



Deep Learning
Deep learning is a branch of machine learning based on a set of algorithms that attempt to model high level abstractions in data. In our research, we apply deep learning to solve different mobile robot navigation problems, such as depth estimation, end-to-end navigation, and classification.
Regularity and Stability Properties of Selective SSMs with Discontinuous Gating
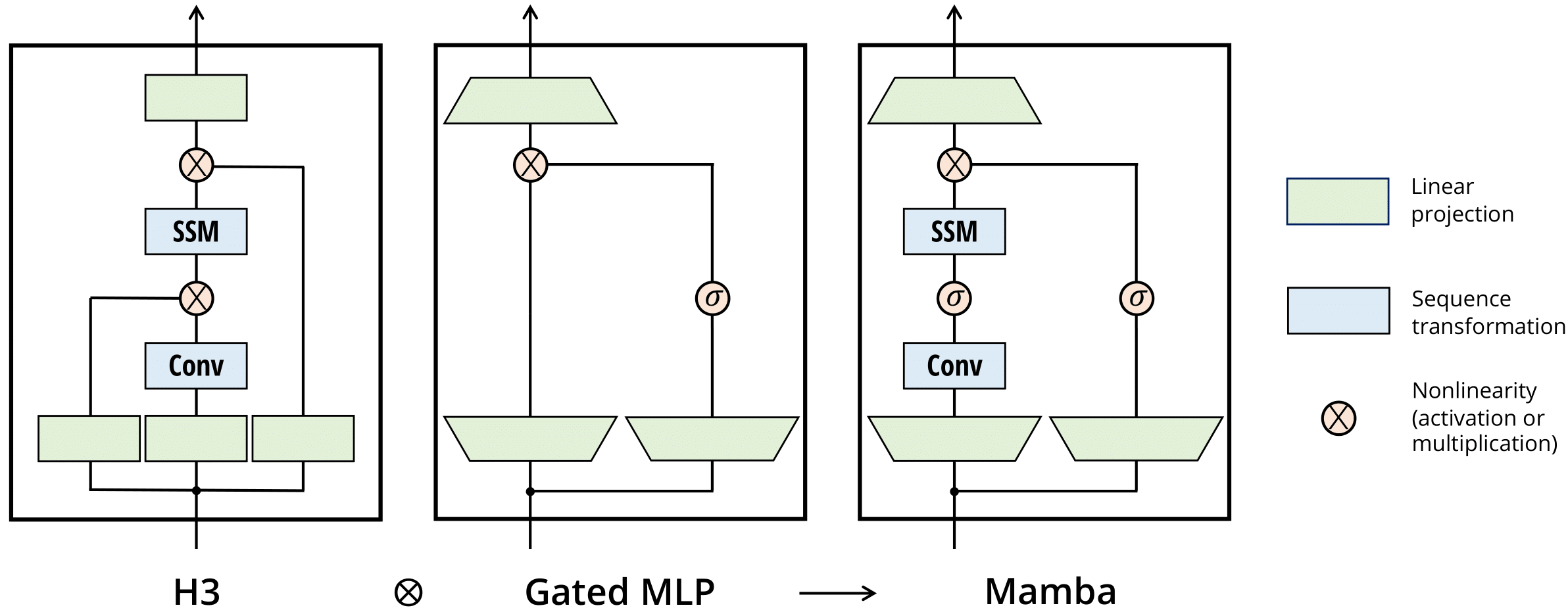
Deep Selective State-Space Models (SSMs), characterized by input-dependent, time-varying parameters, offer significant expressive power but pose challenges for stability analysis, especially with discontinuous gating signals. In this paper, we investigate the stability and regularity properties of continuous-time selective SSMs through the lens of passivity and Input-to-State Stability (ISS). We establish that intrinsic energy dissipation guarantees exponential forgetting of past states. Crucially, we prove that the unforced system dynamics possess an underlying minimal quadratic energy function whose defining matrix exhibits robust AUCloc regularity, accommodating discontinuous gating. Furthermore, assuming a universal quadratic storage function ensures passivity across all inputs, we derive parametric LMI conditions and kernel constraints that limit gating mechanisms, formalizing "irreversible forgetting" of recurrent models. Finally, we provide sufficient conditions for global ISS, linking uniform local dissipativity to overall system robustness. Our findings offer a rigorous framework for understanding and designing stable and reliable deep selective SSMs.
References
Maximizing Asynchronicity in Event-based Neural Networks
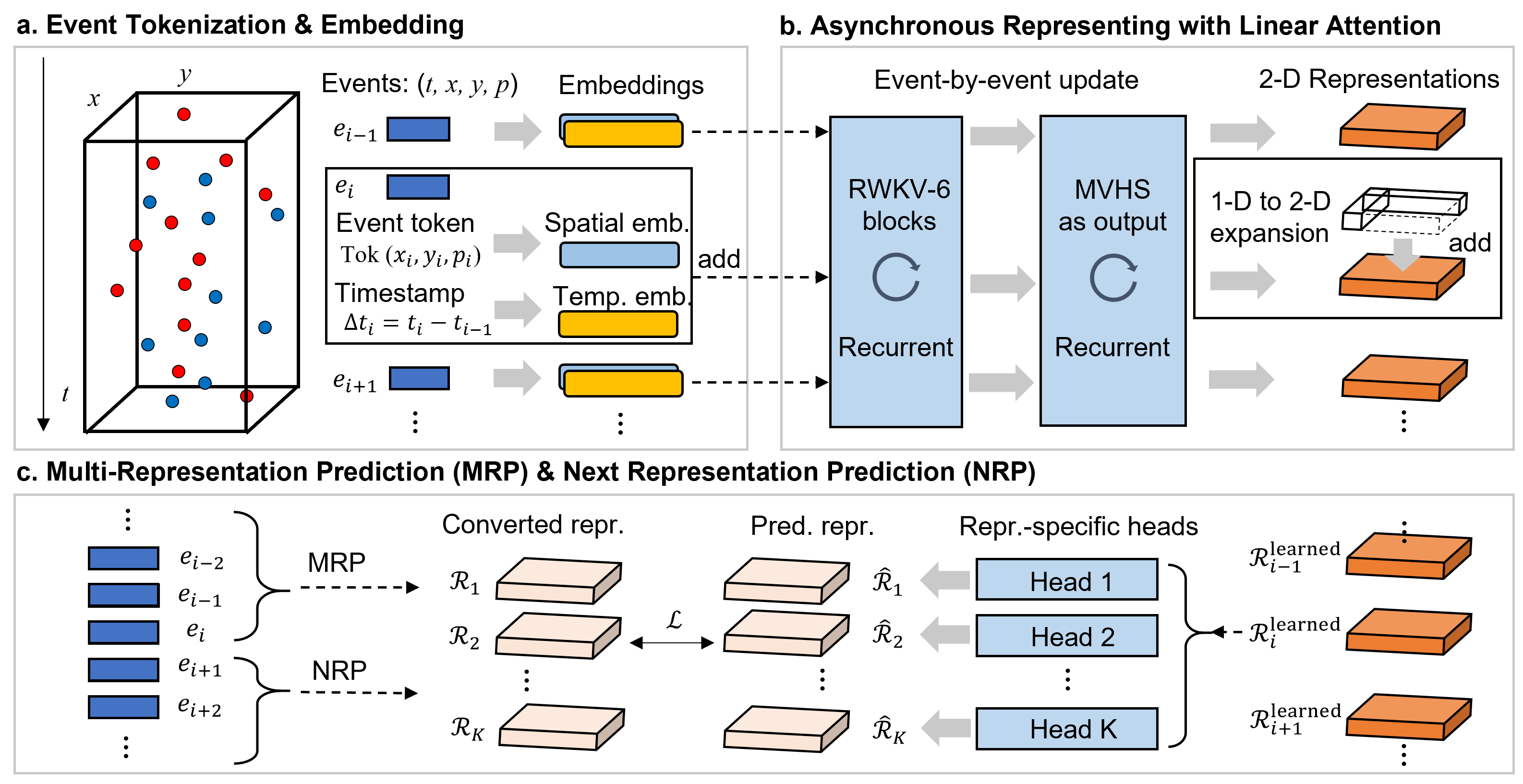
Event cameras deliver visual data with high temporal resolution, low latency, and minimal redundancy, yet their asynchronous, sparse sequential nature challenges standard tensor-based machine learning (ML). While the recent asynchronous-to-synchronous (A2S) paradigm aims to bridge this gap by asynchronously encoding events into learned representations for ML pipelines, existing A2S approaches often sacrifice representation expressivity and generalizability compared to dense, synchronous methods. This paper introduces EVA (EVent Asynchronous representation learning), a novel A2S framework to generate highly expressive and generalizable event-by-event representations. Inspired by the analogy between events and language, EVA uniquely adapts advances from language modeling in linear attention and self-supervised learning for its construction. In demonstration, EVA outperforms prior A2S methods on recognition tasks (DVS128-Gesture and N-Cars), and represents the first A2S framework to successfully master demanding detection tasks, achieving a remarkable 47.7 mAP on the Gen1 dataset. These results underscore EVA's transformative potential for advancing real-time event-based vision applications.
References
GG-SSMs: Graph-Generating State Space Models

