonomous quadrotor flight in confined spaces such as pipes and tunnels presents significant challenges due to unsteady, self-induced aerodynamic disturbances. Very recent advances have enabled flight in such conditions, but they either rely on constant motion through the pipe to mitigate airflow recirculation effects or suffer from limited stability during hovering. In this work, we present the first closed-loop control system for quadrotors for hovering in narrow pipes that leverages real-time flow field measurements. We develop a low-latency, event-based smoke velocimetry method that estimates local airflow at high temporal resolution. This flow information is used by a disturbance estimator based on a recurrent convolutional neural network, which infers force and torque disturbances in real time. The estimated disturbances are integrated into a learning-based controller trained via reinforcement learning. The flow-feedback control proves particularly effective during lateral translation maneuvers in the pipe cross-section. There, the real-time disturbance information enables the controller to effectively counteract transient aerodynamic effects, thereby preventing collisions with the pipe wall. To the best of our knowledge, this work represents the first demonstration of an aerial robot with closed-loop control informed by real-time flow field measurements. This opens new directions for research on flight in aerodynamically complex environments. In addition, our work also sheds light on the characteristic flow structures that emerge during flight in narrow, circular pipes, providing new insights at the intersection of robotics and fluid dynamics.
References

Egocentric Event-Based Vision for Ping Pong Ball Trajectory Prediction

In this work, we present a real-time egocentric trajectory prediction system for table tennis using event cameras. Unlike conventional cameras, event cameras offer high temporal resolution and reduced latency, enabling accurate ball trajectory predictions shortly after the opponent's hit. The system uses data from Meta Project Aria glasses, including 3D ball trajectories and eye-gaze information, to implement a foveated vision approach. By focusing only on the viewer's gaze region, the system improves detection performance and reduces computational load by a factor of 10.81. It achieves a worst-case latency of just 4.5 ms—significantly faster than traditional 30 FPS cameras. A trajectory prediction model is then applied to forecast the ball’s future 3D path. This is the first method to use event cameras for egocentric table tennis trajectory prediction. For more details, check out our paper and code!
References
Reading in the Dark with Foveated Event Vision
In this work, we introduce a novel event-based Optical Character Recognition (OCR) system for smart glasses that overcomes the limitations of traditional RGB cameras in low-light and high-speed conditions. By leveraging event cameras and eye-gaze data to foveate the visual input, the system drastically reduces bandwidth usage, by approximately 98%, while maintaining performance in challenging environments. It uses deep binary reconstruction trained on synthetic data and integrates multimodal large language models (LLMs) for OCR, outperforming conventional methods. The system can read text in low-light settings where RGB cameras fail, using up to 2,400 times less bandwidth than standard wearable RGB cameras. For more details, check out our paper!
References

Reading in the Dark with Foveated Event Vision
IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, 2025.
GG-SSMs: Graph-Generating State Space Models

State Space Models (SSMs) are powerful tools for modeling sequential data in computer vision and time series analysis domains. However, traditional SSMs are limited by fixed, one-dimensional sequential processing, which restricts their ability to model non-local interactions in high-dimensional data. While methods like Mamba and VMamba introduce selective and flexible scanning strategies, they rely on predetermined paths, which fails to efficiently capture complex dependencies. We introduce Graph-Generating State Space Models (GG-SSMs), a novel framework that overcomes these limitations by dynamically constructing graphs based on feature relationships. Using Chazelle's Minimum Spanning Tree algorithm, GG-SSMs adapt to the inherent data structure, enabling robust feature propagation across dynamically generated graphs and efficiently modeling complex dependencies. We validate GG-SSMs on 11 diverse datasets, including event-based eye-tracking, ImageNet classification, optical flow estimation, and six time series datasets. GG-SSMs achieve state-of-the-art performance across all tasks, surpassing existing methods by significant margins. Specifically, GG-SSM attains a top-1 accuracy of 84.9% on ImageNet, outperforming prior SSMs by 1%, reducing the KITTI-15 error rate to 2.77%, and improving eye-tracking detection rates by up to 0.33% with fewer parameters. These results demonstrate that dynamic scanning based on feature relationships significantly improves SSMs' representational power and efficiency, offering a versatile tool for various applications in computer vision and beyond.
References
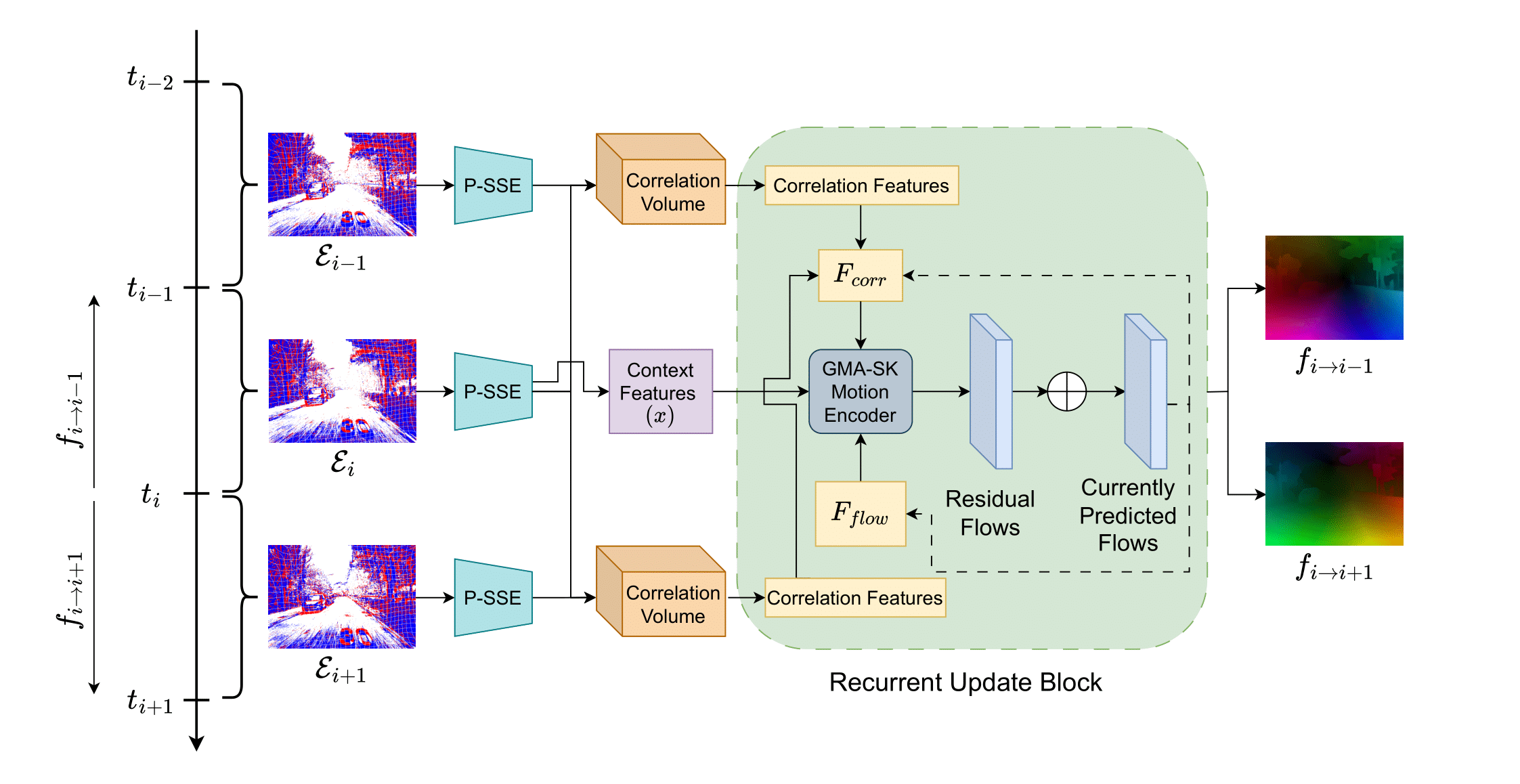
Perturbed State Space Feature Encoders for Optical Flow with Event Cameras
With their motion-responsive nature, event-based cameras offer significant advantages over traditional cameras for optical flow estimation. While deep learning has improved upon traditional methods, current neural networks adopted for event-based optical flow still face temporal and spatial reasoning limitations. We propose Perturbed State Space Feature Encoders (P-SSE) for multi-frame optical flow with event cameras to address these challenges. P-SSE adaptively processes spatiotemporal features with a large receptive field akin to Transformer-based methods, while maintaining the linear computational complexity characteristic of SSMs. However, the key innovation that enables the state-of-the-art performance of our model lies in our perturbation technique applied to the state dynamics matrix governing the SSM system. This approach significantly improves the stability and performance of our model. We integrate P-SSE into a framework that leverages bi-directional flows and recurrent connections, expanding the temporal context of flow prediction. Evaluations on DSEC-Flow and MVSEC datasets showcase P-SSE's superiority, with 8.48% and 11.86% improvements in EPE performance, respectively.
References
Perturbed State Space Feature Encoders for Optical Flow with Event Cameras
IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, 2025.
A Monocular Event-Camera Motion Capture System

Motion capture systems are a widespread tool in research to record ground-truth poses of objects. Commercial systems use reflective markers attached to the object and then triangulate pose of the object from multiple camera views. Consequently, the object must be visible to multiple cameras which makes such multi-view motion capture systems unsuited for deployments in narrow, confined spaces (e.g. ballast tanks of ships). In this technical report we describe a monocular event- camera motion capture system which overcomes this limitation and is ideally suited for narrow spaces. Instead of passive markers it relies on active, blinking LED markers such that each marker can be uniquely identified from the blinking frequency. The markers are placed at known locations on the tracking object. We then solve the PnP (perspective-n-points) problem to obtain the position and orientation of the object. The developed system has millimeter accuracy, millisecond latency and we demonstrate that its state estimate can be used to fly a small, agile quadrotor.
References
Data-driven Feature Tracking for Event Cameras with and without Frames

Because of their high temporal resolution, increased resilience to motion blur, and very sparse output, event cameras have been shown to be ideal for low-latency and low-bandwidth feature tracking, even in challenging scenarios. Existing feature tracking methods for event cameras are either handcrafted or derived from first principles but require extensive parameter tuning, are sensitive to noise, and do not generalize to different scenarios due to unmodeled effects. To tackle these deficiencies, we introduce the first data-driven feature tracker for event cameras, which leverages low-latency events to track features detected in an intensity frame. We achieve robust performance via a novel frame attention module, which shares information across feature tracks. Our tracker is designed to operate in two distinct configurations: solely with events or in a hybrid mode incorporating both events and frames. The hybrid model offers two setups: an aligned configuration where the event and frame cameras share the same viewpoint, and a hybrid stereo configuration where the event camera and the standard camera are positioned side by side. This side-by-side arrangement is particularly valuable as it provides depth information for each feature track, enhancing its utility in applications such as visual odometry and simultaneous localization and mapping.
References
E-Calib: A Fast, Robust and Accurate Calibration Toolbox for Event Cameras
Event cameras triggered a paradigm shift in the computer vision community delineated by their asynchronous nature, low latency, and high dynamic range. Calibration of event cameras is always essential to account for the sensor intrinsic parameters and for 3D perception. However, conventional image-based calibration techniques are not applicable due to the asynchronous, binary output of the sensor. The current standard for calibrating event cameras relies on either blinking patterns or event-based image reconstruction algorithms. These approaches are difficult to deploy in factory settings and are affected by noise and artifacts degrading the calibration performance. To bridge these limitations, we present E-Calib, a novel, fast, robust, and accurate calibration toolbox for event cameras utilizing the asymmetric circle grid, for its robustness to out-of-focus scenes. The proposed method is tested in a variety of rigorous experiments for different event camera models, on circle grids with different geometric properties, and under challenging illumination conditions. The results show that our approach outperforms the state-of-the-art in detection success rate, reprojection error, and estimation accuracy of extrinsic parameters.
References
Monocular Event-Based Vision for Obstacle Avoidance with a Quadrotor
We present the first static-obstacle avoidance method for quadrotors using just an onboard, monocular event camera. Quadrotors are capable of fast and agile flight in cluttered environments when piloted manually, but vision-based autonomous flight in unknown environments is difficult in part due to the sensor limitations of traditional onboard cameras. Event cameras, however, promise nearly zero motion blur and high dynamic range, but produce a very large volume of events under significant ego-motion and further lack a continuous-time sensor model in simulation, making direct sim-to-real transfer not possible. By leveraging depth prediction as a pretext task in our learning framework, we can pre-train a reactive obstacle avoidance events-to-control policy with approximated, simulated events and then fine-tune the perception component with limited events-and-depth real-world data to achieve obstacle avoidance in indoor and outdoor settings. We demonstrate this across two quadrotor-event camera platforms in multiple settings and find, contrary to traditional vision-based works, that low speeds (1m/s) make the task harder and more prone to collisions, while high speeds (5m/s) result in better event-based depth estimation and avoidance. We also find that success rates in outdoor scenes can be significantly higher than in certain indoor scenes.
References