State Space Models (SSMs) are powerful tools for modeling sequential data in computer vision and time series analysis domains. However, traditional SSMs are limited by fixed, one-dimensional sequential processing, which restricts their ability to model non-local interactions in high-dimensional data. While methods like Mamba and VMamba introduce selective and flexible scanning strategies, they rely on predetermined paths, which fails to efficiently capture complex dependencies. We introduce Graph-Generating State Space Models (GG-SSMs), a novel framework that overcomes these limitations by dynamically constructing graphs based on feature relationships. Using Chazelle's Minimum Spanning Tree algorithm, GG-SSMs adapt to the inherent data structure, enabling robust feature propagation across dynamically generated graphs and efficiently modeling complex dependencies. We validate GG-SSMs on 11 diverse datasets, including event-based eye-tracking, ImageNet classification, optical flow estimation, and six time series datasets. GG-SSMs achieve state-of-the-art performance across all tasks, surpassing existing methods by significant margins. Specifically, GG-SSM attains a top-1 accuracy of 84.9% on ImageNet, outperforming prior SSMs by 1%, reducing the KITTI-15 error rate to 2.77%, and improving eye-tracking detection rates by up to 0.33% with fewer parameters. These results demonstrate that dynamic scanning based on feature relationships significantly improves SSMs' representational power and efficiency, offering a versatile tool for various applications in computer vision and beyond.
References
ForesightNav: Learning Scene Imagination for Efficient Exploration

Understanding how humans leverage prior knowledge to navigate unseen environments while making exploratory decisions is essential for developing autonomous robots with similar abilities. In this work, we propose ForesightNav, a novel exploration strategy inspired by human imagination and reasoning. Our approach equips robotic agents with the capability to predict contextual information, such as occupancy and semantic details, for unexplored regions. These predictions enable the robot to efficiently select meaningful long-term navigation goals, significantly enhancing exploration in unseen environments.We validate our imagination-based approach using the Structured3D dataset, demonstrating accurate occupancy prediction and superior performance in anticipating unseen scene geometry. Our experiments show that the imagination module improves exploration efficiency in unseen environments, achieving a 100% completion rate for PointNav and an SPL of 67% for ObjectNav on the Structured3D Validation split. These contributions demonstrate the power of imagination-driven reasoning for autonomous systems to enhance generalizable and efficient exploration.
References
Perturbed State Space Feature Encoders for Optical Flow with Event Cameras
With their motion-responsive nature, event-based cameras offer significant advantages over traditional cameras for optical flow estimation. While deep learning has improved upon traditional methods, current neural networks adopted for event-based optical flow still face temporal and spatial reasoning limitations. We propose Perturbed State Space Feature Encoders (P-SSE) for multi-frame optical flow with event cameras to address these challenges. P-SSE adaptively processes spatiotemporal features with a large receptive field akin to Transformer-based methods, while maintaining the linear computational complexity characteristic of SSMs. However, the key innovation that enables the state-of-the-art performance of our model lies in our perturbation technique applied to the state dynamics matrix governing the SSM system. This approach significantly improves the stability and performance of our model. We integrate P-SSE into a framework that leverages bi-directional flows and recurrent connections, expanding the temporal context of flow prediction. Evaluations on DSEC-Flow and MVSEC datasets showcase P-SSE's superiority, with 8.48% and 11.86% improvements in EPE performance, respectively.
References
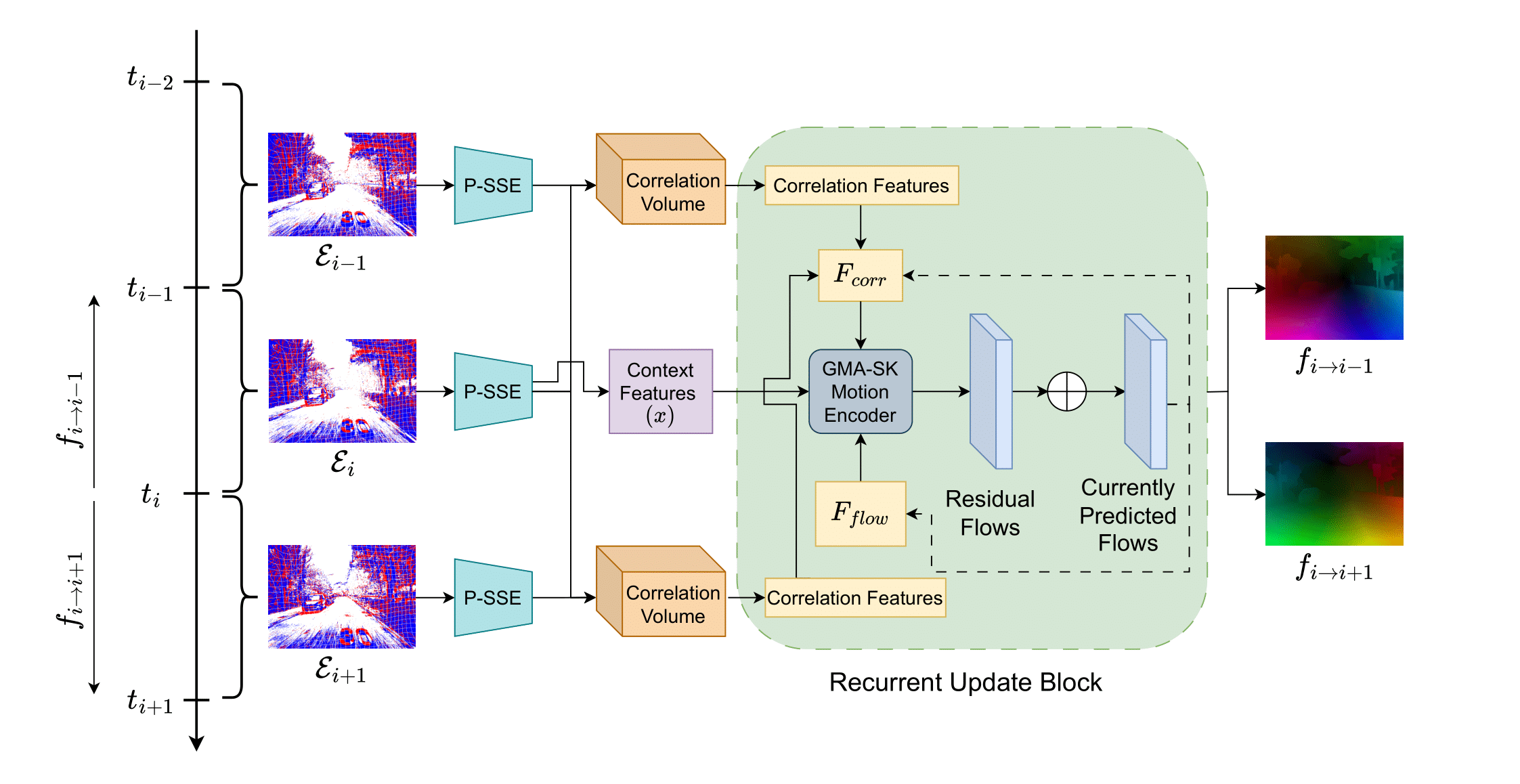
Perturbed State Space Feature Encoders for Optical Flow with Event Cameras
IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, 2025.
Environment as Policy: Learning to Race in Unseen Tracks

Reinforcement learning (RL) has achieved outstanding success in complex robot control tasks, such as drone racing, where the RL agents have outperformed human champions in a known racing track. However, these agents fail in unseen track configurations, always requiring complete retraining when presented with new track layouts. This work aims to develop RL agents that generalize effectively to novel track configurations without retraining. The na¨ıve solution of training directly on a diverse set of track layouts can overburden the agent, resulting in suboptimal policy learning as the increased complexity of the environment impairs the agent’s ability to learn to fly. To enhance the generalizability of the RL agent, we propose an adaptive environment-shaping framework that dynamically adjusts the training environment based on the agent’s performance. We achieve this by leveraging a secondary RL policy to design environments that strike a balance between being challenging and achievable, allowing the agent to adapt and improve progressively. Using our adaptive environment shaping, one single racing policy efficiently learns to race in diverse challenging tracks. Experimental results validated in both simulation and the real world show that our method enables drones to successfully fly complex and unseen race tracks, outperforming existing environment-shaping techniques.
References

Environment as Policy: Learning to Race in Unseen Tracks
IEEE International Conference on Robotics and Automation (ICRA), 2025.
Limits of Deep Learning: Sequence Modeling through the Lens of Complexity Theory
Despite their successes, deep learning models struggle with tasks requiring complex reasoning and function composition. We present a theoretical and empirical investigation into the limitations of Structured State Space Models (SSMs) and Transformers in such tasks. We prove that one-layer SSMs cannot efficiently perform function composition over large domains without impractically large state sizes, and even with Chain-of-Thought prompting, they require a number of steps that scale unfavorably with the complexity of the function composition. Also, the language of a finite-precision SSM is within the class of regular languages. Our experiments corroborate these theoretical findings. Evaluating models on tasks including various function composition settings, multi-digit multiplication, dynamic programming, and Einstein's puzzle, we find significant performance degradation even with advanced prompting techniques. Models often resort to shortcuts, leading to compounding errors. These findings highlight fundamental barriers within current deep learning architectures rooted in their computational capacities. We underscore the need for innovative solutions to transcend these constraints and achieve reliable multi-step reasoning and compositional task-solving, which is critical for advancing toward general artificial intelligence.
References