Monocular Event-Based Vision for Obstacle Avoidance with a Quadrotor
Conference on Robot Learning (CoRL), 2024
S7: Selective and Simplified State Space Layers for Sequence Modeling
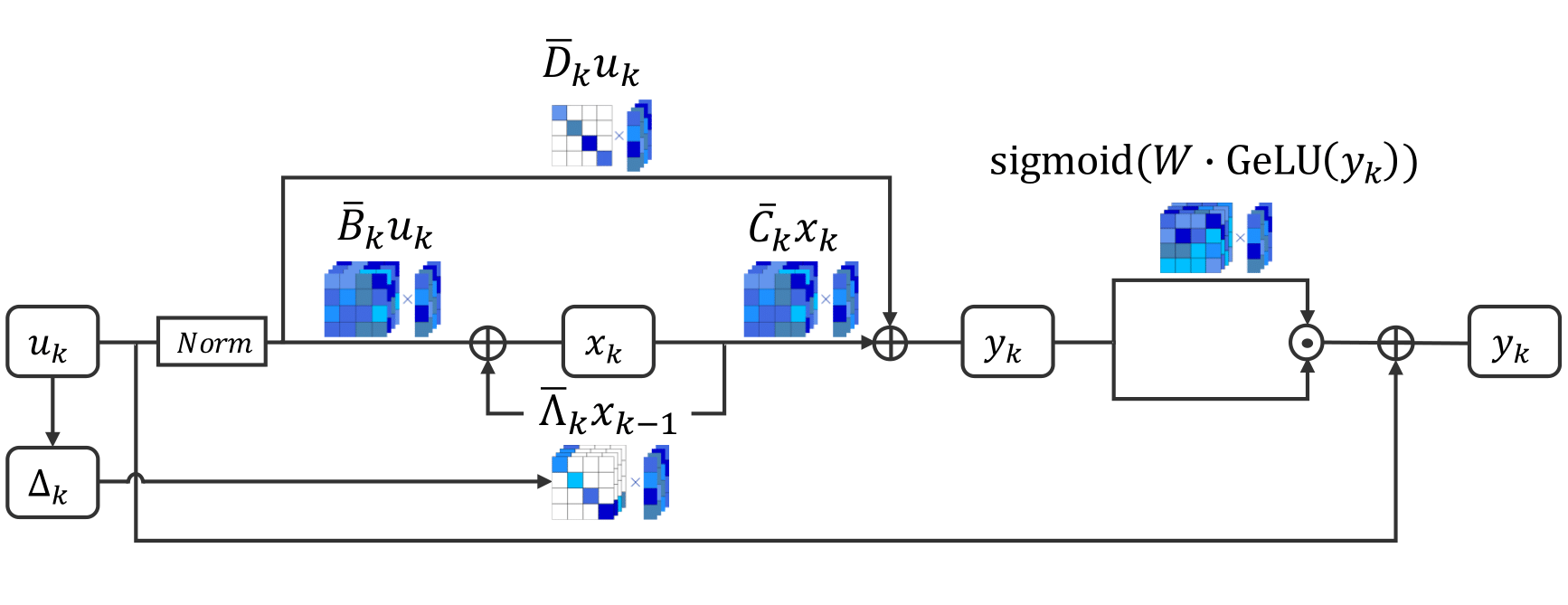
A central challenge in sequence modeling is efficiently handling tasks with extended contexts. While recent state-space models (SSMs) have made significant progress in this area, they often lack input-dependent filtering or require substantial increases in model complexity to handle input variability. We address this gap by introducing S7, a simplified yet powerful SSM that can handle input dependence while incorporating stable reparameterization and specific design choices to dynamically adjust state transitions based on input content, maintaining efficiency and performance. We prove that this reparameterization ensures stability in long-sequence modeling by keeping state transitions well-behaved over time. Additionally, it controls the gradient norm, enabling efficient training and preventing issues like exploding or vanishing gradients. S7 significantly outperforms baselines across various sequence modeling tasks, including neuromorphic event-based datasets, Long Range Arena benchmarks, and various physical and biological time series. Overall, S7 offers a more straightforward approach to sequence modeling without relying on complex, domain-specific inductive biases, achieving significant improvements across key benchmarks.
References
Deep Visual Odometry with Events and Frames
Visual Odometry (VO) is crucial for autonomous robotic navigation, especially in GPS-denied environments like planetary terrains. To improve robustness, recent model-based VO systems have begun combining standard and event-based cameras. While event cameras excel in low-light and high-speed motion, standard cameras provide dense and easier-to-track features. However, the field of image- and event-based VO still predominantly relies on model-based methods and is yet to fully integrate recent image-only advancements leveraging end-to-end learning-based architectures. Seamlessly integrating the two modalities remains challenging due to their different nature, one asynchronous, the other not, limiting the potential for a more effective image- and event-based VO. We introduce RAMP-VO, the first end-to-end learned image- and event-based VO system. It leverages novel Recurrent, Asynchronous, and Massively Parallel (RAMP) encoders capable of fusing asynchronous events with image data, providing 8x faster inference and 33% more accurate predictions than existing solutions. Despite being trained only in simulation, RAMP-VO outperforms previous methods on the newly introduced Apollo and Malapert datasets, and on existing benchmarks, where it improves image- and event-based methods by 58.8% and 30.6%, paving the way for robust and asynchronous VO in space.
References
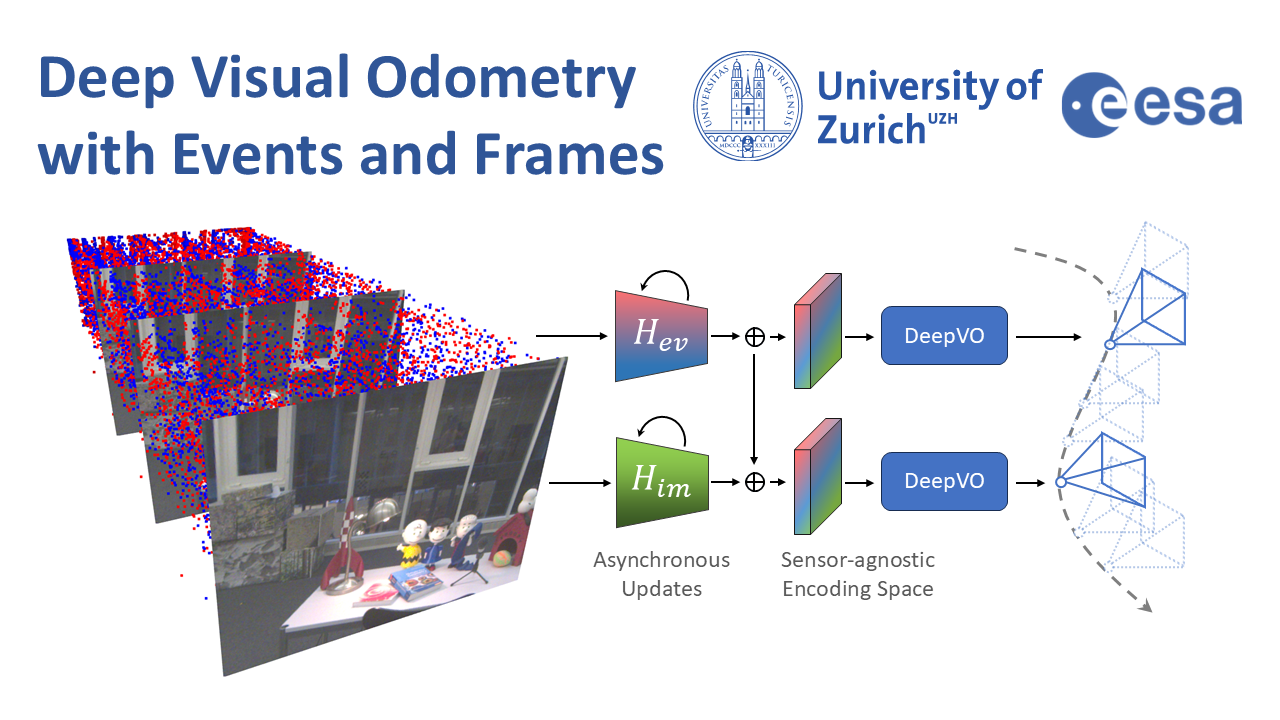
Deep Visual Odometry with Events and Frames
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024.
Low Latency Automotive Vision with Event Cameras

The computer vision algorithms used in today's advanced driver assistance systems rely on image-based RGB cameras, leading to a critical bandwidth-latency trade-off for delivering safe driving experiences. To address this, event cameras have emerged as alternative vision sensors. Event cameras measure changes in intensity asynchronously, offering high temporal resolution and sparsity, drastically reducing bandwidth and latency requirements. Despite these advantages, event camera-based algorithms are either highly efficient but lag behind image-based ones in terms of accuracy or sacrifice the sparsity and efficiency of events to achieve comparable results. To overcome this, we propose a novel hybrid event- and frame-based object detector that preserves the advantages of each modality and thus does not suffer from this tradeoff. Our method exploits the high temporal resolution and sparsity of events and the rich but low temporal resolution information in standard images to generate efficient, high-rate object detections, reducing perceptual and computational latency. We show that the use of a 20 Hz RGB camera plus an event camera can achieve the same latency as a 5,000 Hz camera with the bandwidth of a 45 Hz camera without compromising accuracy. Our approach paves the way for efficient and robust perception in edge-case scenarios by uncovering the potential of event cameras.
References

Low Latency Automotive Vision with Event Cameras
Nature, 2024.
PDF Open Access Code Training code Dataset Dataset Helper Tools YouTube
Event Cameras Meet SPADs for High-Speed, Low-Bandwidth Imaging
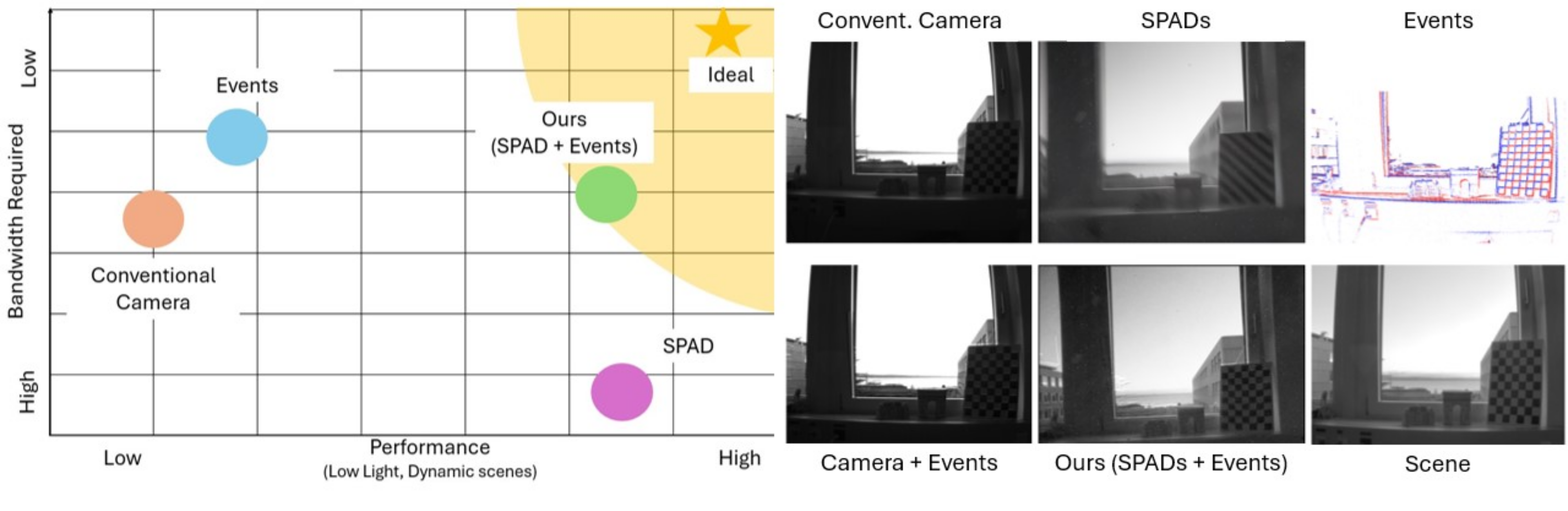
Traditional cameras face a trade-off between low-light performance and high-speed imaging: longer exposure times to capture sufficient light results in motion blur, whereas shorter exposures result in Poisson-corrupted noisy images. While burst photography techniques help mitigate this tradeoff, conventional cameras are fundamentally limited in their sensor noise characteristics. Event cameras and single-photon avalanche diode (SPAD) sensors have emerged as promising alternatives to conventional cameras due to their desirable properties. SPADs are capable of single-photon sensitivity with microsecond temporal resolution, and event cameras can measure brightness changes up to 1 MHz with low bandwidth requirements. We show that these properties are complementary, and can help achieve low-light, high-speed image reconstruction with low bandwidth requirements. We introduce a sensor fusion framework to combine SPADs with event cameras to improves the reconstruction of high-speed, low-light scenes while reducing the high bandwidth cost associated with using every SPAD frame. Our evaluation, on both synthetic and real sensor data, demonstrates significant enhancements (>5dB PSNR) in reconstructing low-light scenes at high temporal resolution (100 kHz) compared to conventional cameras. Event-SPAD fusion shows great promise for real-world applications, such as robotics or medical imaging.
References
State Space Models for Event Cameras
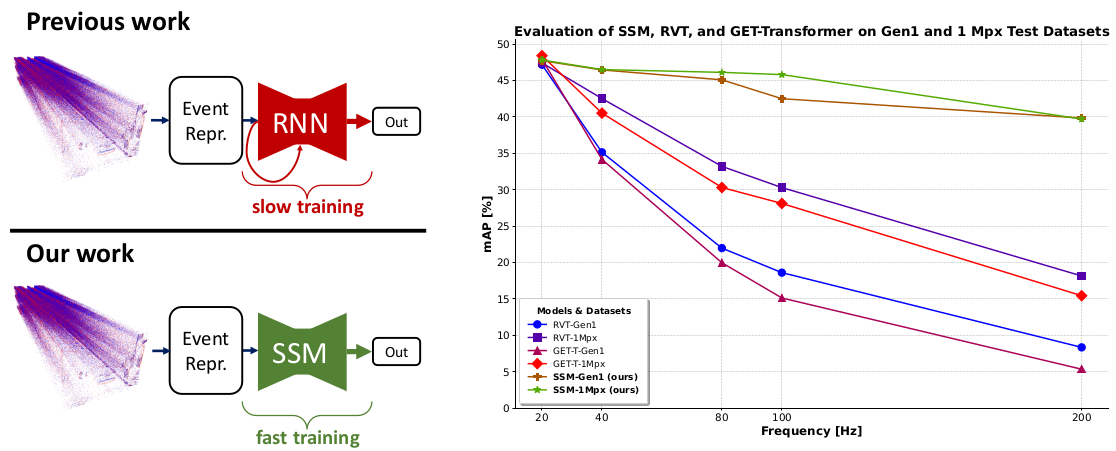
Today, state-of-the-art deep neural networks that process event-camera data first convert a temporal window of events into dense, grid-like input representations. As such, they exhibit poor generalizability when deployed at higher inference frequencies (i.e., smaller temporal windows) than the ones they were trained on. We address this challenge by introducing state-space models (SSMs) with learnable timescale parameters to event-based vision. This design adapts to varying frequencies without the need to retrain the network at different frequencies. Additionally, we investigate two strategies to counteract aliasing effects when deploying the model at higher frequencies. We comprehensively evaluate our approach against existing methods based on RNN and Transformer architectures across various benchmarks, including Gen1 and 1 Mpx event camera datasets. Our results demonstrate that SSM-based models train 33% faster and also exhibit minimal performance degradation when tested at higher frequencies than the training input. Traditional RNN and Transformer models exhibit performance drops of more than 20 mAP, with SSMs having a drop of 3.76 mAP, highlighting the effectiveness of SSMs in event-based vision tasks.
References
An N-Point Linear Solver for Line and Motion Estimation with Event Cameras
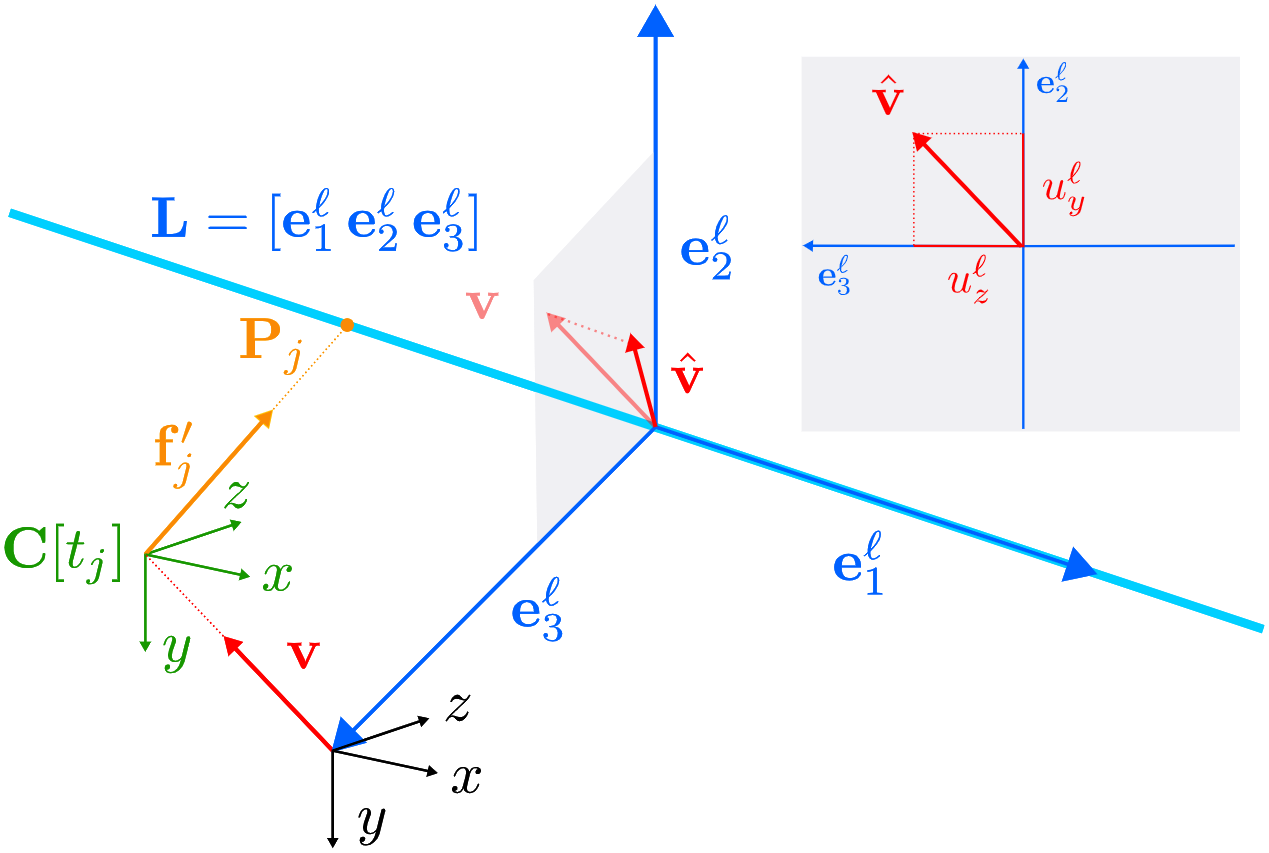
Event cameras respond primarily to edges-formed by strong gradients-and are thus particularly well-suited for line-based motion estimation. Recent work has shown that events generated by a single line each satisfy a polynomial constraint which describes a manifold in the space-time volume. Multiple such constraints can be solved simultaneously to recover the partial linear velocity and line parameters. In this work, we show that, with a suitable line parametrization, this system of constraints is actually linear in the unknowns, which allows us to design a novel linear solver. Unlike existing solvers, our linear solver (i) is fast and numerically stable since it does not rely on expensive root finding, (ii) can solve both minimal and overdetermined systems with more than 5 events (i.e. N >= 5), and (iii) admits the characterization of all degenerate cases and multiple solutions. The found line parameters are singularity-free and have a fixed scale, which eliminates the need for auxiliary constraints typically encountered in previous work. To recover the full linear camera velocity we fuse observations from multiple lines with a novel velocity averaging scheme that relies on a geometrically-motivated residual, and thus solves the problem more efficiently than previous schemes which minimize an algebraic residual. Extensive experiments in synthetic and real-world settings demonstrate that our method surpasses the previous work in numerical stability, and operates over 600 times faster.
References
An N-Point Linear Solver for Line and Motion Estimation with Event Cameras
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2024.
Oral Presentation.
Mitigating Motion Blur in Neural Radiance Fields with Events and Frames
Neural Radiance Fields (NeRFs) have shown great potential in novel view synthesis. However, they struggle to render sharp images when the data used for training is affected by motion blur. On the other hand, event cameras excel in dynamic scenes as they measure brightness changes with microsecond resolution and are thus only marginally affected by blur. Recent methods attempt to enhance NeRF reconstructions under camera motion by fusing frames and events. However, they face challenges in recovering accurate color content or constrain the NeRF to a set of predefined camera poses, harming reconstruction quality in challenging conditions. This paper proposes a novel formulation addressing these issues by leveraging both model- and learning-based modules. We explicitly model the blur formation process, exploiting the event double integral as an additional model-based prior. Additionally, we model the event-pixel response using an end-to-end learnable response function, allowing our method to adapt to non-idealities in the real event-camera sensor. We show, on synthetic and real data, that the proposed approach outperforms existing deblur NeRFs that use only frames as well as those that combine frames and events by +6.13dB and +2.48dB, respectively.
References
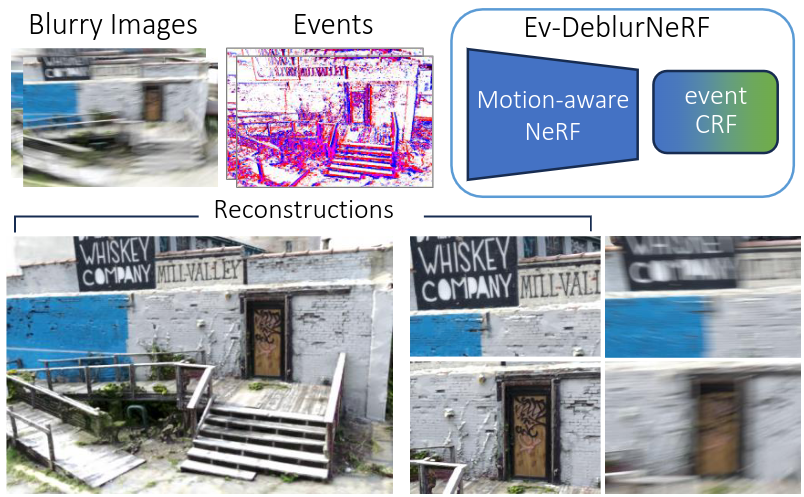
Mitigating Motion Blur in Neural Radiance Fields with Events and Frames
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2024.
Dense Continuous-Time Optical Flow from Events and Frames
We present a method for estimating dense continuous-time optical flow. Traditional dense optical flow methods compute the pixel displacement between two images. Due to missing information, these approaches cannot recover the pixel trajectories in the blind time between two images. In this work, we show that it is possible to compute per-pixel, continuous-time optical flow by additionally using events from an event camera. Events provide temporally fine-grained information about movement in image space due to their asynchronous nature and microsecond response time. We leverage these benefits to predict pixel trajectories densely in continuous-time via parameterized Bézier curves. To achieve this, we introduce multiple innovations to build a neural network with strong inductive biases for this task: First, we build multiple sequential correlation volumes in time using event data. Second, we use Bézier curves to index these correlation volumes at multiple timestamps along the trajectory. Third, we use the retrieved correlation to update the Bézier curve representations iteratively. Our method can optionally include image pairs to boost performance further. The proposed approach outperforms existing image-based and event-based methods by 11.5 % lower EPE on DSEC-Flow. Finally, we introduce a novel synthetic dataset MultiFlow for pixel trajectory regression on which our method is currently the only successful approach.
References
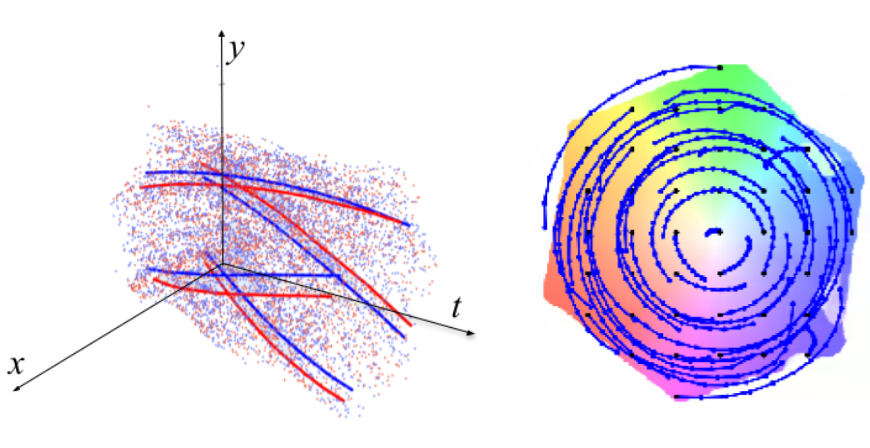
Dense Continuous-Time Optical Flow from Events and Frames
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024.
Seeing Behind Dynamic Occlusions with Event Cameras

Unwanted camera occlusions, such as debris, dust, rain-drops, and snow, can severely degrade the performance of computer-vision systems. Dynamic occlusions are particularly challenging because of the continuously changing pattern. Existing occlusion-removal methods currently use synthetic aperture imaging or image inpainting. However, they face issues with dynamic occlusions as these require multiple viewpoints or user-generated masks to hallucinate the background intensity. We propose a novel approach to reconstruct the background from a single viewpoint in the presence of dynamic occlusions. Our solution relies for the first time on the combination of a traditional camera with an event camera. When an occlusion moves across a background image, it causes intensity changes that trigger events. These events provide additional information on the relative intensity changes between foreground and background at a high temporal resolution, enabling a truer reconstruction of the background content. We show that our method outperforms image inpainting methods by 3dB in terms of PSNR on our dataset.
References
A 5-Point Minimal Solver for Event Camera Relative Motion Estimation
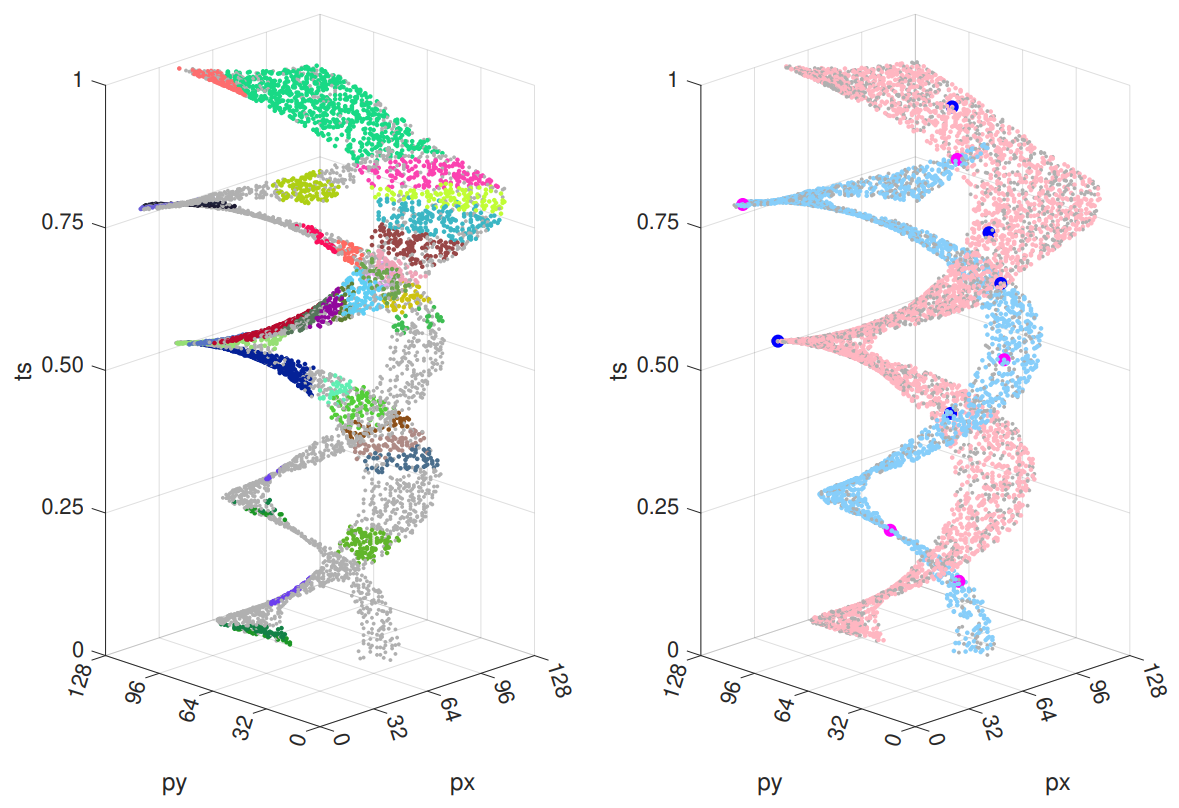
Event-based cameras are ideal for line-based motion estimation, since they predominantly respond to edges in the scene. However, accurately determining the camera displacement based on events continues to be an open problem. This is because line feature extraction and dynamics estimation are tightly coupled when using event cameras, and no precise model is currently available for describing the complex structures generated by lines in the space-time volume of events. We solve this problem by deriving the correct non-linear parametrization of such manifolds, which we term eventails, and demonstrate its application to event-based linear motion estimation, with known rotation from an Inertial Measurement Unit. Using this parametrization, we introduce a novel minimal 5-point solver that jointly estimates line parameters and linear camera velocity projections, which can be fused into a single, averaged linear velocity when considering multiple lines. We demonstrate on both synthetic and real data that our solver generates more stable relative motion estimates than other methods while capturing more inliers than clustering based on spatio-temporal planes. In particular, our method consistently achieves a 100% success rate in estimating linear velocity where existing closed-form solvers only achieve between 23% and 70%. The proposed eventails contribute to a better understanding of spatio-temporal event-generated geometries and we thus believe it will become a core building block of future event-based motion estimation algorithms.
References
A 5-Point Minimal Solver for Event Camera Relative Motion Estimation
IEEE/CVF International Conference on Computer Vision (ICCV), 2023.
Oral Presentation.
From Chaos Comes Order: Ordering Event Representations for Object Recognition and Detection
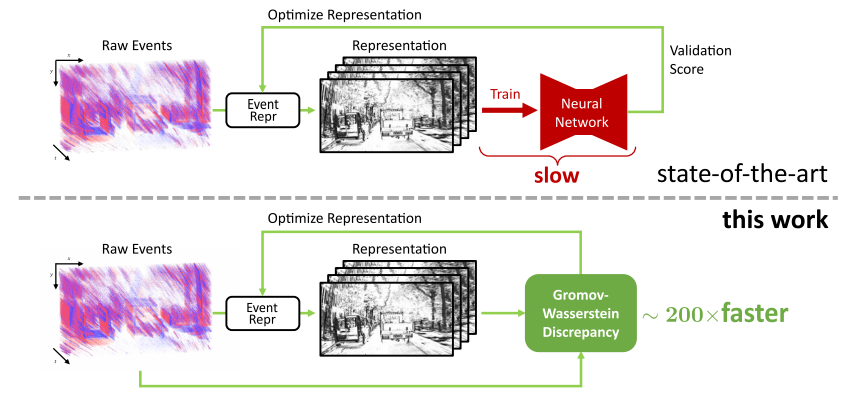
Selecting dense event representations for deep neural networks is exceedingly slow since it involves training a neural network for each representation and selecting the best one based on the validation score. In this work, we eliminate this bottleneck by selecting the representation based on the Gromov-Wasserstein Discrepancy (GWD) on the validation set. This metric is 200 times faster to compute and preserves the task performance ranking of event representations across multiple representations, network backbones, datasets and tasks. We use it to, for the first time, perform a hyperparameter search on a large family of event representations, revealing new and powerful event representations that exceed the state-of-the-art. Our optimized representations outperform existing representations by 1.7 mAP on the 1 Mpx dataset and 0.3 mAP on the Gen1 dataset, two established object detection benchmarks, and reach a 3.8% higher classification score on the mini N-ImageNet benchmark. Moreover, we outperform state-of-the-art by 2.1 mAP on Gen1 and state-of-the-art feed-forward methods by 6.0 mAP on the 1 Mpx datasets. This work opens a new unexplored field of explicit representation optimization for event-based learning.
References
E-NeRF: Neural Radiance Fields from a Moving Event Camera
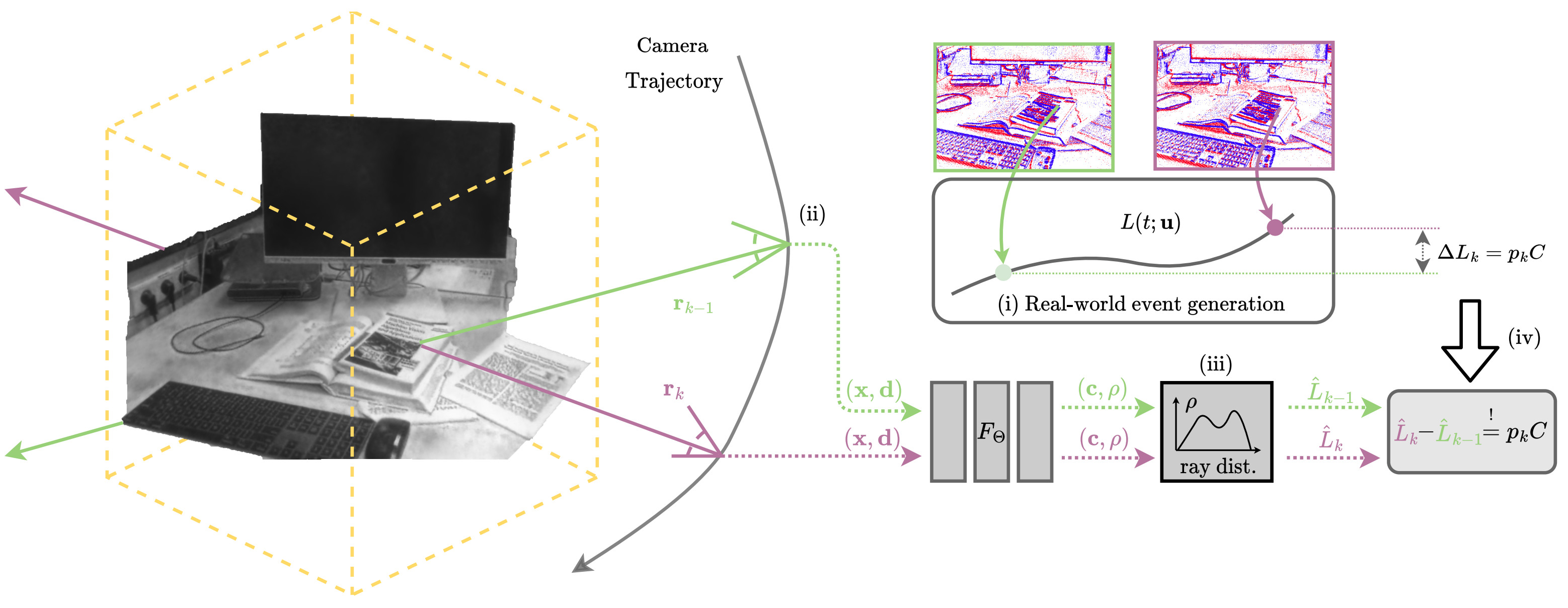
Estimating neural radiance fields (NeRFs) from "ideal" images has been extensively studied in the computer vision community. Most approaches assume optimal illumination and slow camera motion. These assumptions are often violated in robotic applications, where images may contain motion blur, and the scene may not have suitable illumination. This can cause significant problems for downstream tasks such as navigation, inspection, or visualization of the scene. To alleviate these problems, we present E-NeRF, the first method which estimates a volumetric scene representation in the form of a NeRF from a fast-moving event camera. Our method can recover NeRFs during very fast motion and in high-dynamic-range conditions where frame-based approaches fail. We show that rendering high-quality frames is possible by only providing an event stream as input. Furthermore, by combining events and frames, we can estimate NeRFs of higher quality than state-of-the-art approaches under severe motion blur. We also show that combining events and frames can overcome failure cases of NeRF estimation in scenarios where only a few input views are available without requiring additional regularization.
References
Neuromorphic Optical Flow and Real-time Implementation with Event Cameras
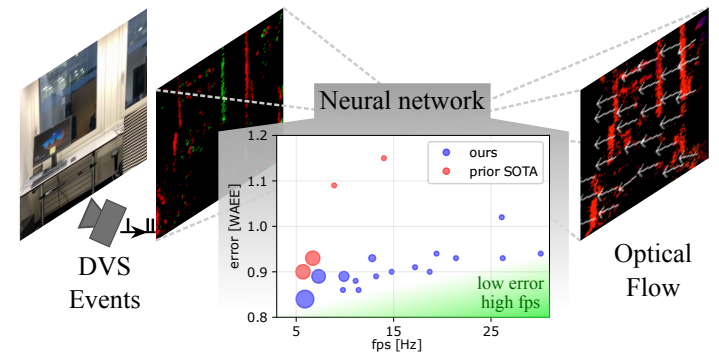
We present a new spiking neural network (SNN) architecture that significantly improves optical flow prediction accuracy while reducing complexity, making it ideal for real-time applications in edge devices and robots. By leveraging event-based vision and SNNs, our solution achieves high-speed optical flow prediction with nearly two orders of magnitude less complexity, without compromising accuracy. This breakthrough paves the way for efficient real-time deployments in various computer vision pipelines.
References
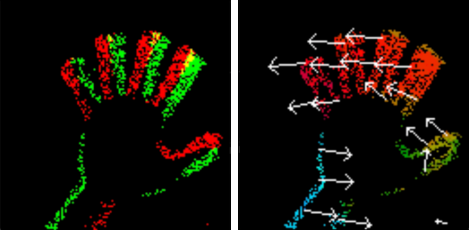
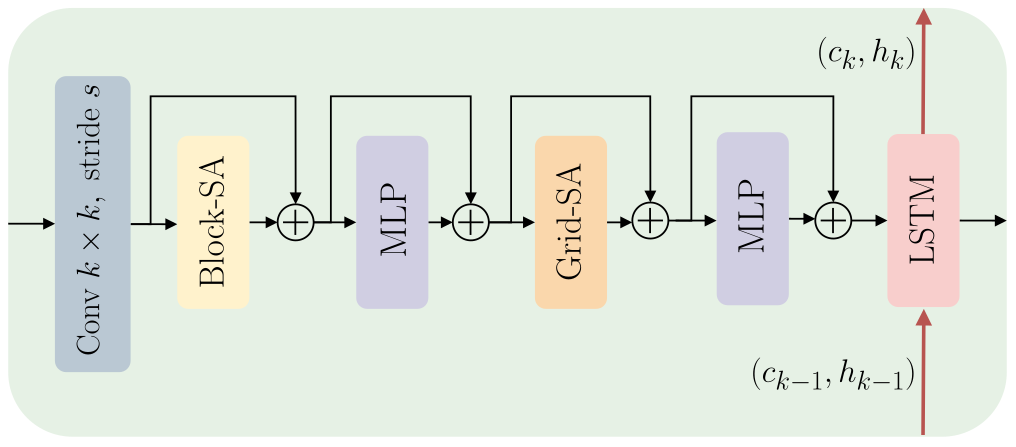
Recurrent Vision Transformers for Object Detection with Event Cameras
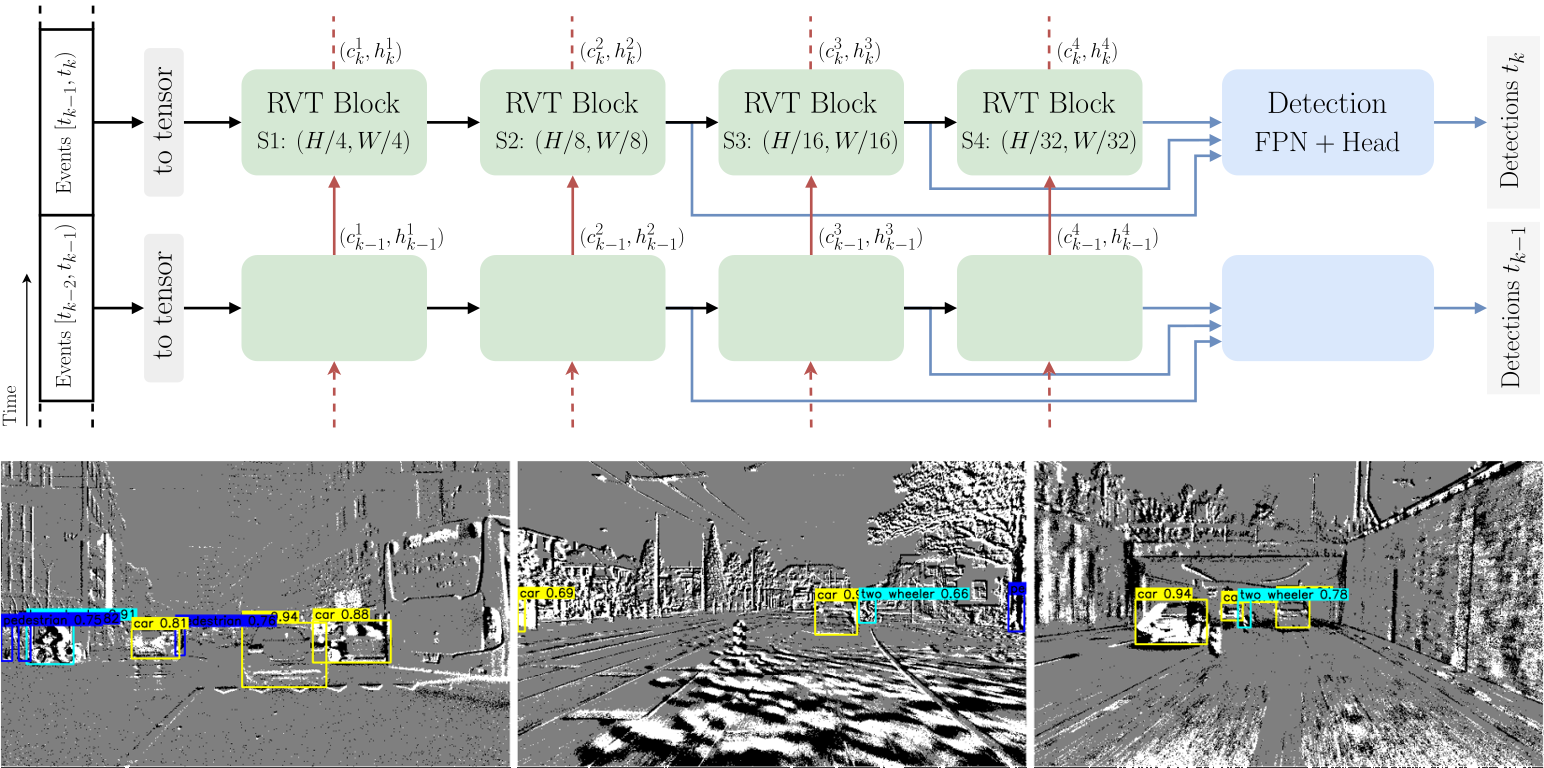
We present Recurrent Vision Transformers (RVTs), a novel backbone for object detection with event cameras. Event cameras provide visual information with sub-millisecond latency at a high-dynamic range and with strong robustness against motion blur. These unique properties offer great potential for low-latency object detection and tracking in time-critical scenarios. Prior work in event-based vision has achieved outstanding detection performance but at the cost of substantial inference time, typically beyond 40 milliseconds. By revisiting the high-level design of recurrent vision backbones, we reduce inference time by a factor of 5 while retaining similar performance. To achieve this, we explore a multi-stage design that utilizes three key concepts in each stage: First, a convolutional prior that can be regarded as a conditional positional embedding. Second, local- and dilated global self-attention for spatial feature interaction. Third, recurrent temporal feature aggregation to minimize latency while retaining temporal information. RVTs can be trained from scratch to reach state-of-the-art performance on event-based object detection - achieving an mAP of 47.2% on the Gen1 automotive dataset. At the same time, RVTs offer fast inference (12 ms on a T4 GPU) and favorable parameter efficiency (5 times fewer than prior art). Our study brings new insights into effective design choices that could be fruitful for research beyond event-based vision.
References
Data-driven Feature Tracking for Event Cameras
Because of their high temporal resolution, increased resilience to motion blur, and very sparse output, event cameras have been shown to be ideal for low-latency and low-bandwidth feature tracking, even in challenging scenarios. Existing feature tracking methods for event cameras are either handcrafted or derived from first principles but require extensive parameter tuning, are sensitive to noise, and do not generalize to different scenarios due to unmodeled effects. To tackle these deficiencies, we introduce the first data-driven feature tracker for event cameras, which leverages low-latency events to track features detected in a grayscale frame. We achieve robust performance via a novel frame attention module, which shares information across feature tracks. By directly transferring zero-shot from synthetic to real data, our data-driven tracker outperforms existing approaches in relative feature age by up to 120 % while also achieving the lowest latency. This performance gap is further increased to 130 % by adapting our tracker to real data with a novel self-supervision strategy.
References