Limits of Deep Learning: Sequence Modeling through the Lens of Complexity Theory
International Conference on Learning Representations (ICLR), 2025.
Student-Informed Teacher Training
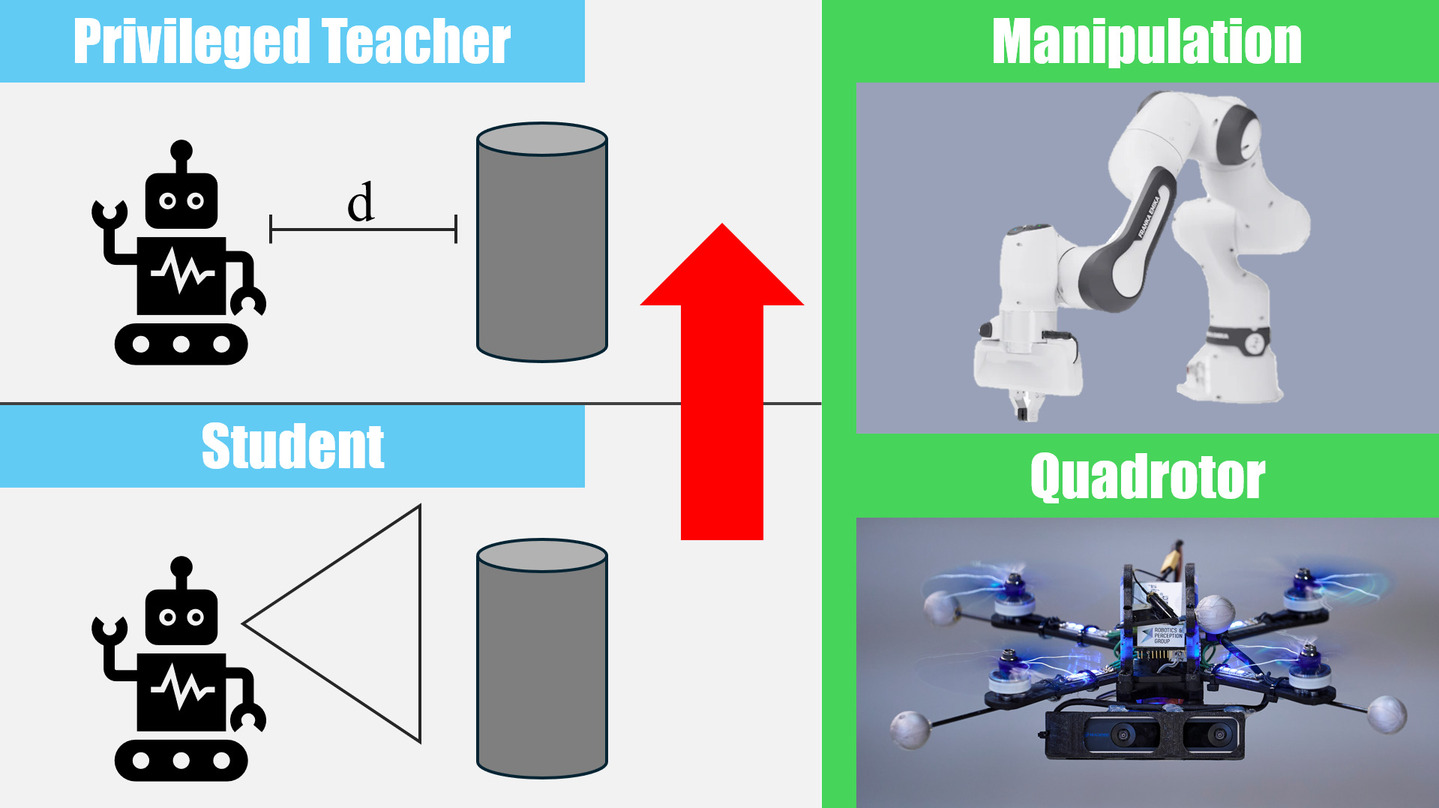
Imitation learning with a privileged teacher has proven effective for learning complex control behaviors from high-dimensional inputs, such as images. In this framework, a teacher is trained with privileged task information, while a student tries to predict the actions of the teacher with more limited observations, e.g., in a robot navigation task, the teacher might have access to distances to nearby obstacles, while the student only receives visual observations of the scene. However, privileged imitation learning faces a key challenge: the student might be unable to imitate the teacher's behavior due to partial observability. This problem arises because the teacher is trained without considering if the student is capable of imitating the learned behavior. To address this teacher-student asymmetry, we propose a framework for joint training of the teacher and student policies, encouraging the teacher to learn behaviors that can be imitated by the student despite the latters' limited access to information and its partial observability. Based on the performance bound in imitation learning, we add (i) the approximated action difference between teacher and student as a penalty term to the reward function of the teacher, and (ii) a supervised teacher-student alignment step. We motivate our method with a maze navigation task and demonstrate its effectiveness on complex vision-based quadrotor flight and manipulation tasks.
References
Student-Informed Teacher Training
International Conference on Learning Representations (ICLR), 2025.
Spotlight Presentation.
Dream to Fly: Model-Based Reinforcement Learning for Vision-Based Drone Flight

Can we use Model-based Reinforcement Learning (MBRL) to fly a drone from pixels to commands? In our new paper, we present an approach for training quadrotor navigation policies from scratch - mapping raw onboard camera pixels directly to control commands, much like a human pilot. While model-free methods such as PPO are sample-inefficient and struggle in this setting, we leverage MBRL to train visuomotor policies capable of agile flight through a racetrack using only raw pixel observations. Moreover, because our policies are trained end-to-end directly from pixels, we no longer require the perception-aware reward term used in previous methods. Instead, we show that this behavior naturally emerges, resulting in policies that guide the camera toward feature-rich areas of the observation space.
References
Data-driven Feature Tracking for Event Cameras with and without Frames

Because of their high temporal resolution, increased resilience to motion blur, and very sparse output, event cameras have been shown to be ideal for low-latency and low-bandwidth feature tracking, even in challenging scenarios. Existing feature tracking methods for event cameras are either handcrafted or derived from first principles but require extensive parameter tuning, are sensitive to noise, and do not generalize to different scenarios due to unmodeled effects. To tackle these deficiencies, we introduce the first data-driven feature tracker for event cameras, which leverages low-latency events to track features detected in an intensity frame. We achieve robust performance via a novel frame attention module, which shares information across feature tracks. Our tracker is designed to operate in two distinct configurations: solely with events or in a hybrid mode incorporating both events and frames. The hybrid model offers two setups: an aligned configuration where the event and frame cameras share the same viewpoint, and a hybrid stereo configuration where the event camera and the standard camera are positioned side by side. This side-by-side arrangement is particularly valuable as it provides depth information for each feature track, enhancing its utility in applications such as visual odometry and simultaneous localization and mapping.
References
FaVoR: Features via Voxel Rendering for Camera Relocalization
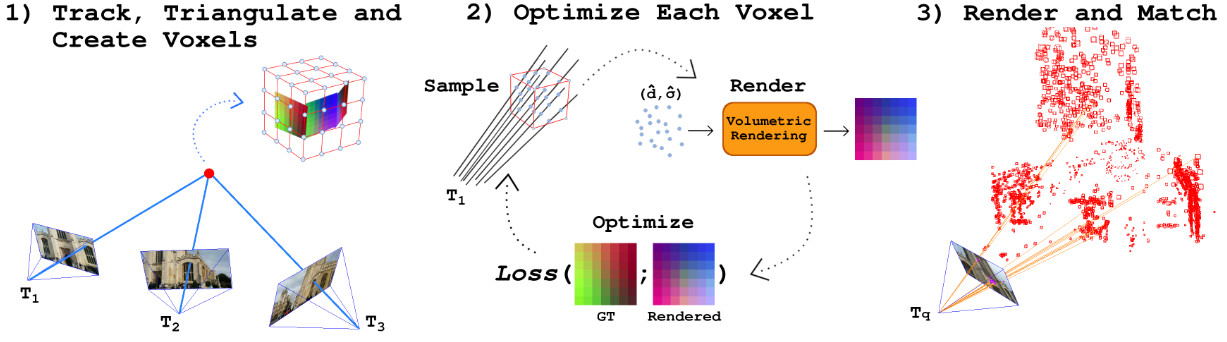
Camera relocalization methods range from dense image alignment to direct camera pose regression from a query image. Among these, sparse feature matching stands out as an efficient, versatile, and generally lightweight approach with numerous applications. However, feature-based methods often struggle with significant viewpoint and appearance changes, leading to matching failures and inaccurate pose estimates. To overcome this limitation, we propose a novel approach that leverages a globally sparse yet locally dense 3D representation of 2D features. By tracking and triangulating landmarks over a sequence of frames, we construct a sparse voxel map optimized to render image patch descriptors observed during tracking. Given an initial pose estimate, we first synthesize descriptors from the voxels using volumetric rendering and then perform feature matching to estimate the camera pose. This methodology enables the generation of descriptors for unseen views, enhancing robustness to view changes. We extensively evaluate our method on the 7-Scenes and Cambridge Landmarks datasets. Our results show that our method significantly outperforms existing state-of-the-art feature representation techniques in indoor environments, achieving up to a 39% improvement in median translation error. Additionally, our approach yields comparable results to other methods for outdoor scenarios while maintaining lower memory and computational costs.
References
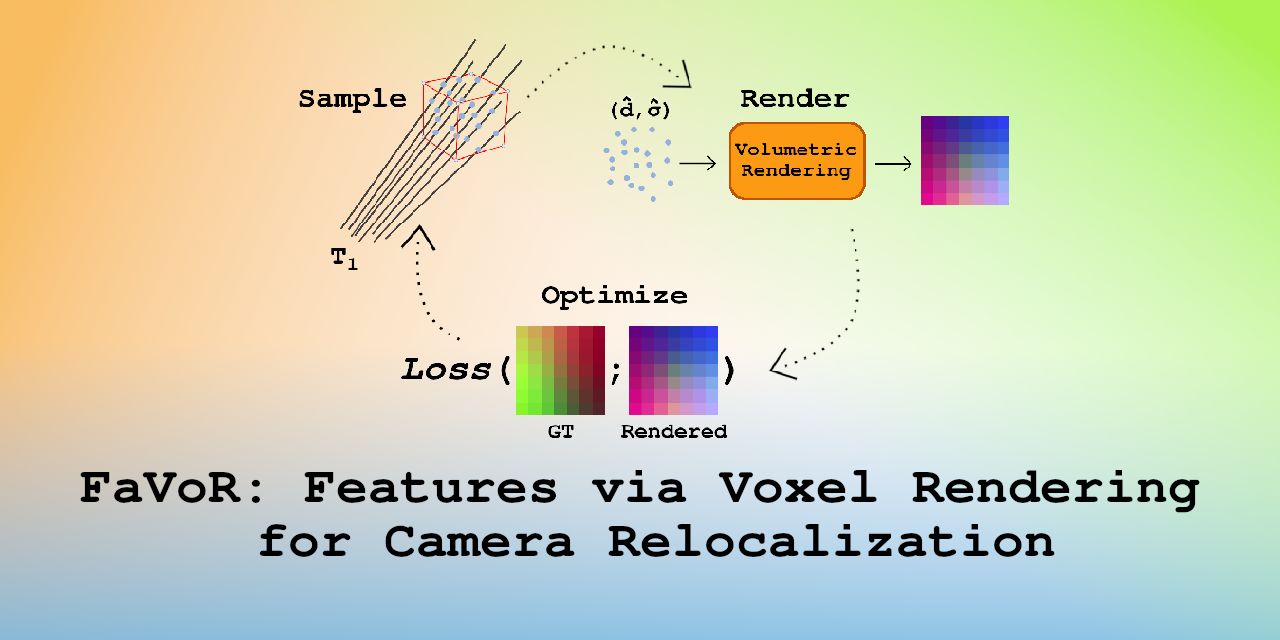
FaVoR: Features via Voxel Rendering for Camera Relocalization
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, Arizona, 2025.
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control

We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego- trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, egotrajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations.
References
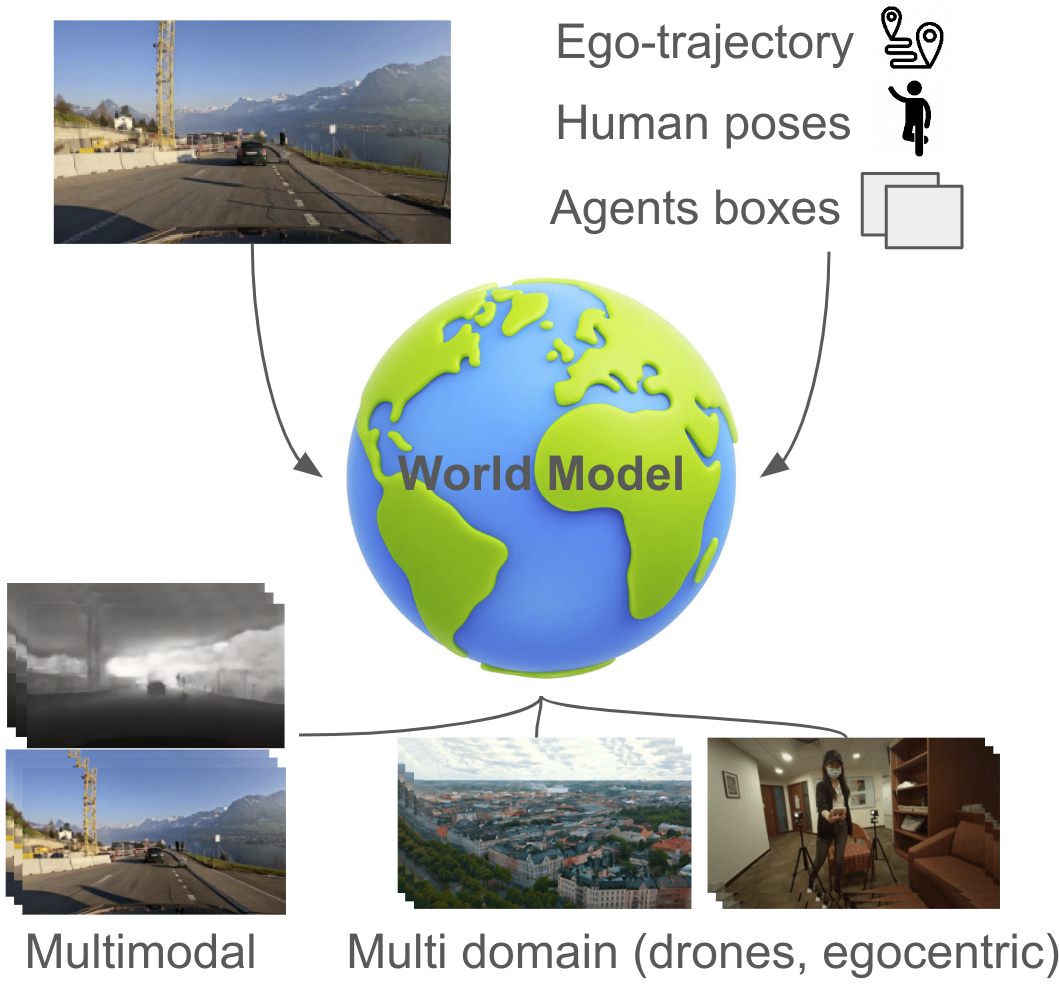
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
ArXiv, 2024.
Multi-task Reinforcement Learning for Quadrotors
Reinforcement learning (RL) has shown great effectiveness in quadrotor control, enabling specialized policies to develop even human-champion-level performance in single-task scenarios. However, these specialized policies often struggle with novel tasks, requiring a complete retraining of the policy from scratch. To address this limitation, this paper presents a novel multi-task reinforcement learning (MTRL) framework tailored for quadrotor control, leveraging the shared physical dynamics of the platform to enhance sample efficiency and task performance. By employing a multi-critic architecture and shared task encoders, our framework facilitates knowledge transfer across tasks, enabling a single policy to execute diverse maneuvers, including high-speed stabilization, velocity tracking, and autonomous racing. Our experimental results, validated both in simulation and real-world scenarios, demonstrate that our framework outperforms baseline approaches in terms of sample efficiency and overall task performance.
References