Event-based Shape from Polarization
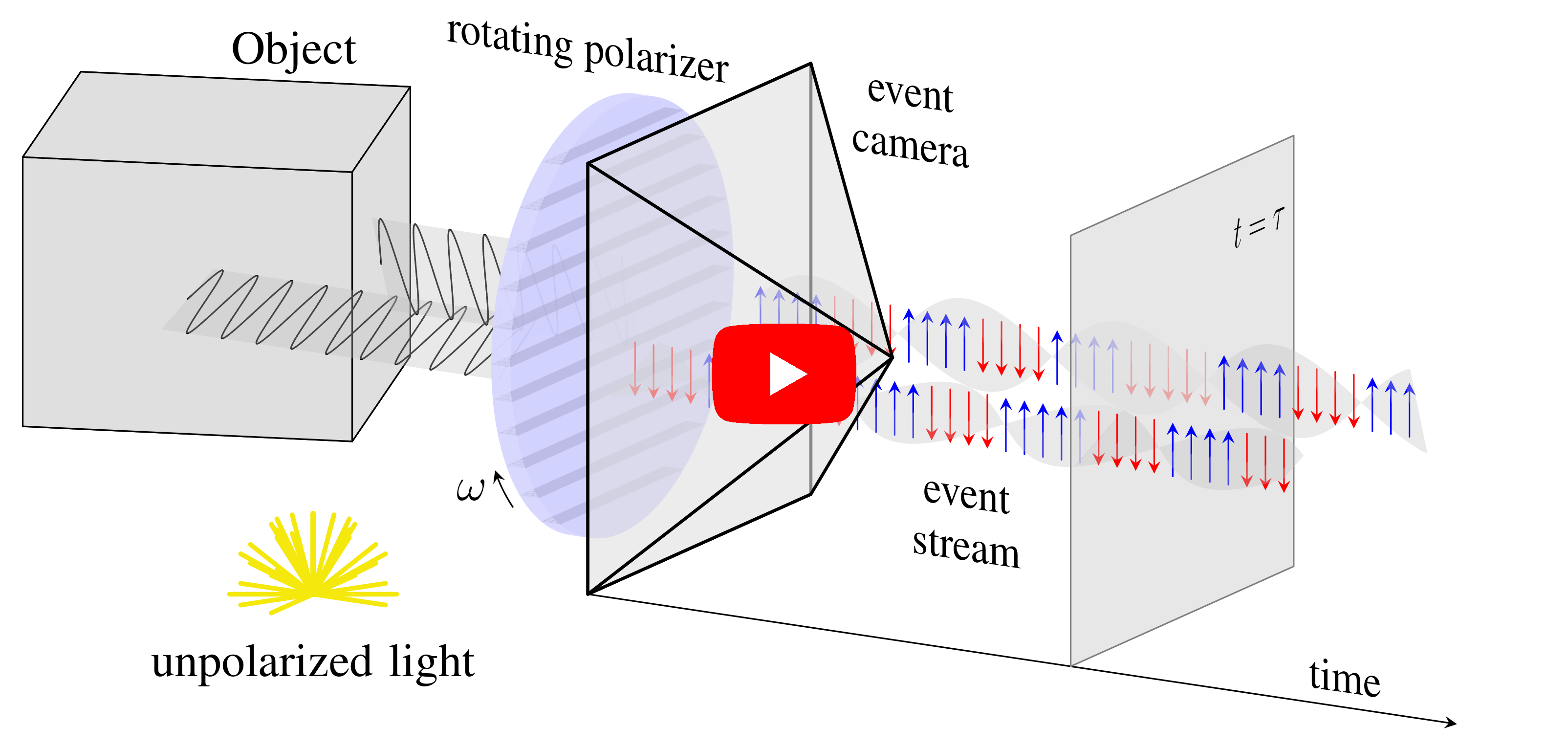
State-of-the-art solutions for Shape-from-Polarization (SfP) suffer from a speed-resolution tradeoff: they either sacrifice the number of polarization angles measured or necessitate lengthy acquisition times due to framerate constraints, thus compromising either accuracy or latency. We tackle this tradeoff using event cameras. Event cameras operate at microseconds resolution with negligible motion blur, and output a continuous stream of events that precisely measures how light changes over time asynchronously. We propose a setup that consists of a linear polarizer rotating at high-speeds in front of an event camera. Our method uses the continuous event stream caused by the rotation to reconstruct relative intensities at multiple polarizer angles. Experiments demonstrate that our method outperforms physics-based baselines using frames, reducing the MAE by 25% in synthetic and real-world dataset. In the real world, we observe, however, that the challenging conditions (i.e., when few events are generated) harm the performance of physics-based solutions. To overcome this, we propose a learning-based approach that learns to estimate surface normals even at low event-rates, improving the physics-based approach by 52% on the real world dataset. The proposed system achieves an acquisition speed equivalent to 50 fps (>twice the framerate of the commercial polarization sensor) while retaining the spatial resolution of 1MP. Our evaluation is based on the first large-scale dataset for event-based SfP.
References
Event-based Shape from Polarization
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
Event-based Agile Object Catching with a Quadrupedal Robot

Quadrupedal robots are conquering various applications in indoor and outdoor environments due to their capability to navigate challenging uneven terrains. Exteroceptive information greatly enhances this capability since perceiving their surroundings allows them to adapt their controller and thus achieve higher levels of robustness. However, sensors such as LiDARs and RGB cameras do not provide sufficient information to quickly and precisely react in a highly dynamic environment since they suffer from a bandwidth-latency tradeoff. They require significant bandwidth at high frame rates while featuring significant perceptual latency at lower frame rates, thereby limiting their versatility on resource constrained platforms. In this work, we tackle this problem by equipping our quadruped with an event camera, which does not suffer from this tradeoff due to its asynchronous and sparse operation. In levering the low latency of the events, we push the limits of quadruped agility and demonstrating high-speed ball catching with a net for the first time. We show that our quadruped equipped with an event-camera can catch objects at maximum speeds of 15 m/s from 4 meters, with a success rate of 83%. With a VGA event camera, our method runs at 100 Hz on an NVIDIA Jetson Orin.
References