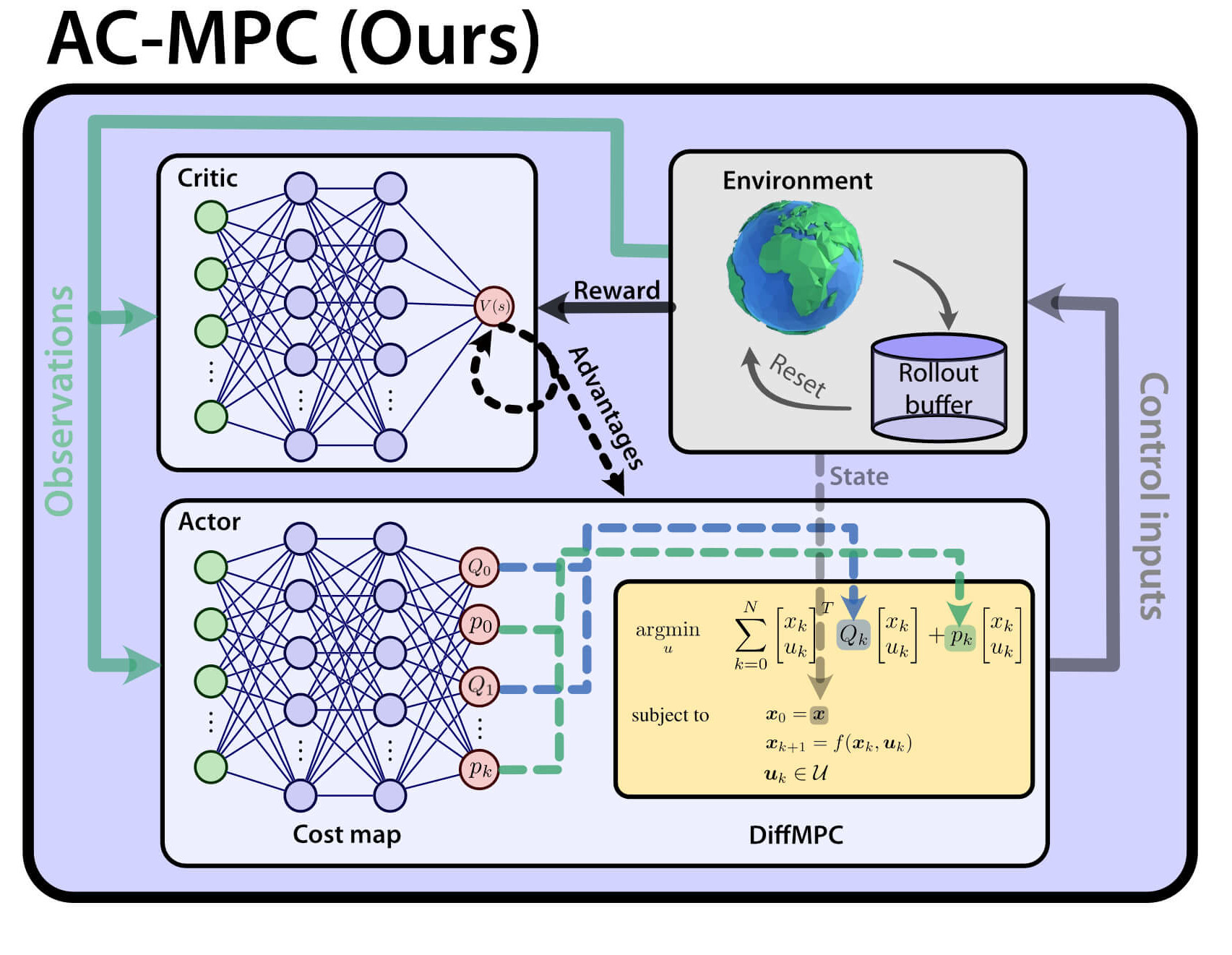
Actor-Critic Model Predictive Control: Differentiable Optimization meets Reinforcement Learning
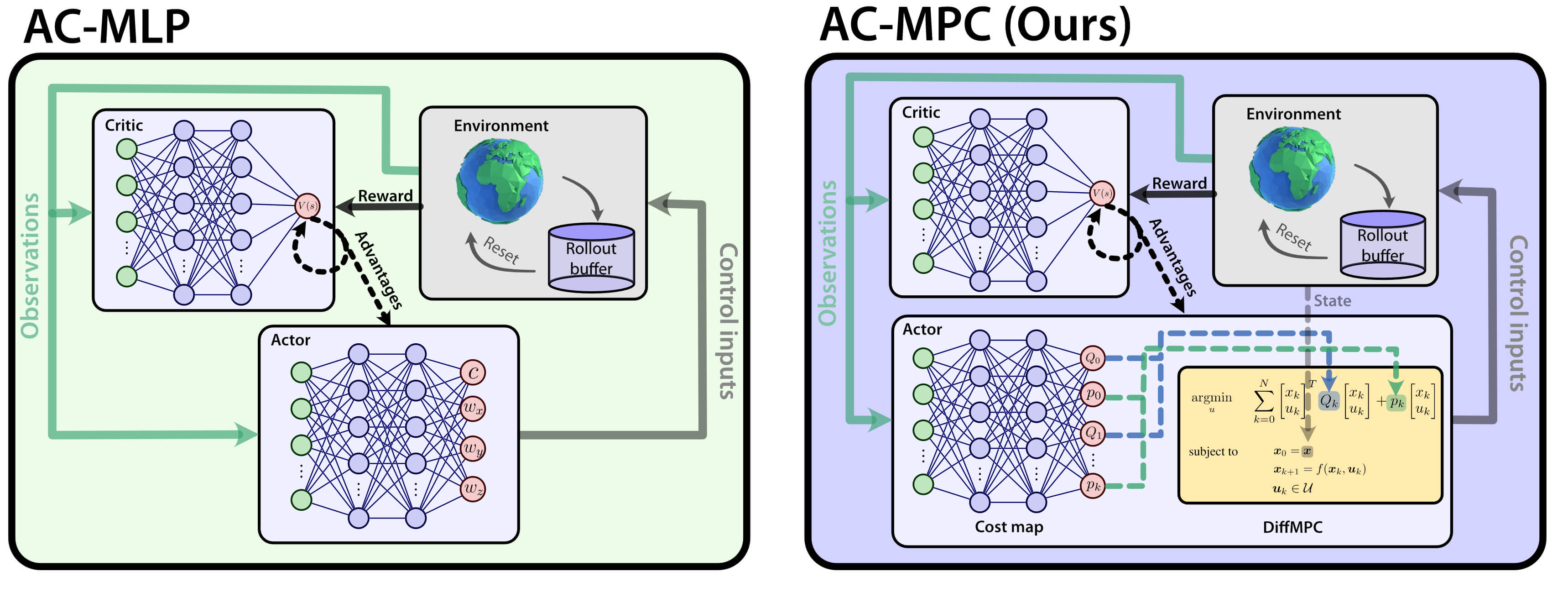
Is it possible to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC)? This extension digs deeper into the answer by studying our new framework called Actor-Critic Model Predictive Control. We conduct a deep study that exposes the benefits of the proposed approach: it achieves better out-of-distribution behaviour, better robustness to changes in the dynamics and improved sample efficiency. Additionally, we conduct an empirical analysis that reveals a relationship between the critic's learned value function and the cost function of the differentiable MPC, providing a deeper understanding of the interplay between the critic's value and the MPC cost functions. Our method achieves the same superhuman performance as state-of-the-art model-free RL, showcasing speeds of up to 21 m/s.
References
Learning Agile, Vision-Based Drone Flight: From Simulation to Reality

We present our latest research in learning deep sensorimotor policies for agile, vision-based quadrotor flight. We show methodologies for the successful transfer of such policies from simulation to the real world. In addition, we discuss the open research questions that still need to be answered to improve the agility and robustness of autonomous drones toward human-pilot performance.
References
Improving safety in physical human-robot collaboration via deep metric learning
Direct physical interaction with robots is becoming increasingly important in flexible production scenarios, but robots without protective fences also pose a greater risk to the operator. In order to keep the risk potential low, relatively simple measures are prescribed for operation, such as stopping the robot if there is physical contact or if a safety distance is violated. Although human injuries can be largely avoided in this way, all such solutions have in common that real cooperation between humans and robots is hardly possible and therefore the advantages of working with such systems cannot develop its full potential. In human-robot collaboration scenarios, more sophisticated solutions are required that make it possible to adapt the robot's behavior to the operator and/or the current situation. Most importantly, during free robot movement, physical contact must be allowed for meaningful interaction and not recognized as a collision. However, here lies a key challenge for future systems: detecting human contact by using robot proprioception and machine learning algorithms. This work uses the Deep Metric Learning (DML) approach to distinguish between non-contact robot movement, intentional contact aimed at physical human-robot interaction, and collision situations. The achieved results are promising and show show that DML achieves 98.6\% accuracy, which is 4\% higher than the existing standards (i.e. a deep learning network trained without DML). It also indicates a promising generalization capability for easy portability to other robots (target robots) by detecting contact (distinguishing between contactless and intentional or accidental contact) without having to retrain the model with target robot data.
References

Improving safety in physical human-robot collaboration via deep metric learning
IEEE 27th International Conference on Emerging Technologies and Factory Automation (ETFA), 2022.
COVERED, CollabOratiVE Robot Environment Dataset for 3D Semantic segmentation