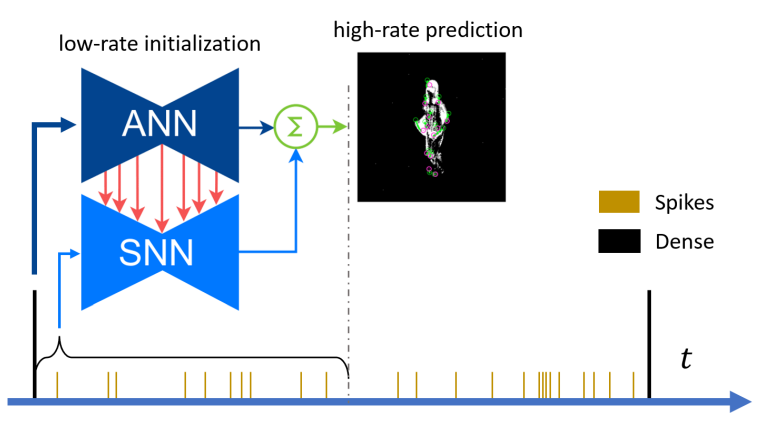
A Hybrid ANN-SNN Architecture for Low-Power and Low-Latency Visual Perception
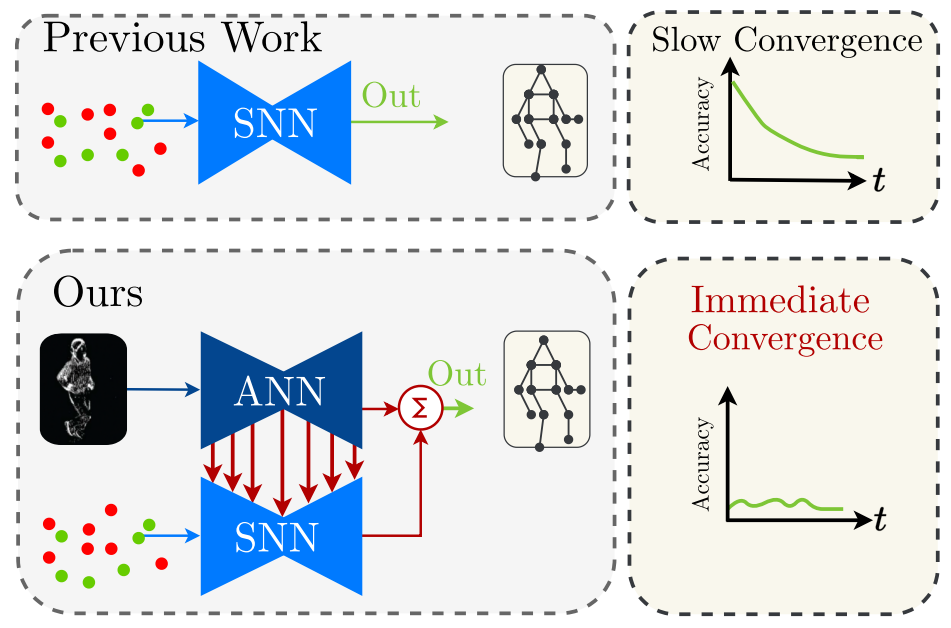
Spiking Neural Networks (SNN) are a class of bioinspired neural networks that promise to bring low-power and low-latency inference to edge-devices through the use of asynchronous and sparse processing. However, being temporal models, SNNs depend heavily on expressive states to generate predictions on par with classical artificial neural networks (ANNs). These states converge only after long transient time periods, and quickly decay in the absence of input data, leading to higher latency, power consumption, and lower accuracy. In this work, we address this issue by initializing the state with an auxiliary ANN running at a low rate. The SNN then uses the state to generate predictions with high temporal resolution until the next initialization phase. Our hybrid ANN-SNN model thus combines the best of both worlds: It does not suffer from long state transients and state decay thanks to the ANN, and can generate predictions with high temporal resolution, low latency, and low power thanks to the SNN. We show for the task of eventbased 2D and 3D human pose estimation that our method consumes 88% less power with only a 4% decrease in performance compared to its fully ANN counterparts when run at the same inference rate. Moreover, when compared to SNNs, our method achieves a 74% lower error. This research thus provides a new understanding of how ANNs and SNNs can be used to maximize their respective benefits.
References
Pushing the Limits of Asynchronous Graph-based Object Detection with Event Cameras
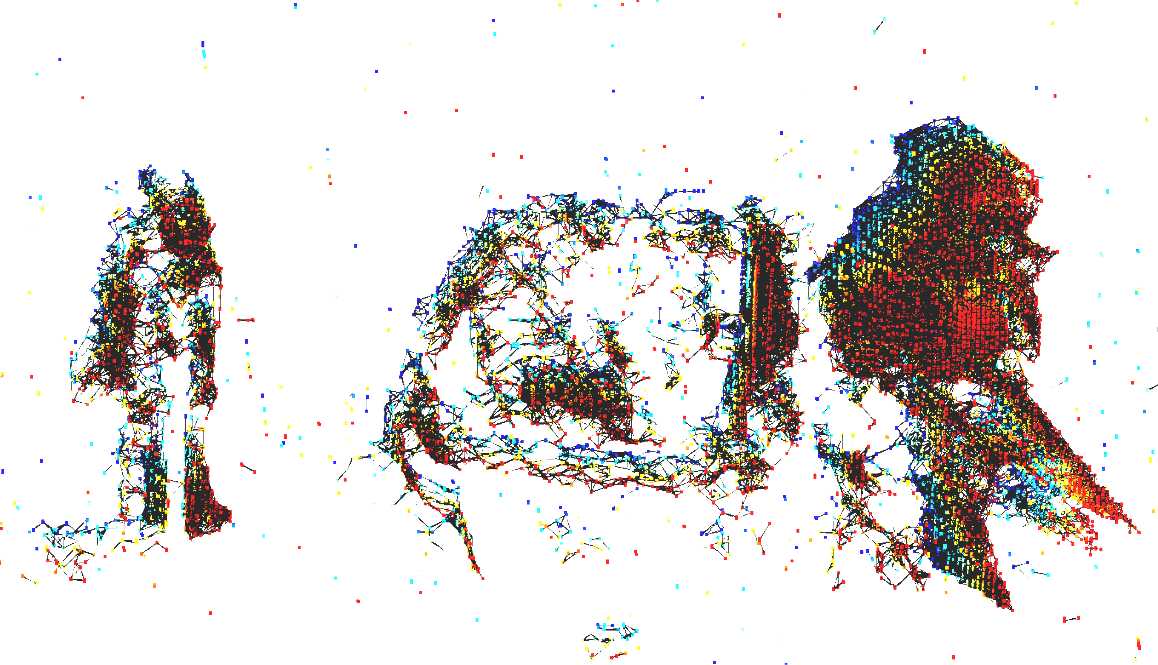
State-of-the-art machine-learning methods for event cameras treat events as dense representations and process them with conventional deep neural networks. Thus, they fail to maintain the sparsity and asynchronous nature of event data, thereby imposing significant computation and latency constraints on downstream systems. A recent line of work tackles this issue by modeling events as spatiotemporally evolving graphs that can be efficiently and asynchronously processed using graph neural networks. These works showed impressive computation reductions, yet their accuracy is still limited by the small scale and shallow depth of their network, both of which are required to reduce computation. In this work, we break this glass ceiling by introducing several architecture choices which allow us to scale the depth and complexity of such models while maintaining low computation. On object detection tasks, our smallest model shows up to 3.7 times lower computation, while outperforming state-of-the-art asynchronous methods by 7.4 mAP. Even when scaling to larger model sizes, we are 13% more efficient than state-of-the-art while outperforming it by 11.5 mAP. As a result, our method runs 3.7 times faster than a dense graph neural network, taking only 8.4 ms per forward pass. This opens the door to efficient, and accurate object detection in edge-case scenarios.
References
Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Cars
Event cameras are bio-inspired vision sensors that naturally capture the dynamics of a scene, filtering out redundant information. This paper presents a deep neural network approach that unlocks the potential of event cameras on a challenging motion-estimation task: prediction of a vehicle's steering angle. To make the best out of this sensor-algorithm combination, we adapt state-of-the-art convolutional architectures to the output of event sensors and extensively evaluate the performance of our approach on a publicly available large scale event-camera dataset (~1000 km). We present qualitative and quantitative explanations of why event cameras allow robust steering prediction even in cases where traditional cameras fail, e.g. challenging illumination conditions and fast motion. Finally, we demonstrate the advantages of leveraging transfer learning from traditional to event-based vision, and show that our approach outperforms state-of-the-art algorithms based on standard cameras.
References

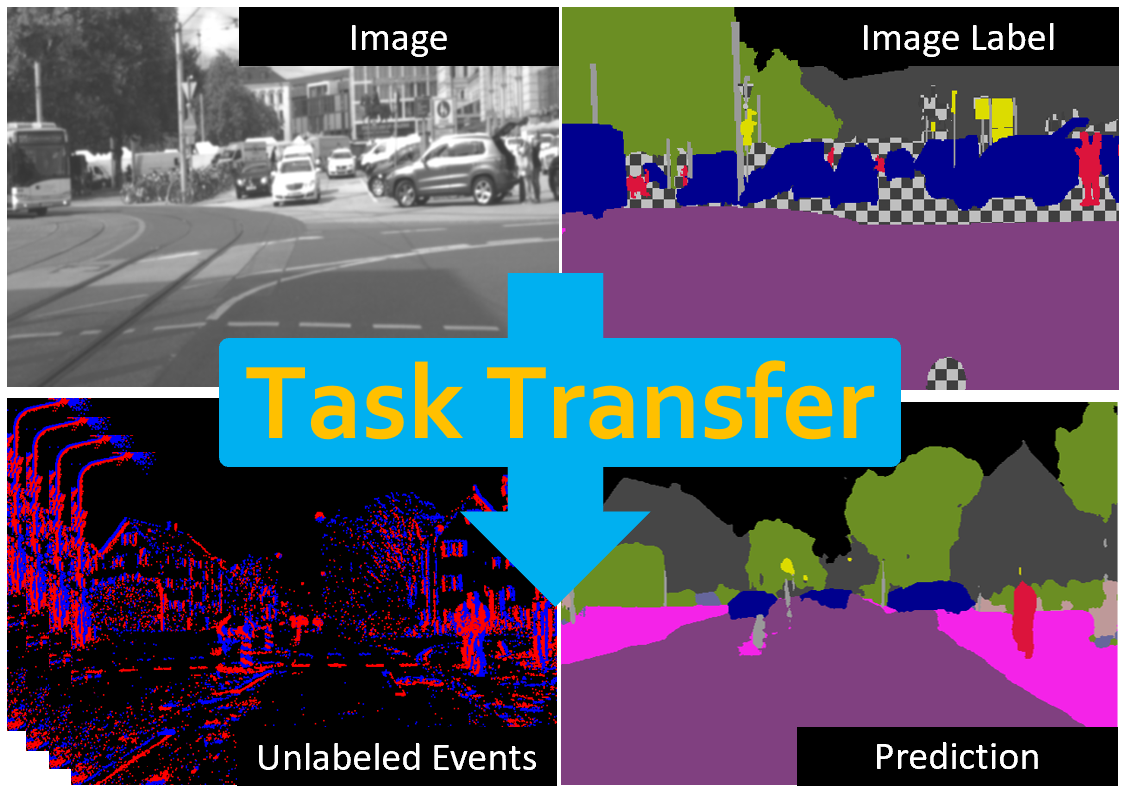
ESS: Learning Event-based Semantic Segmentation from Still Images
References
Exploring Event Camera-based Odometry for Planetary Robots
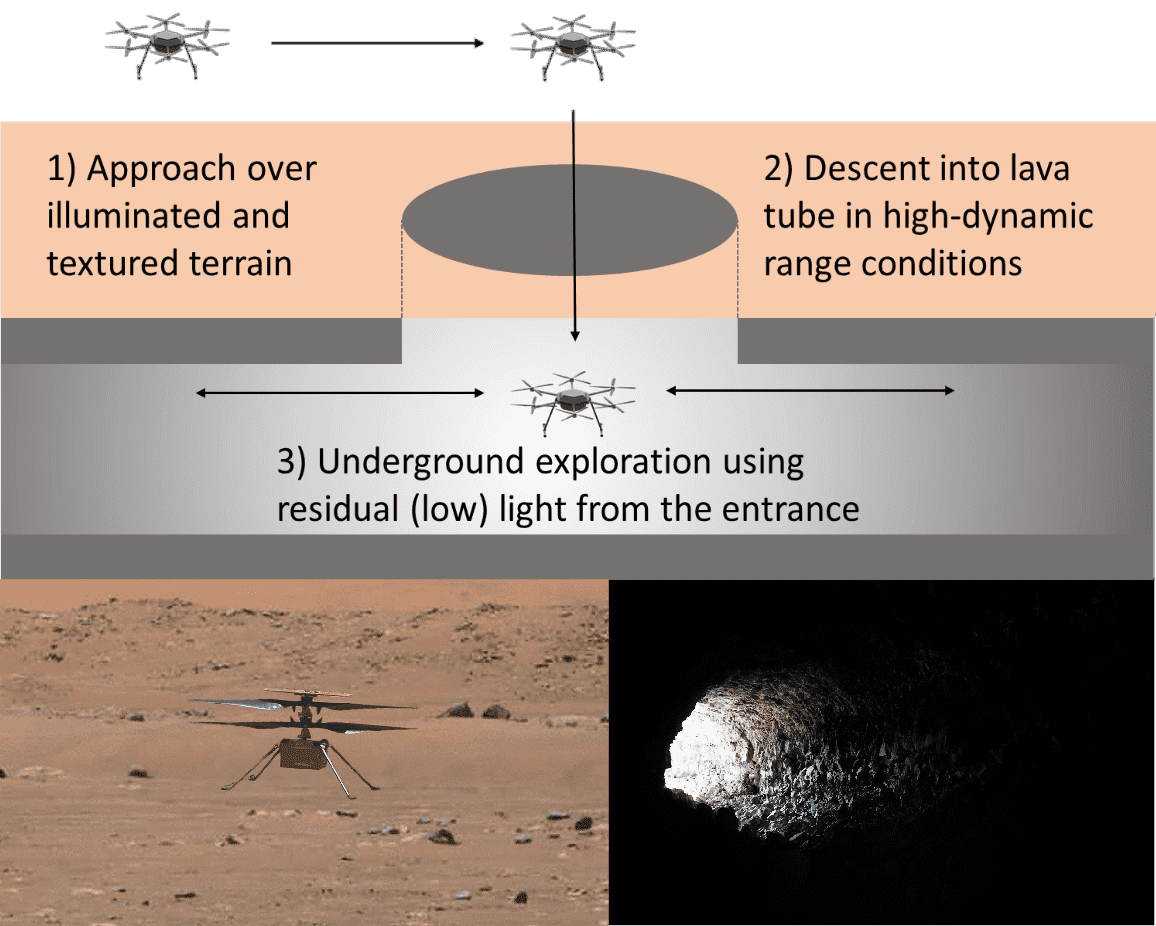
References
Exploring Event Camera-based Odometry for Planetary Robots
Robotics and Automation Letters (RAL), 2022
Multi-Bracket High Dynamic Range Imaging with Event Cameras
References

Event-aided Direct Sparse Odometry

We introduce EDS, a direct monocular visual odometry using events and frames. Our algorithm leverages the event generation model to track the camera motion in the blind time between frames. The method formulates a direct probabilistic approach of observed brightness increments. Per-pixel brightness increments are predicted using a sparse number of selected 3D points and are compared to the events via the brightness increment error to estimate camera motion. The method recovers a semi-dense 3D map using photometric bundle adjustment. EDS is the first method to perform 6-DOF VO using events and frames with a direct approach. By design it overcomes the problem of changing appearance in indirect methods. We also show that, for a target error performance, EDS can work at lower frame rates than state-of-the-art frame-based VO solutions. This opens the door to low-power motion-tracking applications where frames are sparingly triggered "on demand'' and our method tracks the motion in between. We release code and datasets to the public.
References
Time Lens++: Event-based Frame Interpolation with Parametric Non-linear Flow and Multi-scale Fusion

References
Time Lens++: Event-based Frame Interpolation with Parametric Non-linear Flow and Multi-scale Fusion
IEEE Conference of Computer Vision and Pattern Recognition (CVPR), 2022, New Orleans, USA.
AEGNN: Asynchronous Event-based Graph Neural Networks

References

AEGNN: Asynchronous Event-based Graph Neural Networks
IEEE Conference of Computer Vision and Pattern Recognition (CVPR), 2022, New Orleans, USA.
Are High-Resolution Cameras Really Needed?