Safe human-robot collaboration (HRC) has recently gained a lot of interest with the emerging Industry 5.0 paradigm. Conventional robots are being replaced with more intelligent and flexible collaborative robots (cobots). Safe and efficient collaboration between cobots and humans largely relies on the cobot's comprehensive semantic understanding of the dynamic surrounding of industrial environments. Despite the importance of semantic understanding for such applications, 3D semantic segmentation of collaborative robot workspaces lacks sufficient research and dedicated datasets. The performance limitation caused by insufficient datasets is called 'data hunger' problem. To overcome this current limitation, this work develops a new dataset specifically designed for this use case, named "COVERED", which includes point-wise annotated point clouds of a robotic cell. Lastly, we also provide a benchmark of current state-of-the-art (SOTA) algorithm performance on the dataset and demonstrate a real-time semantic segmentation of a collaborative robot workspace using a multi- LiDAR system. The promising results from using the trained Deep Networks on a real-time dynamically changing situation shows that we are on the right track. Our perception pipeline achieves 20Hz throughput with a prediction point accuracy of >96\% and >92\% mean intersection over union (mIOU) while maintaining an 8Hz throughput.
References
Wearable robots for the real world need vision
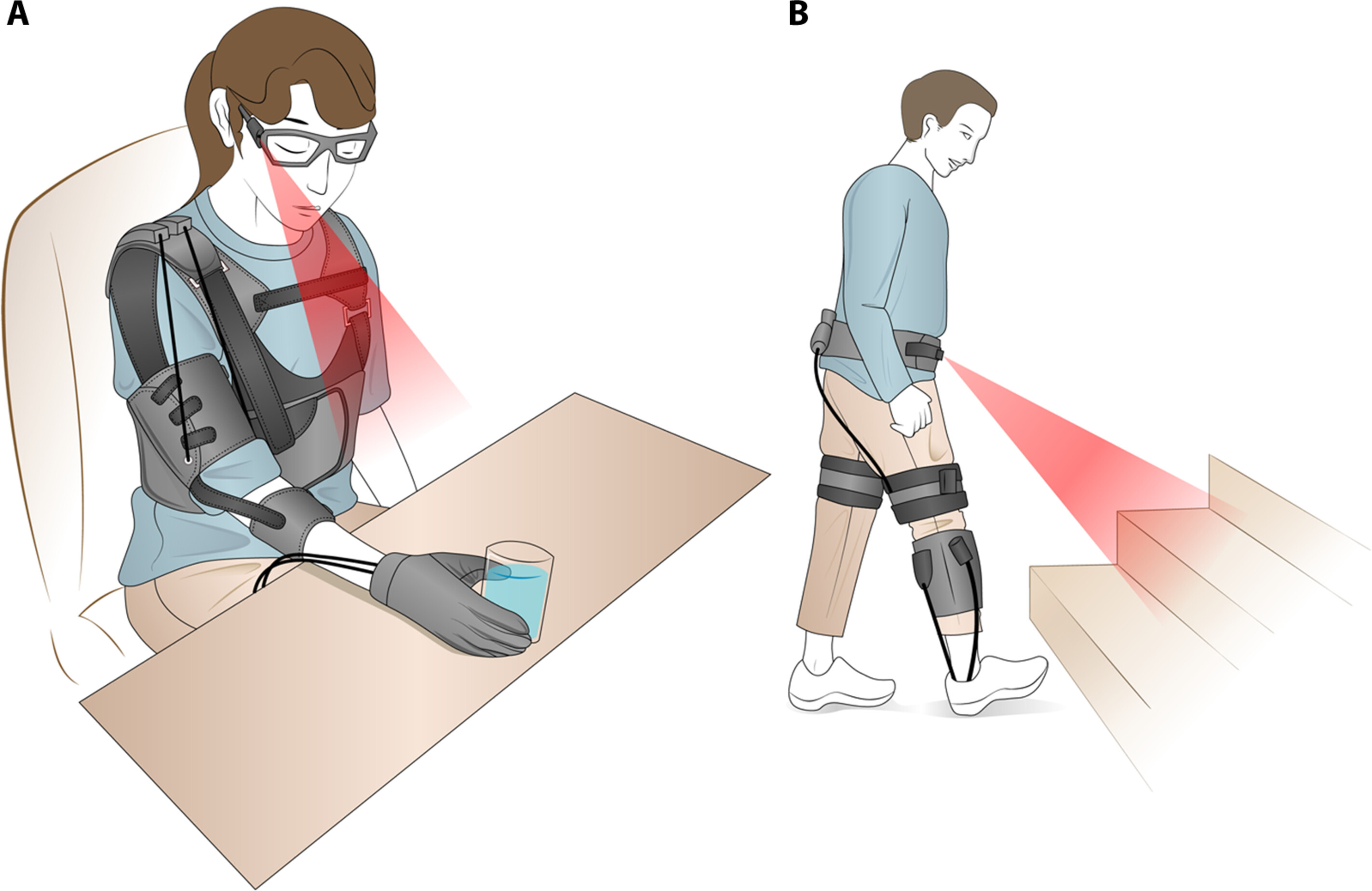
(A) In a vision-based grasp assistance system, the user might wear glasses with a camera and a robotic glove that augments grasp forces. The system can use machine learning–based image processing to classify the target object and infer the likely task the user wants to accomplish. In the example shown here, the system recognizes a full glass of water and infers that the user intends to take a drink. The system then selects a wrap grasp tailored to the size of the glass and closes the hand when vision indicates that the fingers surround the glass (10). (B) A lower-limb assistance system can integrate wearable sensors and vision to expand the range of assistance that can be provided. In this representative example, a vision system detects a staircase in the user's path. The system uses inertial measurement units to detect heel strikes and estimates which footfall will be the first on a raised step. The wearable robot controller then triggers extra assistance torque to help raise the user's center of gravity, with precise timing of the assistance adjusted by EMG signals indicating the user's leg muscle activation.
References
Learning Quadruped Locomotion Using Differentiable Simulation
This work explores the potential of using differentiable simulation for learning quadruped locomotion. Differentiable simulation promises fast convergence and stable training by computing low-variance first-order gradients using robot dynamics. However, its usage for legged robots is still limited to simulation. The main challenge lies in the complex optimization landscape of robotic tasks due to discontinuous dynamics. This work proposes a new differentiable simulation framework to overcome these challenges. Our approach combines a high-fidelity, non-differentiable simulator for forward dynamics with a simplified surrogate model for gradient backpropagation. This approach maintains simulation accuracy by aligning the robot states from the surrogate model with those of the precise, non-differentiable simulator. Our framework enables learning quadruped walking in simulation in minutes without parallelization. When augmented with GPU parallelization, our approach allows the quadruped robot to master diverse locomotion skills on challenging terrains in minutes. We demonstrate that differentiable simulation outperforms a reinforcement learning algorithm (PPO) by achieving significantly better sample efficiency while maintaining its effectiveness in handling large-scale environments. Our method represents one of the first successful applications of differentiable simulation to real-world quadruped locomotion, offering a compelling alternative to traditional RL methods.
References
Learning to Walk and Fly with Adversarial Motion Priors

Robot multimodal locomotion encompasses the ability to transition between walking and flying, representing a significant challenge in robotics. This work presents an approach that enables automatic smooth transitions between legged and aerial locomotion. Leveraging the concept of Adversarial Motion Priors, our method allows the robot to imitate motion datasets and accomplish the desired task without the need for complex reward functions. The robot learns walking patterns from human-like gaits and aerial locomotion patterns from motions obtained using trajectory optimization. Through this process, the robot adapts the locomotion scheme based on environmental feedback using reinforcement learning, with the spontaneous emergence of mode-switching behavior. The results highlight the potential for achieving multimodal locomotion in aerial humanoid robotics through automatic control of walking and flying modes, paving the way for applications in diverse domains such as search and rescue, surveillance, and exploration missions. This research contributes to advancing the capabilities of aerial humanoid robots in terms of versatile locomotion in various environments.
References
S7: Selective and Simplified State Space Layers for Sequence Modeling
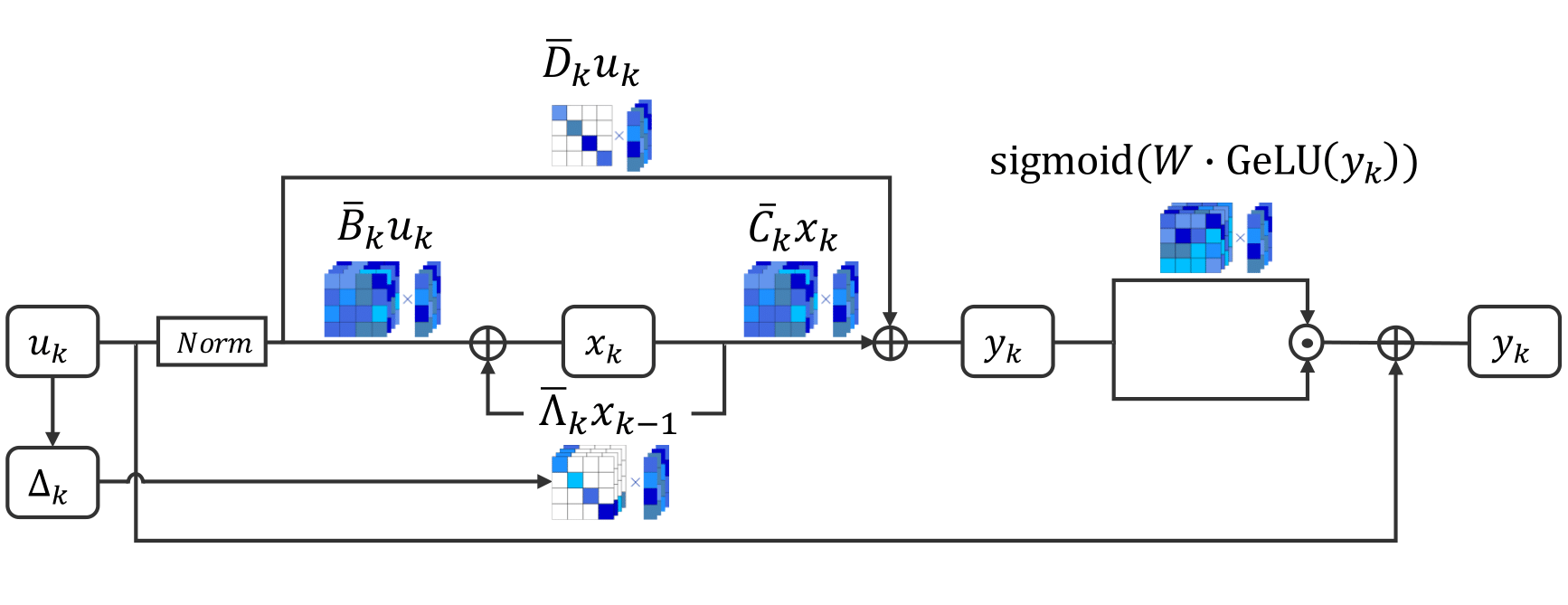
A central challenge in sequence modeling is efficiently handling tasks with extended contexts. While recent state-space models (SSMs) have made significant progress in this area, they often lack input-dependent filtering or require substantial increases in model complexity to handle input variability. We address this gap by introducing S7, a simplified yet powerful SSM that can handle input dependence while incorporating stable reparameterization and specific design choices to dynamically adjust state transitions based on input content, maintaining efficiency and performance. We prove that this reparameterization ensures stability in long-sequence modeling by keeping state transitions well-behaved over time. Additionally, it controls the gradient norm, enabling efficient training and preventing issues like exploding or vanishing gradients. S7 significantly outperforms baselines across various sequence modeling tasks, including neuromorphic event-based datasets, Long Range Arena benchmarks, and various physical and biological time series. Overall, S7 offers a more straightforward approach to sequence modeling without relying on complex, domain-specific inductive biases, achieving significant improvements across key benchmarks.
References
End-to-End Learned Event- and Image-based Visual Odometry
Visual Odometry (VO) is crucial for autonomous robotic navigation, especially in GPS-denied environments like planetary terrains. To improve robustness, recent model-based VO systems have begun combining standard and event-based cameras. While event cameras excel in low-light and high-speed motion, standard cameras provide dense and easier-to-track features. However, the field of image- and event-based VO still predominantly relies on model-based methods and is yet to fully integrate recent image-only advancements leveraging end-to-end learning-based architectures. Seamlessly integrating the two modalities remains challenging due to their different nature, one asynchronous, the other not, limiting the potential for a more effective image- and event-based VO. We introduce RAMP-VO, the first end-to-end learned image- and event-based VO system. It leverages novel Recurrent, Asynchronous, and Massively Parallel (RAMP) encoders capable of fusing asynchronous events with image data, providing 8x faster inference and 33% more accurate predictions than existing solutions. Despite being trained only in simulation, RAMP-VO outperforms previous methods on the newly introduced Apollo and Malapert datasets, and on existing benchmarks, where it improves image- and event-based methods by 58.8% and 30.6%, paving the way for robust and asynchronous VO in space.
References
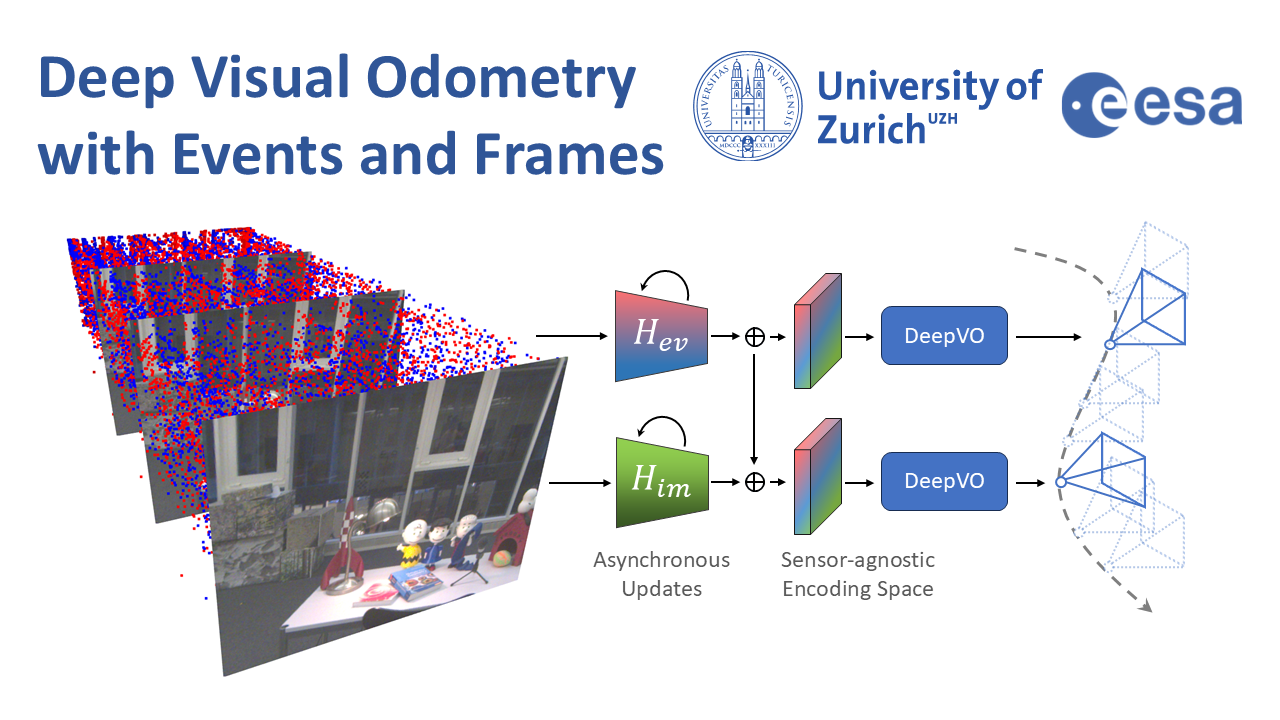
Deep Visual Odometry with Events and Frames
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024.
Reinforcement Learning Meets Visual Odometry
Visual Odometry (VO) is essential to downstream mobile robotics and augmented/virtual reality tasks. Despite recent advances, existing VO methods still rely on heuristic design choices that require several weeks of hyperparameter tuning by human experts, hindering generalizability and robustness. We address these challenges by reframing VO as a sequential decision-making task and applying Reinforcement Learning (RL) to adapt the VO process dynamically. Our approach introduces a neural network, operating as an agent within the VO pipeline, to make decisions such as keyframe and grid-size selection based on real-time conditions. Our method minimizes reliance on heuristic choices using a reward function based on pose error, runtime, and other metrics to guide the system. Our RL framework treats the VO system and the image sequence as an environment, with the agent receiving observations from keypoints, map statistics, and prior poses. Experimental results using classical VO methods and public benchmarks demonstrate improvements in accuracy and robustness, validating the generalizability of our RL-enhanced VO approach to different scenarios. We believe this paradigm shift advances VO technology by eliminating the need for time-intensive parameter tuning of heuristics.
References

Demonstrating Agile Flight from Pixels without State Estimation
We present the first vision-based quadrotor system that autonomously navigates through a sequence of gates at high speeds while directly mapping pixels to control commands. Like professional drone-racing pilots, our system does not use explicit state estimation and leverages the same control commands humans use (collective thrust and body rates). We demonstrate agile flight at speeds up to 40km/h with accelerations up to 2g. This is achieved by training vision-based policies with reinforcement learning (RL). The training is facilitated using an asymmetric actor-critic with access to privileged information. To overcome the computational complexity during image-based RL training, we use the inner edges of the gates as a sensor abstraction. Our approach enables autonomous agile flight with standard, off-the-shelf hardware.
References

Low Latency Automotive Vision with Event Cameras

The computer vision algorithms used in today's advanced driver assistance systems rely on image-based RGB cameras, leading to a critical bandwidth-latency trade-off for delivering safe driving experiences. To address this, event cameras have emerged as alternative vision sensors. Event cameras measure changes in intensity asynchronously, offering high temporal resolution and sparsity, drastically reducing bandwidth and latency requirements. Despite these advantages, event camera-based algorithms are either highly efficient but lag behind image-based ones in terms of accuracy or sacrifice the sparsity and efficiency of events to achieve comparable results. To overcome this, we propose a novel hybrid event- and frame-based object detector that preserves the advantages of each modality and thus does not suffer from this tradeoff. Our method exploits the high temporal resolution and sparsity of events and the rich but low temporal resolution information in standard images to generate efficient, high-rate object detections, reducing perceptual and computational latency. We show that the use of a 20 Hz RGB camera plus an event camera can achieve the same latency as a 5,000 Hz camera with the bandwidth of a 45 Hz camera without compromising accuracy. Our approach paves the way for efficient and robust perception in edge-case scenarios by uncovering the potential of event cameras.
References