References
Bridging the Gap between Events and Frames through Unsupervised Domain Adaptation
References

ESL: Event-based Structured Light

References
ESL: Event-based Structured Light
International Conference on 3D Vision (3DV), 2021.
Event Guided Depth Sensing
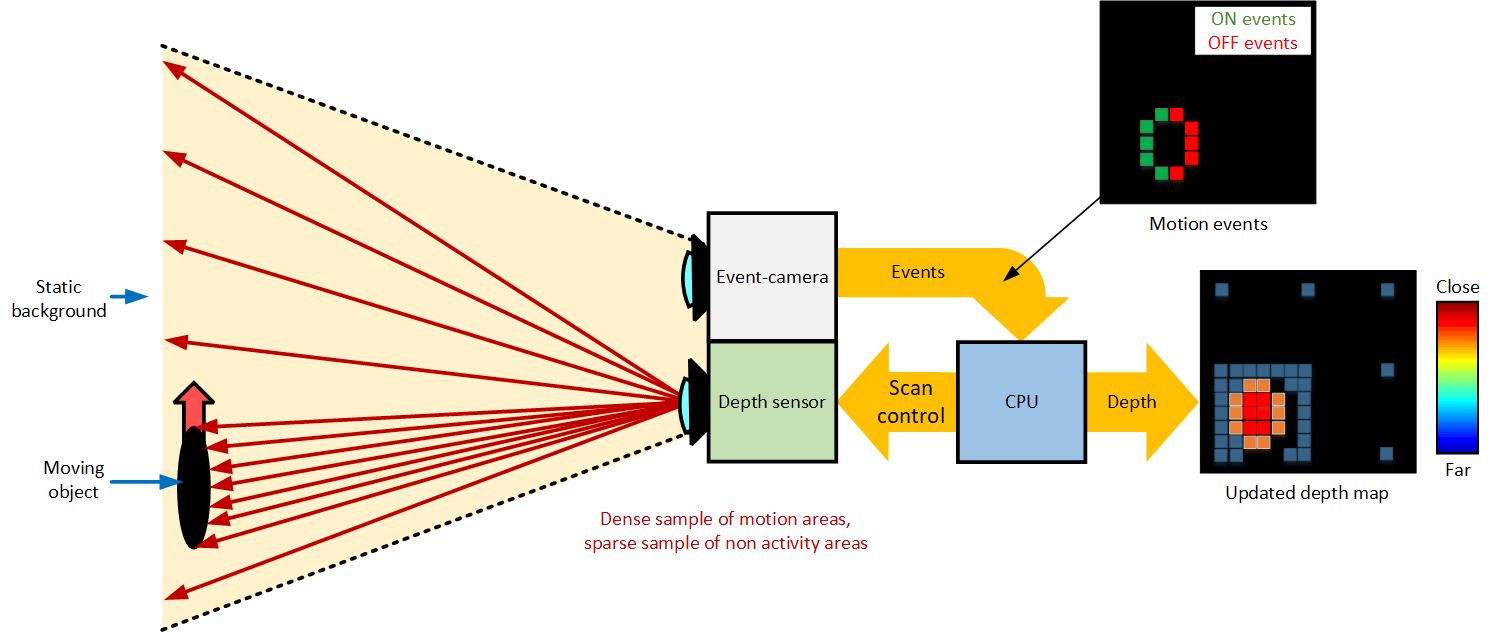
References
E-RAFT: Dense Optical Flow from Event Cameras

We propose to incorporate feature correlation and sequential processing into dense optical flow estimation from event cameras. Modern frame-based optical flow methods heavily rely on matching costs computed from feature correlation. In contrast, there exists no optical flow method for event cameras that explicitly computes matching costs. Instead, learning-based approaches using events usually resort to the U-Net architecture to estimate optical flow sparsely. Our key finding is that introducing correlation features significantly improves results compared to previous methods that solely rely on convolution layers. Compared to the state-of-the-art, our proposed approach computes dense optical flow and reduces the end-point error by 23% on MVSEC. Furthermore, we show that all existing optical flow methods developed so far for event cameras have been evaluated on datasets with very small displacement fields with a maximum flow magnitude of 10 pixels. We introduce a new real-world dataset that exhibits displacement fields with magnitudes up to 210 pixels and 3 times higher camera resolution based on this observation. Our proposed approach reduces the end-point error on this dataset by 66%.
References

Event-driven Vision and Control for UAVs on a Neuromorphic Chip
References

Powerline Tracking with Event Cameras

References

TimeLens: Event-based Video Frame Interpolation
References

TimeLens: Event-based Video Frame Interpolation
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, 2021.
How to Calibrate Your Event Camera

References
DSEC: A Stereo Event Camera Dataset for Driving Scenarios

References

DSEC: A Stereo Event Camera Dataset for Driving Scenarios
IEEE Robotics and Automation Letters (RA-L), 2021.
PDF Project Page and Dataset Code Teaser ICRA 2021 Video Pitch Slides
Combining Events and Frames using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction
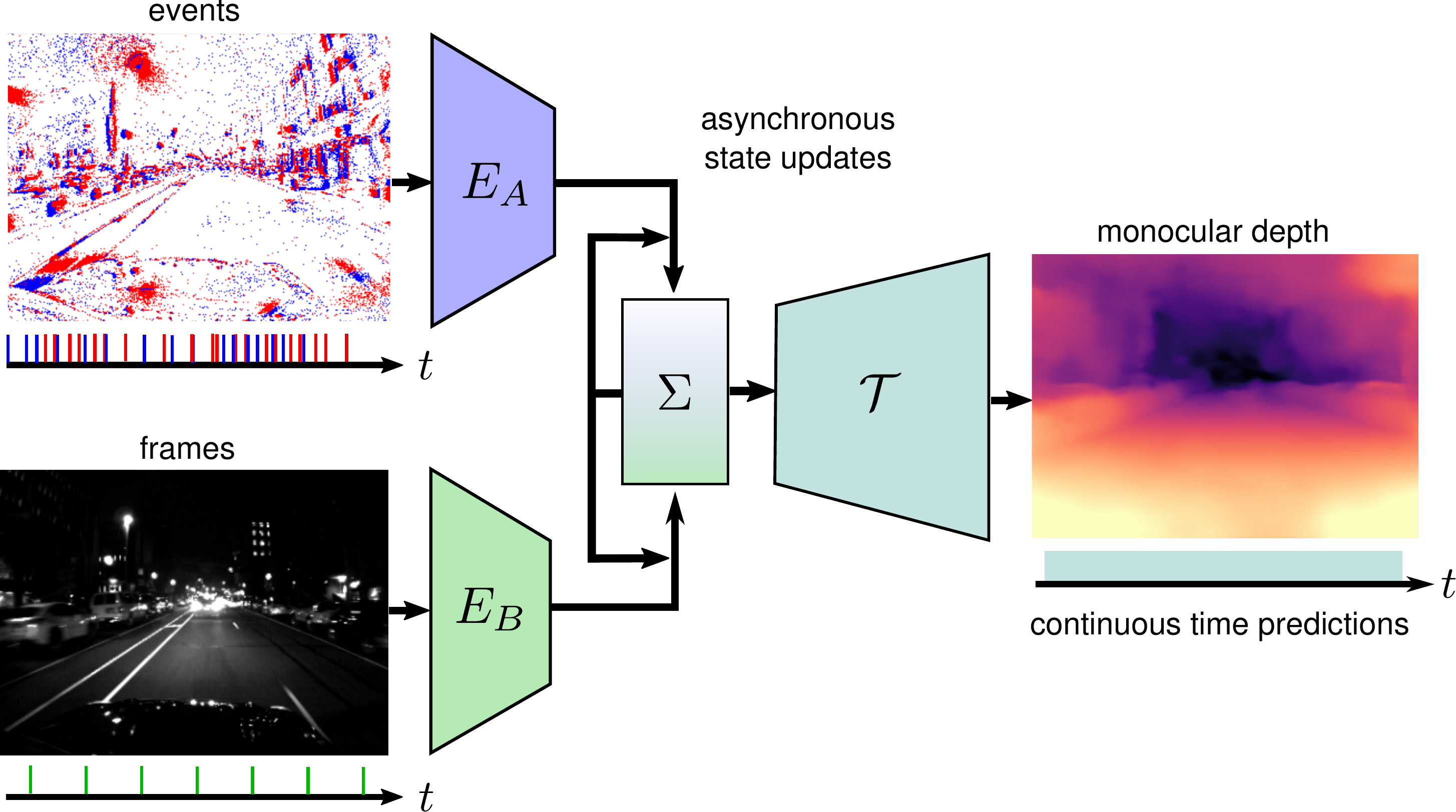
Event cameras are novel vision sensors that report per-pixel brightness changes as a stream of asynchronous "events". They offer significant advantages compared to standard cameras due to their high temporal resolution, high dynamic range and lack of motion blur. However, events only measure the varying component of the visual signal, which limits their ability to encode scene context. By contrast, standard cameras measure absolute intensity frames, which capture a much richer representation of the scene. Both sensors are thus complementary. However, due to the asynchronous nature of events, combining them with synchronous images remains challenging, especially for learning-based methods. This is because traditional recurrent neural networks (RNNs) are not designed for asynchronous and irregular data from additional sensors. To address this challenge, we introduce Recurrent Asynchronous Multimodal (RAM) networks, which generalize traditional RNNs to handle asynchronous and irregular data from multiple sensors. Inspired by traditional RNNs, RAM networks maintain a hidden state that is updated asynchronously and can be queried at any time to generate a prediction. We apply this novel architecture to monocular depth estimation with events and frames where we show an improvement over state-of-the-art methods by up to 30\% in terms of mean absolute depth error. To enable further research on multimodal learning with events, we release EventScape, a new dataset with events, intensity frames, semantic labels, and depth maps recorded in the CARLA simulator.
References
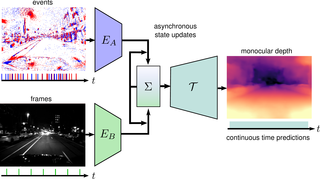
Combining Events and Frames using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction
IEEE Robotics and Automation Letters (RA-L), 2021.
Learning Monocular Dense Depth from Events
Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. Compared to conventional image sensors, they offer significant advantages: high temporal resolution, high dynamic range, no motion blur, and much lower bandwidth. Recently, learning-based approaches have been applied to event-based data, thus unlocking their potential and making significant progress in a variety of tasks, such as monocular depth prediction. Most existing approaches use standard feed-forward architectures to generate network predictions, which do not leverage the temporal consistency presents in the event stream. We propose a recurrent architecture to solve this task and show significant improvement over standard feed-forward methods. In particular, our method generates dense depth predictions using a monocular setup, which has not been shown previously. We pretrain our model using a new dataset containing events and depth maps recorded in the CARLA simulator. We test our method on the Multi Vehicle Stereo Event Camera Dataset (MVSEC). Quantitative experiments show up to 50% improvement in average depth error with respect to previous event-based methods.
References

Learning Monocular Dense Depth from Events
IEEE International Conference on 3D Vision (3DV), 2020.
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
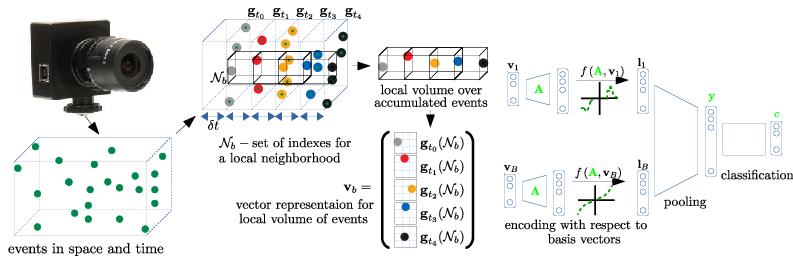
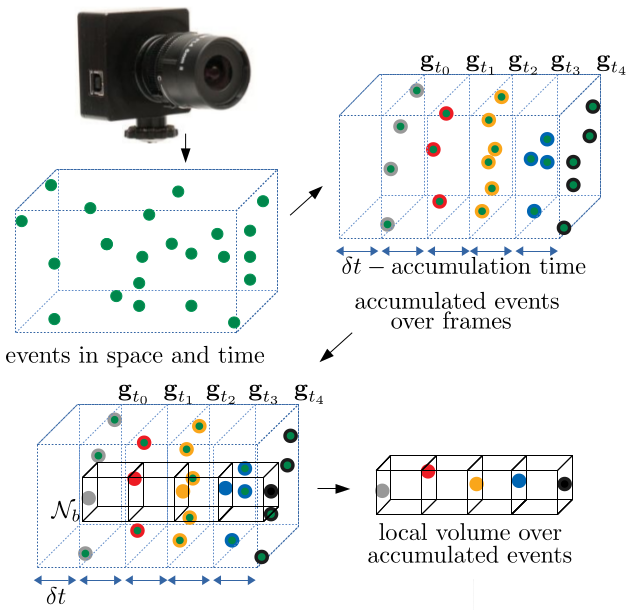
Event-based cameras record an asynchronous stream of per-pixel brightness changes. As such, they have numerous advantages over the standard frame-based cameras,including high temporal resolution, high dynamic range, and no motion blur. Due to the asynchronous nature, efficient learning of compact representation for event data is challenging. While it remains not explored the extent to which the spatial and temporal event "information" is useful for pattern recognition tasks. Inthis paper, we focus on single-layer architectures. We analyze the performance of two general problem formulations: the directand the inverse, for unsupervised feature learning from local event data (local volumes of events described in space-time).We identify and show the main advantages of each approach.Theoretically, we analyze guarantees for an optimal solution,possibility for asynchronous, parallel parameter update, and the computational complexity. We present numerical experiments for object recognition. We evaluate the solution under the direct and the inverse problem and give a comparison with the state-of-the-art methods. Our empirical results highlight the advantages of both approaches for representation learning from event data. Weshow improvements of up to 9%in the recognition accuracy compared to the state-of-the-art methods from the same class of methods.
References
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
IAPR IEEE/Computer Society International Conference on Pattern Recognition (ICPR), Milan, 2021.
Event-based Asynchronous Sparse Convolutional Networks
Event cameras are bio-inspired sensors that respond to per-pixel brightness changes in the form of asynchronous and sparse "events". Recently, pattern recognition algorithms, such as learning-based methods, have made significant progress with event cameras by converting events into synchronous dense, image-like representations and applying traditional machine learning methods developed for standard cameras. However, these approaches discard the spatial and temporal sparsity inherent in event data at the cost of higher computational complexity and latency. In this work, we present a general framework for converting models trained on synchronous image-like event representations into asynchronous models with identical output, thus directly leveraging the intrinsic asynchronous and sparse nature of the event data. We show both theoretically and experimentally that this drastically reduces the computational complexity and latency of high-capacity, synchronous neural networks without sacrificing accuracy. In addition, our framework has several desirable characteristics: (i) it exploits spatio-temporal sparsity of events explicitly, (ii) it is agnostic to the event representation, network architecture, and task, and (iii) it does not require any train-time change, since it is compatible with the standard neural networks' training process. We thoroughly validate the proposed framework on two computer vision tasks: object detection and object recognition. In these tasks, we reduce the computational complexity up to 20 times with respect to high-latency neural networks. At the same time, we outperform state-of-the-art asynchronous approaches up to 24% in prediction accuracy.
References

Event-based Asynchronous Sparse Convolutional Networks
European Conference on Computer Vision (ECCV), Glasgow, 2020.
Dynamic Obstacle Avoidance for Quadrotors with Event Cameras
Today's autonomous drones have reaction times of tens of milliseconds, which is not enough for navigating fast in complex dynamic environments. To safely avoid fast moving objects, drones need low-latency sensors and algorithms. We departed from state-of-the-art approaches by using event cameras, which are bioinspired sensors with reaction times of microseconds. Our approach exploits the temporal information contained in the event stream to distinguish between static and dynamic objects and leverages a fast strategy to generate the motor commands necessary to avoid the approaching obstacles. Standard vision algorithms cannot be applied to event cameras because the output of these sensors is not images but a stream of asynchronous events that encode per-pixel intensity changes. Our resulting algorithm has an overall latency of only 3.5 milliseconds, which is sufficient for reliable detection and avoidance of fast-moving obstacles. We demonstrate the effectiveness of our approach on an autonomous quadrotor using only onboard sensing and computation. Our drone was capable of avoiding multiple obstacles of different sizes and shapes, at relative speeds up to 10 meters/second, both indoors and outdoors.
References

Dynamic Obstacle Avoidance for Quadrotors with Event Cameras
Science Robotics, March 18, 2020.
Event-Based Angular Velocity Regression with Spiking Networks
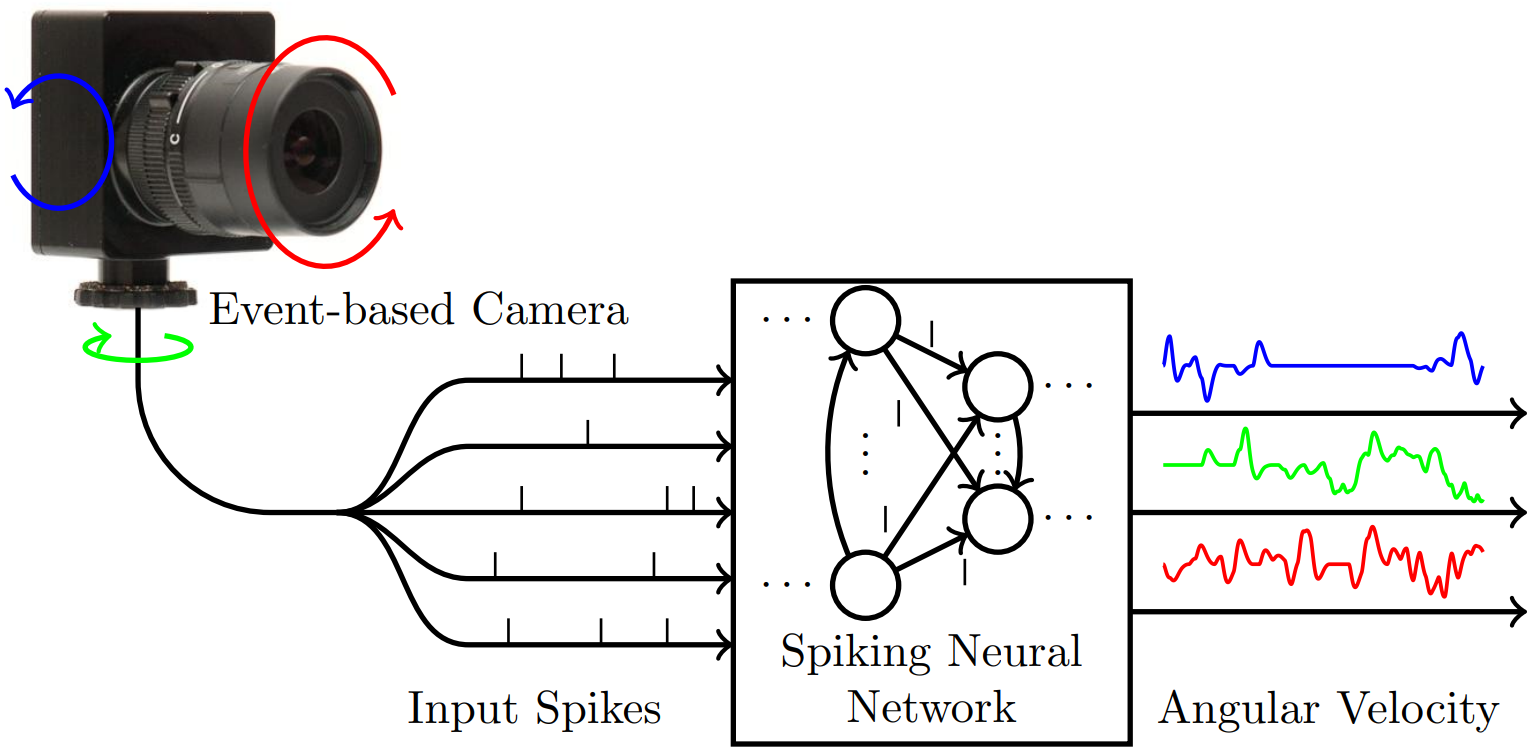
Spiking Neural Networks (SNNs) are bio-inspired networks that process information conveyed as temporal spikes rather than numeric values. An example of a sensor providing such data is the event camera. It only produces an event when a pixel reports a significant brightness change. Similarly, the spiking neuron of an SNN only produces a spike whenever a significant number of spikes occur within a short period of time. Due to their spike-based computational model, SNNs can process output from event-based, asynchronous sensors without any pre-processing at extremely lower power unlike standard artificial neural networks. This is possible due to specialized neuromorphic hardware that implements the highly-parallelizable concept of SNNs in silicon. Yet, SNNs have not enjoyed the same rise of popularity as artificial neural networks. This not only stems from the fact that their input format is rather unconventional but also due to the challenges in training spiking networks. Despite their temporal nature and recent algorithmic advances, they have been mostly evaluated on classification problems. We propose, for the first time, a temporal regression problem of numerical values given events from an event camera.
We specifically investigate the prediction of the 3-DOF angular velocity of a rotating event camera with an SNN. The difficulty of this problem arises from the prediction of angular velocities continuously in time directly from irregular, asynchronous event-based input. Directly utilising the output of event cameras without any pre-processing ensures that we inherit all the benefits that they provide over conventional cameras. That is high-temporal resolution, high-dynamic range and no motion blur. To assess the performance of SNNs on this task, we introduce a synthetic event camera dataset generated from real-world panoramic images and show that we can successfully train an SNN to perform angular velocity regression.
References
Video to Events: Recycling Video Dataset for Event Cameras
Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. They offer significant advantages with respect to conventional cameras: high dynamic range (HDR), high temporal resolution, and no motion blur. Recently, novel learning approaches operating on event data have achieved impressive results. Yet, these methods require a large amount of event data for training, which is hardly available due the novelty of event sensors in computer vision research. In this paper, we present a method that addresses these needs by converting any existing video dataset recorded with conventional cameras to \emph{synthetic} event data. This unlocks the use of a virtually unlimited number of existing video datasets for training networks designed for real event data. We evaluate our method on two relevant vision tasks, i.e., object recognition and semantic segmentation, and show that models trained on synthetic events have several benefits: (i) they generalize well to real event data, even in scenarios where standard-camera images are blurry or overexposed, by inheriting the outstanding properties of event cameras; (ii) they can be used for fine-tuning on real data to improve over state-of-the-art for both classification and semantic segmentation.
References

Video to Events: Recycling Video Dataset for Event Cameras
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2020.
Towards Low-Latency High-Bandwidth Control of Quadrotors using Event Cameras
Event cameras are a promising candidate to enable high speed vision-based control due to their low sensor latency and high temporal resolution. However, purely event-based feedback has yet to be used in the control of drones. In this work, a first step towards implementing low-latency high-bandwidth control of quadrotors using event cameras is taken. In particular, this paper addresses the problem of one-dimensional attitude tracking using a dualcopter platform equipped with an event camera. The event-based state estimation consists of a modified Hough transform algorithm combined with a Kalman filter that outputs the roll angle and angular velocity of the dualcopter relative to a horizon marked by a black-and-white disk. The estimated state is processed by a proportional-derivative attitude control law that computes the rotor thrusts required to track the desired attitude. The proposed attitude tracking scheme shows promising results of event-camera-driven closed loop control: the state estimator performs with an update rate of 1 kHz and a latency determined to be 12 ms, enabling attitude tracking at speeds of over 1600 degrees per second.
References

Towards Low-Latency High-Bandwidth Control of Quadrotors using Event Cameras
IEEE International Conference on Robotics and Automation (ICRA), 2020
Event-Based Motion Segmentation by Motion Compensation
In contrast to traditional cameras, whose pixels have a common exposure time, event-based cameras are novel bio-inspired sensors whose pixels work independently and asynchronously output intensity changes (called "events"), with microsecond resolution. Since events are caused by the apparent motion of objects, event-based cameras sample visual information based on the scene dynamics and are, therefore, a more natural fit than traditional cameras to acquire motion, especially at high speeds, where traditional cameras suffer from motion blur. However, distinguishing between events caused by different moving objects and by the camera's ego-motion is a challenging task. We present the first per-event segmentation method for splitting a scene into independently moving objects. Our method jointly estimates the event-object associations (i.e., segmentation) and the motion parameters of the objects (or the background) by maximization of an objective function, which builds upon recent results on event-based motion-compensation. We provide a thorough evaluation of our method on a public dataset, outperforming the state-of-the-art by as much as 10%. We also show the first quantitative evaluation of a segmentation algorithm for event cameras, yielding around 90% accuracy at 4 pixels relative displacement.
References

Event-Based Motion Segmentation by Motion Compensation
IEEE International Conference on Computer Vision (ICCV), 2019.
End-to-End Learning of Representations for Asynchronous Event-Based Data
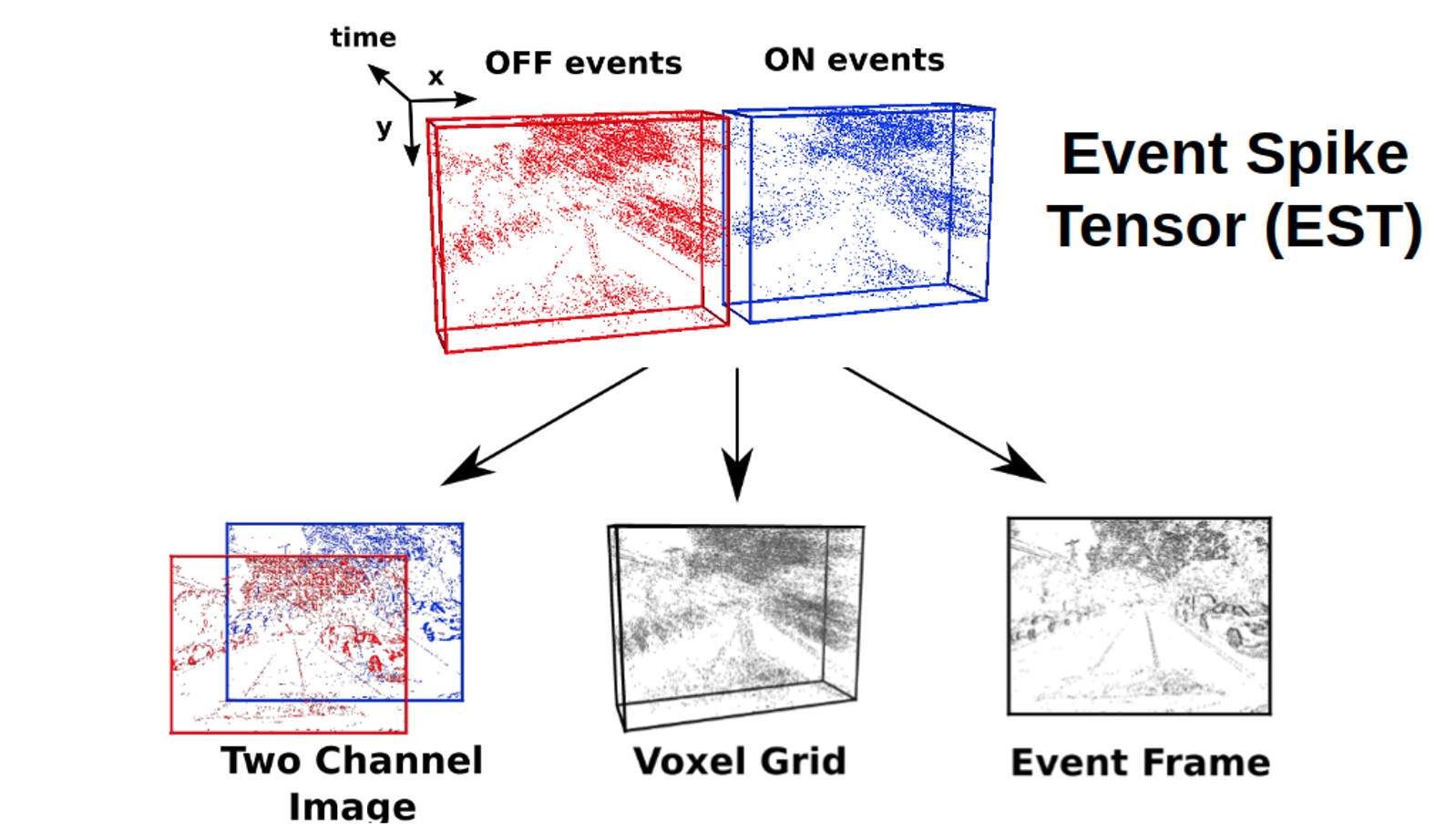
Event cameras are vision sensors that record asynchronous streams of per-pixel brightness changes, referred to as "events". They have appealing advantages over frame-based cameras for computer vision, including high temporal resolution, high dynamic range, and no motion blur. Due to the sparse, non-uniform spatiotemporal layout of the event signal, pattern recognition algorithms typically aggregate events into a grid-based representation and subsequently process it by a standard vision pipeline, e.g., Convolutional Neural Network (CNN). In this work, we introduce a general framework to convert event streams into grid-based representations through a sequence of differentiable operations. Our framework comes with two main advantages: (i) allows learning the input event representation together with the task dedicated network in an end to end manner, and (ii) lays out a taxonomy that unifies the majority of extant event representations in the literature and identifies novel ones. Empirically, we show that our approach to learning the event representation end-to-end yields an improvement of approximately 12% on optical flow estimation and object recognition over state-of-the-art methods.
References
High Speed and High Dynamic Range Video with an Event Camera
Event cameras are novel sensors that report brightness changes in the form of a stream of asynchronous events instead of intensity frames. They offer significant advantages with respect to conventional cameras: high temporal resolution, high dynamic range, and no motion blur. While the stream of events encodes in principle the complete visual signal, the reconstruction of an intensity image from a stream of events is an ill-posed problem in practice. Existing reconstruction approaches are based on hand-crafted priors and strong assumptions about the imaging process as well as the statistics of natural images.
In this work we propose to learn to reconstruct intensity images from event streams directly from data instead of relying on any hand-crafted priors. We propose a novel recurrent network to reconstruct videos from a stream of events, and train it on a large amount of simulated event data. During training we propose to use a perceptual loss to encourage reconstructions to follow natural image statistics. We further extend our approach to synthesize color images from color event streams.
Our quantitative experiments show that our network surpasses state-of-the-art reconstruction methods by a large margin in terms of image quality (> 20%), while comfortably running in real-time. We show that the network is able to synthesize high framerate videos (> 5,000 frames per second) of high-speed phenomena (e.g. a bullet hitting an object) and is able to provide high dynamic range reconstructions in challenging lighting conditions. As an additional contribution, we demonstrate the effectiveness of our reconstructions as an intermediate representation for event data. We show that off-the-shelf computer vision algorithms can be applied to our reconstructions for tasks such as object classification and visual-inertial odometry and that this strategy consistently outperforms algorithms that were specifically designed for event data. We release the reconstruction code and a pre-trained model to enable further research.
We presented our approach in two different papers (references below). Our first paper (CVPR19) introduced the network architecture (a simple recurrent neural network), the training data, and our first video reconstruction results. In our follow-up paper (T-PAMI), we improved the network architecture by using convolutional LSTM blocks and a temporal consistency loss, leading to improved stability and temporal consistency. Furthermore, the improved network now works well with windows containing variable number of events, which allows to synthesize videos at a very high framerate (> 5,000 frames per second), which we additionally demonstrated in a series of new experiments featuring extremely fast motions.
References

High Speed and High Dynamic Range Video with an Event Camera
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 2020.

Fast Image Reconstruction with an Event Camera
IEEE Winter Conference on Applications of Computer Vision (WACV), 2020.
Event-based Vision: A Survey
Event cameras are bio-inspired sensors that work radically different from traditional cameras. Instead of capturing images at a fixed rate, they measure per-pixel brightness changes asynchronously. This results in a stream of events, which encode the time, location and sign of the brightness changes. Event cameras posses outstanding properties compared to traditional cameras: very high dynamic range (140 dB vs. 60 dB), high temporal resolution (in the order of microseconds), low power consumption, and do not suffer from motion blur. Hence, event cameras have a large potential for robotics and computer vision in challenging scenarios for traditional cameras, such as high speed and high dynamic range. However, novel methods are required to process the unconventional output of these sensors in order to unlock their potential. This paper provides a comprehensive overview of the emerging field of event-based vision, with a focus on the applications and the algorithms developed to unlock the outstanding properties of event cameras. We present event cameras from their working principle, the actual sensors that are available and the tasks that they have been used for, from low-level vision (feature detection and tracking, optic flow, etc.) to high-level vision (reconstruction, segmentation, recognition). We also discuss the techniques developed to process events, including learning-based techniques, as well as specialized processors for these novel sensors, such as spiking neural networks. Additionally, we highlight the challenges that remain to be tackled and the opportunities that lie ahead in the search for a more efficient, bio-inspired way for machines to perceive and interact with the world.
References
Event-based Vision: A Survey
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
How Fast is Too Fast? The Role of Perception Latency in High-Speed Sense and Avoid
In this work, we study the effects that perception latency has on the maximum speed a robot can reach to safely navigate through an unknown cluttered environment. We provide a general analysis that can serve as a baseline for future quantitative reasoning for design trade-offs in autonomous robot navigation. We consider the case where the robot is modeled as a linear second-order system with bounded input and navigates through static obstacles. Also, we focus on a scenario where the robot wants to reach a target destination in as little time as possible, and therefore cannot change its longitudinal velocity to avoid obstacles. We show how the maximum latency that the robot can tolerate to guarantee safety is related to the desired speed, the range of its sensing pipeline, and the actuation limitations of the platform (i.e., the maximum acceleration it can produce). As a particular case study, we compare monocular and stereo frame-based cameras against novel, low-latency sensors, such as event cameras, in the case of quadrotor flight. To validate our analysis, we conduct experiments on a quadrotor platform equipped with an event camera to detect and avoid obstacles thrown towards the robot. To the best of our knowledge, this is the first theoretical work in which perception and actuation limitations are jointly considered to study the performance of a robotic platform in high-speed navigation.
References

CED: Color Event Camera Dataset

Event cameras are novel, bio-inspired visual sensors, whose pixels output asynchronous and independent timestamped spikes at local intensity changes, called "events". Event cameras offer advantages over conventional frame-based cameras in terms of latency, high dynamic range (HDR) and temporal resolution. Until recently, event cameras have been limited to outputting events in the intensity channel, however, recent advances have resulted in the development of color event cameras, such as the Color DAVIS346. In this work, we present and release the first Color Event Camera Dataset (CED), containing 50 minutes of footage with both color frames and events. CED features a wide variety of indoor and outdoor scenes, which we hope will help drive forward event-based vision research. We also present an extension of the event camera simulator ESIM that enables simulation of color events. Finally, we present an evaluation of three state-of-the-art image reconstruction methods that can be used to convert the Color DAVIS346 into a continuous-time, HDR, color video camera to visualise the event stream, and for use in downstream vision applications.
References
Focus Is All You Need: Loss Functions for Event-based Vision
Event cameras are novel vision sensors that output pixel-level brightness changes ("events") instead of traditional video frames. These asynchronous sensors offer several advantages over traditional cameras, such as, high temporal resolution, very high dynamic range, and no motion blur. To unlock the potential of such sensors, motion compensation methods have been recently proposed. We present a collection and taxonomy of twenty two objective functions to analyze event alignment in motion compensation approaches. We call them focus loss functions since they have strong connections with functions used in traditional shape-from-focus applications. The proposed loss functions allow bringing mature computer vision tools to the realm of event cameras. We compare the accuracy and runtime performance of all loss functions on a publicly available dataset, and conclude that the variance, the gradient and the Laplacian magnitudes are among the best loss functions. The applicability of the loss functions is shown on multiple tasks: rotational motion, depth and optical flow estimation. The proposed focus loss functions allow to unlock the outstanding properties of event cameras.
References
The UZH-FPV Drone Racing Dataset
Despite impressive results in visual-inertial state estimation in recent years, high speed trajectories with six degree of freedom motion remain challenging for existing estimation algorithms. Aggressive trajectories feature large accelerations and rapid rotational motions, and when they pass close to objects in the environment, this induces large apparent motions in the vision sensors, all of which increase the difficulty in estimation.
We introduce the UZH-FPV Drone Racing dataset, consisting of over 27 sequences, with more than 10 km of flight distance, captured on a first-person-view (FPV) racing quadrotor flown by an expert pilot. The dataset features event camera data, camera images, and inertial measurements, together with precise ground truth poses. These sequences are faster and more challenging, in terms of apparent scene motion, than any existing dataset.
References

Are We Ready for Autonomous Drone Racing? The UZH-FPV Drone Racing Dataset
IEEE International Conference on Robotics and Automation (ICRA), 2019.
Event-based, Direct Camera Tracking from a Photometric 3D Map using Nonlinear Optimization
Event cameras are novel bio-inspired vision sensors that output pixel-level intensity changes, called "events", instead of traditional video images. These asynchronous sensors naturally respond to motion in the scene with very low latency (in the order of microseconds) and have a very high dynamic range. These features, along with a very low power consumption, make event cameras an ideal sensor for fast robot localization and wearable applications, such as AR/VR and gaming. Considering these applications, we present a method to track the 6-DOF pose of an event camera in a known environment, which we contemplate to be described by a photometric 3D map (i.e., intensity plus depth information) built via classic dense 3D reconstruction algorithms. Our approach uses the raw events, directly, without intermediate features, within a maximum-likelihood framework to estimate the camera motion that best explains the events via a generative model. We successfully evaluate the method using both simulated and real data, and show improved results over the state of the art. We release the datasets and code to the public to foster reproducibility and research in this topic.
References

Event-based, Direct Camera Tracking from a Photometric 3D Map using Nonlinear Optimization
IEEE International Conference on Robotics and Automation (ICRA), 2019.
ESIM: an Open Event Camera Simulator
Event cameras measure changes of intensity asynchronously, in the form of a stream of events, which encode per-pixel brightness changes. In the last few years, their outstanding properties (asynchronous sensing, no motion blur, high dynamic range) have led to exciting vision applications, with very low-latency and high robustness. However, these sensors are still scarce and expensive to get, slowing down progress of the research community. To address these issues, there is a huge demand for cheap, high-quality synthetic, labeled event for algorithm prototyping, deep learning and algorithm benchmarking. The development of such a simulator, however, is not trivial since event cameras work fundamentally differently from frame-based cameras. We present the first event camera simulator that can generate a large amount of reliable event data. The key component of our simulator is a theoretically sound, adaptive rendering scheme that only samples frames when necessary, through a tight coupling between the rendering engine and the event simulator. We release ESIM as open source.
References

ESIM: an Open Event Camera Simulator
Conference on Robot Learning (CoRL), Zurich, 2018.
EKLT: Asynchronous, Photometric Feature Tracking using Events and Frames
We present EKLT, a feature tracking method that leverages the complementarity of event cameras and standard cameras to track visual features with low latency. Event cameras are novel sensors that output pixel-level brightness changes, called "events". They offer significant advantages over standard cameras, namely a very high dynamic range, no motion blur, and a latency in the order of microseconds. However, because the same scene pattern can produce different events depending on the motion direction, establishing event correspondences across time is challenging. By contrast, standard cameras provide intensity measurements (frames) that do not depend on motion direction. Our method extracts features on frames and subsequently tracks them asynchronously using events, thereby exploiting the best of both types of data: the frames provide a photometric representation that does not depend on motion direction and the events provide low latency updates. In contrast to previous works, which are based on heuristics, this is the first principled method that uses raw intensity measurements directly, based on a generative event model within a maximum-likelihood framework. As a result, our method produces feature tracks that are both more accurate (subpixel accuracy) and longer than the state of the art, across a wide variety of scenes.
References
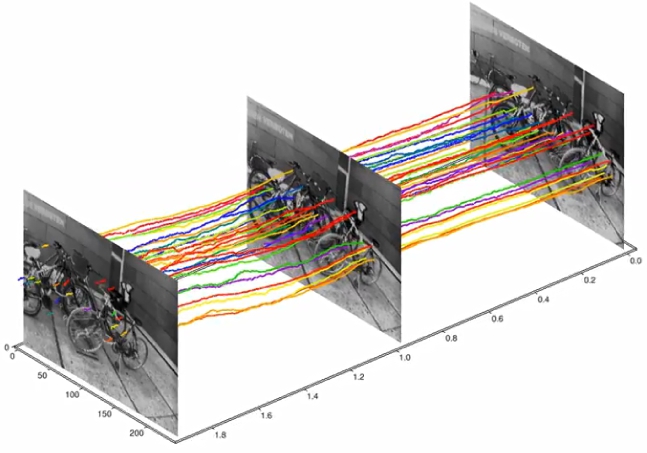
EKLT: Asynchronous, Photometric Feature Tracking using Events and Frames
International Journal of Computer Vision (IJCV), 2019.
Asynchronous, Photometric Feature Tracking using Events and Frames
European Conference on Computer Vision (ECCV), Munich, 2018.
Oral Presentation.
PDF Poster YouTube Oral presentation Evaluation Code Tracking Code
Semi-Dense 3D Reconstruction with a Stereo Event Camera
Event cameras are bio-inspired sensors that offer several advantages, such as low latency, high-speed and high dynamic range, to tackle challenging scenarios in computer vision. This paper presents a solution to the problem of 3D reconstruction from data captured by a stereo event-camera rig moving in a static scene, such as in the context of stereo Simultaneous Localization and Mapping. The proposed method consists of the optimization of an energy function designed to exploit small-baseline spatio-temporal consistency of events triggered across both stereo image planes. To improve the density of the reconstruction and to reduce the uncertainty of the estimation, a probabilistic depth-fusion strategy is also developed. The resulting method has no special requirements on either the motion of the stereo event-camera rig or on prior knowledge about the scene. Experiments demonstrate our method can deal with both texture-rich scenes as well as sparse scenes, outperforming state-of-the-art stereo methods based on event data image representations.
References

Semi-Dense 3D Reconstruction with a Stereo Event Camera
European Conference on Computer Vision (ECCV), Munich, 2018.
Continuous-Time Visual-Inertial Odometry for Event Cameras
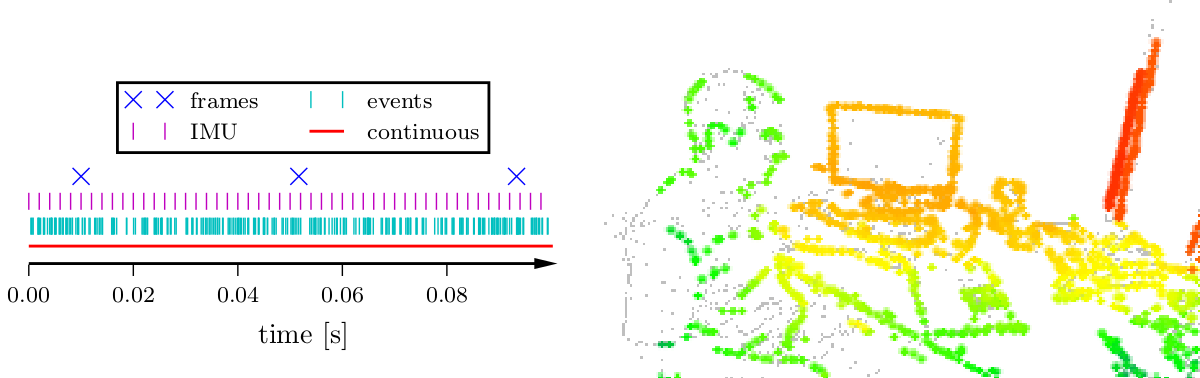
References
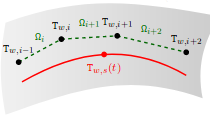
A Unifying Contrast Maximization Framework for Event Cameras, with Applications to Motion, Depth and Optical Flow Estimation
We present a unifying framework to solve several computer vision problems with event cameras: motion, depth and optical flow estimation. The main idea of our framework is to find the point trajectories on the image plane that are best aligned with the event data by maximizing an objective function: the contrast of an image of warped events. Our method implicitly handles data association between the events, and therefore, does not rely on additional appearance information about the scene. In addition to accurately recovering the motion parameters of the problem, our framework produces motion-corrected edge-like images with high dynamic range that can be used for further scene analysis. The proposed method is not only simple, but more importantly, it is, to the best of our knowledge, the first method that can be successfully applied to such a diverse set of important vision tasks with event cameras.
References

A Unifying Contrast Maximization Framework for Event Cameras, with Applications to Motion, Depth and Optical Flow Estimation
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, 2018.
Spotlight Presentation.
Ultimate SLAM? Combining Events, Images, and IMU for Robust Visual SLAM in HDR and High Speed Scenarios
In this paper, we present the first state estimation pipeline that leverages the complementary advantages of a standard camera with an event camera by fusing in a tightly-coupled manner events, standard frames, and inertial measurements. We show on the Event Camera Dataset that our hybrid pipeline leads to an accuracy improvement of 130% over event-only pipelines, and 85% over standard-frames only visual-inertial systems, while still being computationally tractable.
Furthermore, we use our pipeline to demonstrate - to the best of our knowledge - the first autonomous quadrotor flight using an event camera for state estimation, unlocking flight scenarios that were not reachable with traditional visual inertial odometry, such as low-light environments and high dynamic range scenes.
References

Ultimate SLAM? Combining Events, Images, and IMU for Robust Visual SLAM in HDR and High Speed Scenarios
IEEE Robotics and Automation Letters (RA-L), 2018.
PDF YouTube ICRA18 Video Pitch Poster Results (raw trajectories) Project Webpage Source Code
EMVS: Event-Based Multi-View Stereo - 3D Reconstruction with an Event Camera in Real-Time
|
IJCV video |
BMVC video |
|---|
References
EMVS: Event-Based Multi-View Stereo - 3D Reconstruction with an Event Camera in Real-Time
International Journal of Computer Vision, 2017.
EMVS: Event-based Multi-View Stereo
British Machine Vision Conference (BMVC), York, 2016.
Best Industry Related Paper (sponsored by nvidia and BMVA)
Event-based, 6-DOF Camera Tracking from Photometric Depth Maps
References
Real-time Visual-Inertial Odometry for Event Cameras using Keyframe-based Nonlinear Optimization
We propose a novel, accurate tightly-coupled visual-inertial odometry pipeline for event cameras that leverages their outstanding properties to estimate the camera ego-motion in challenging conditions, such as high-speed motion or high dynamic range scenes. Our pipeline can output poses at a rate proportional to the camera velocity and runs in real-time on a CPU.
The method tracks a set of features (extracted on the image plane) through time. To achieve that, we consider events in overlapping spatio-temporal windows and align them using the current camera motion and scene structure, yielding motion-compensated event frames. We then combine these feature tracks in a keyframe-based, visual-inertial odometry algorithm based on nonlinear optimization to estimate the camera's 6-DOF pose, velocity, and IMU biases.
We evaluated the proposed method quantitatively on the public Event Camera Dataset and it significantly outperforms the state-of-the-art, while being computationally much more efficient: our pipeline can run much faster than real-time on a laptop and even on a smartphone processor. Furthermore, we demonstrate qualitatively the accuracy and robustness of our pipeline on a large-scale dataset, and an extremely high-speed dataset recorded by spinning an event camera on a leash at 850 deg/s.
References
Real-time Visual-Inertial Odometry for Event Cameras using Keyframe-based Nonlinear Optimization
British Machine Vision Conference (BMVC), London, 2017.
Oral Presentation. Acceptance Rate: 5.6%
PDF PPT YouTube Oral Presentation Results (raw trajectories)
Fast Event-based Corner Detection
References

Fast Event-based Corner Detection
British Machine Vision Conference (BMVC), London, 2017.
EVO: Event-based, 6-DOF Parallel Tracking and Mapping in Real-Time
References
Accurate Angular Velocity Estimation with an Event Camera
References
The Event Camera Dataset and Simulator: Event-based Data for Pose Estimation, Visual Odometry, and SLAM
References
The Event-Camera Dataset and Simulator: Event-based Data for Pose Estimation, Visual Odometry, and SLAM
International Journal of Robotics Research, Vol. 36, Issue 2, pages 142-149, Feb. 2017.
Low-Latency Visual Odometry using Event-based Feature Tracks
|
IROS'16 video |
EBCCSP'16 video |
|---|
References

Low-Latency Visual Odometry using Event-based Feature Tracks
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, 2016.
Best Application Paper Award Finalist! Highlight Talk: Acceptance Rate 2.5%
Feature Detection and Tracking with the Dynamic and Active-pixel Vision Sensor (DAVIS)
International Conference on Event-Based Control, Communication and Signal Processing (EBCCSP), Krakow, 2016.

ELiSeD - An Event-Based Line Segment Detector
International Conference on Event-Based Control, Communication and Signal Processing (EBCCSP), Krakow, 2016.
Continuous-Time Trajectory Estimation for Event-based Vision Sensors
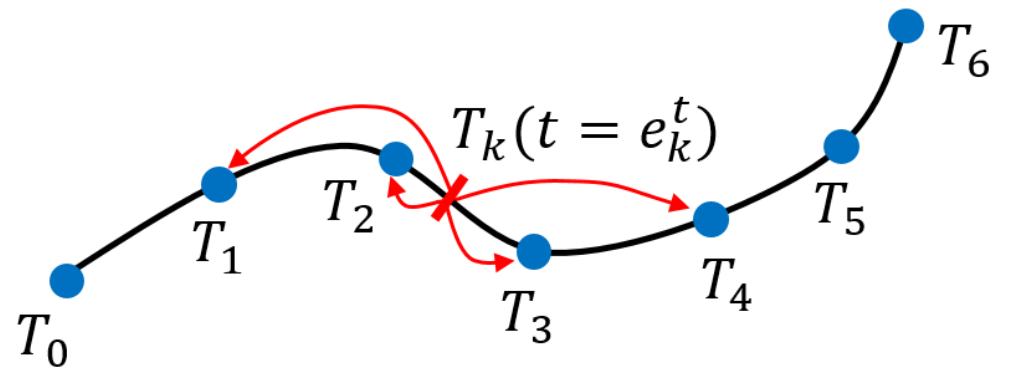
References
Event-based Camera Pose Tracking using a Generative Event Model

References

Lifetime Estimation of Events from Dynamic Vision Sensors

References
Event-based, 6-DOF Pose Tracking for High-Speed Maneuvers
References

Low-Latency Event-Based Visual Odometry

References
Low-Latency Event-Based Visual Odometry
IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, 2014.
Low-latency localization by Active LED Markers tracking using a DVS