Low Latency Automotive Vision with Event Cameras
Nature, 2024.
PDF Open Access Code Training code Dataset Dataset Helper Tools YouTube
State Space Models for Event Cameras
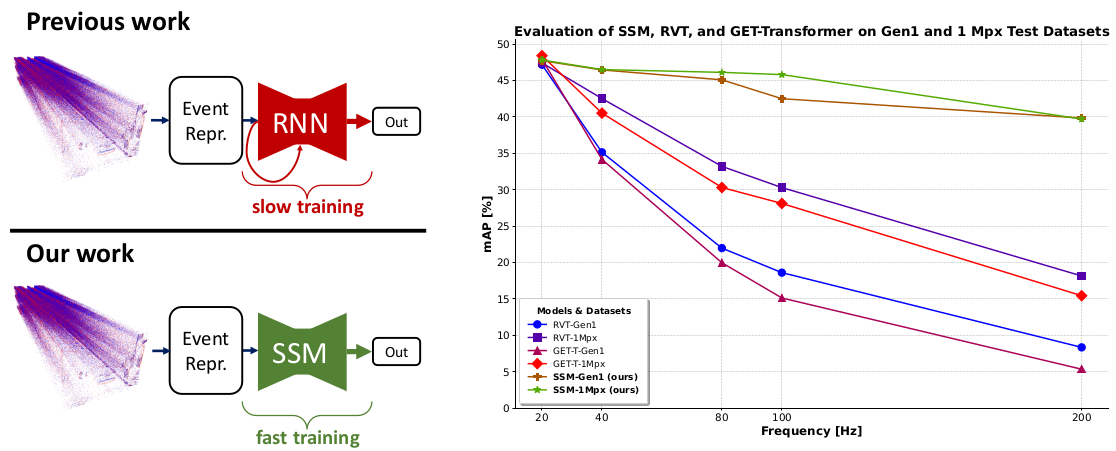
Today, state-of-the-art deep neural networks that process event-camera data first convert a temporal window of events into dense, grid-like input representations. As such, they exhibit poor generalizability when deployed at higher inference frequencies (i.e., smaller temporal windows) than the ones they were trained on. We address this challenge by introducing state-space models (SSMs) with learnable timescale parameters to event-based vision. This design adapts to varying frequencies without the need to retrain the network at different frequencies. Additionally, we investigate two strategies to counteract aliasing effects when deploying the model at higher frequencies. We comprehensively evaluate our approach against existing methods based on RNN and Transformer architectures across various benchmarks, including Gen1 and 1 Mpx event camera datasets. Our results demonstrate that SSM-based models train 33% faster and also exhibit minimal performance degradation when tested at higher frequencies than the training input. Traditional RNN and Transformer models exhibit performance drops of more than 20 mAP, with SSMs having a drop of 3.76 mAP, highlighting the effectiveness of SSMs in event-based vision tasks.
References
Mitigating Motion Blur in Neural Radiance Fields with Events and Frames
Neural Radiance Fields (NeRFs) have shown great potential in novel view synthesis. However, they struggle to render sharp images when the data used for training is affected by motion blur. On the other hand, event cameras excel in dynamic scenes as they measure brightness changes with microsecond resolution and are thus only marginally affected by blur. Recent methods attempt to enhance NeRF reconstructions under camera motion by fusing frames and events. However, they face challenges in recovering accurate color content or constrain the NeRF to a set of predefined camera poses, harming reconstruction quality in challenging conditions. This paper proposes a novel formulation addressing these issues by leveraging both model- and learning-based modules. We explicitly model the blur formation process, exploiting the event double integral as an additional model-based prior. Additionally, we model the event-pixel response using an end-to-end learnable response function, allowing our method to adapt to non-idealities in the real event-camera sensor. We show, on synthetic and real data, that the proposed approach outperforms existing deblur NeRFs that use only frames as well as those that combine frames and events by +6.13dB and +2.48dB, respectively.
References
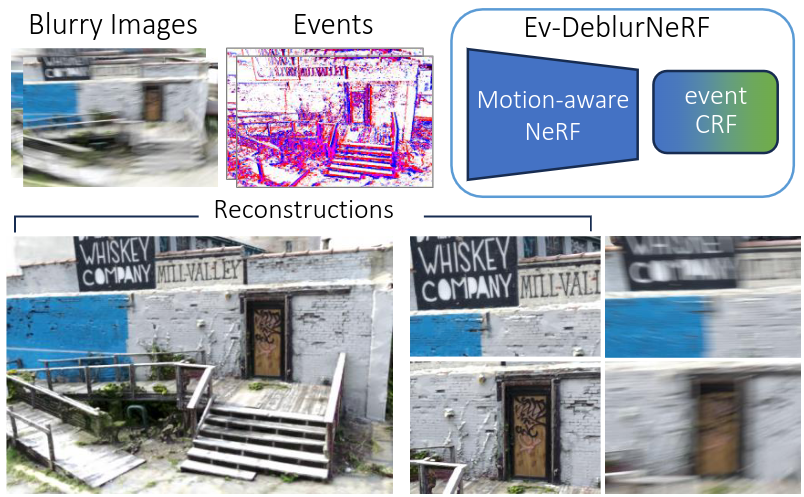
Mitigating Motion Blur in Neural Radiance Fields with Events and Frames
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2024.
Learning Quadruped Locomotion Using Differentiable Simulation
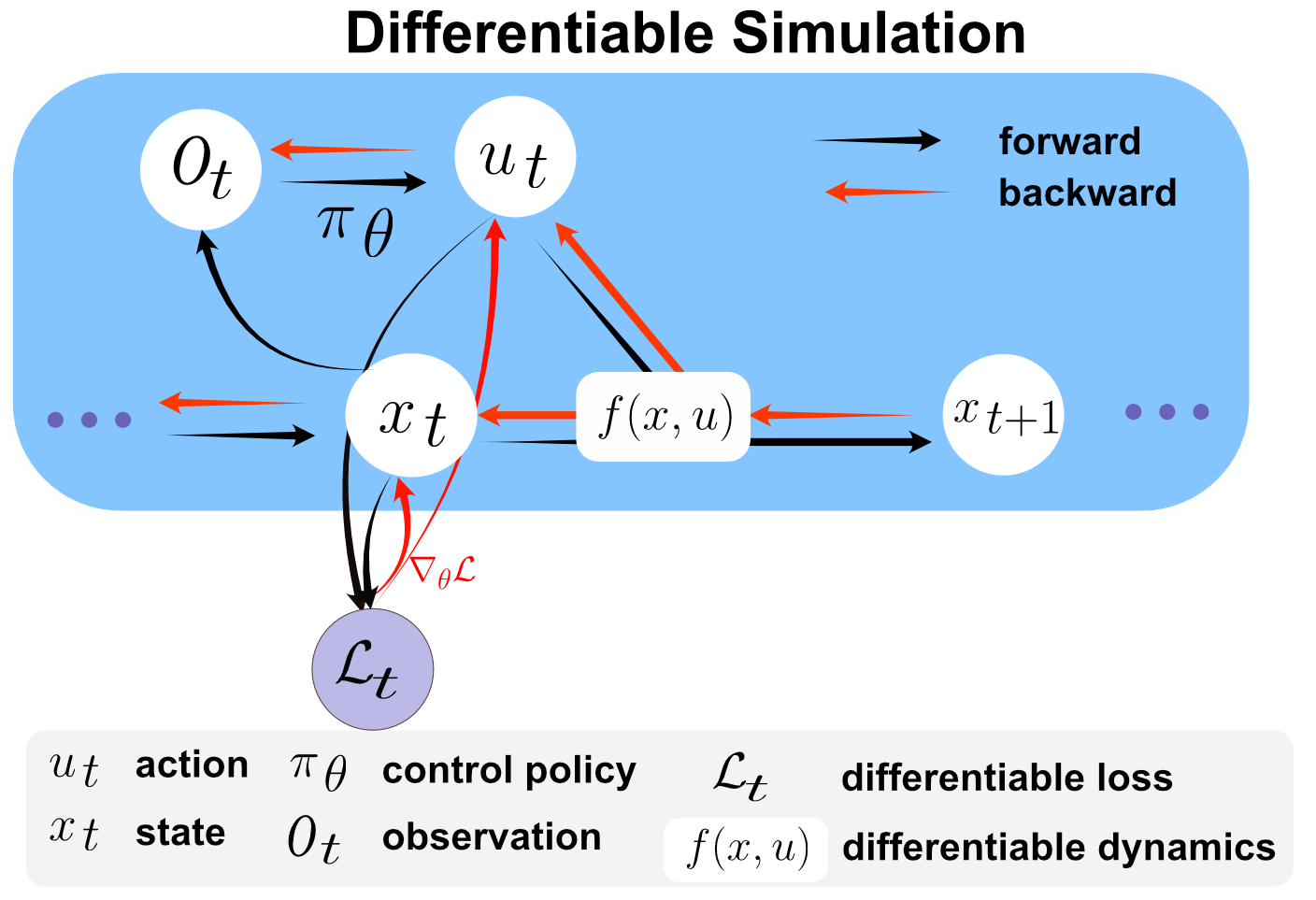
While most recent advancements in legged robot control have been driven by model-free reinforcement learning, we explore the potential of differentiable simulation. Differentiable simulation promises faster convergence and more stable training by computing low-variant first-order gradients using the robot model, but so far, its use for legged robot control has remained limited to simulation. The main challenge with differentiable simulation lies in the complex optimization landscape of robotic tasks due to discontinuities in contact-rich environments, e.g., quadruped locomotion. This work proposes a new, differentiable simulation framework to overcome these challenges. The key idea involves decoupling the complex whole-body simulation, which may exhibit discontinuities due to contact, into two separate continuous domains. Subsequently, we align the robot state resulting from the simplified model with a more precise, non-differentiable simulator to maintain sufficient simulation accuracy. Our framework enables learning quadruped walking in minutes using a single simulated robot without any parallelization. When augmented with GPU parallelization, our approach allows the quadruped robot to master diverse locomotion skills, including trot, pace, bound, and gallop, on challenging terrains in minutes. Additionally, our policy achieves robust locomotion performance in the real world zero-shot. To the best of our knowledge, this work represents the first demonstration of using differentiable simulation for controlling a real quadruped robot. This work provides several important insights into using differentiable simulations for legged locomotion in the real world.
References
Bootstrapping Reinforcement Learning with Imitation for Vision-Based Agile Flight

We combine the effectiveness of Reinforcement Learning (RL) and the efficiency of Imitation Learning (IL) in the context of vision-based, autonomous drone racing. We focus on directly processing visual input without explicit state estimation. While RL offers a general framework for learning complex controllers through trial and error, it faces challenges regarding sample efficiency and computational demands due to the high dimensionality of visual inputs. Conversely, IL demonstrates efficiency in learning from visual demonstrations but is limited by the quality of those demonstrations and faces issues like covariate shift. To overcome these limitations, we propose a novel training framework combining RL and IL advantages. Our framework involves three stages: (i) initial training of a teacher policy using privileged state information, (ii) distilling this policy into a student policy using IL, (iii) performance-constrained adaptive RL fine-tuning. Our experiments in both simulated and real-world environments demonstrate that our approach achieves superior performance and robustness than IL or RL alone in navigating a quadrotor through a racing course using only visual information without explicit state estimation.
References
Actor-Critic Model Predictive Control
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the robustness inherent to MPC.
References

Actor-Critic Model Predictive Control
IEEE International Conference on Robotics and Automation (ICRA), Yokohama, 2024.
Contrastive Learning for Enhancing Robust Scene Transfer in Vision-based Agile Flight
Scene transfer for vision-based mobile robotics applications is a highly relevant and challenging problem. The utility of a robot greatly depends on its ability to perform a task in the real world, outside of a well-controlled lab environment. Existing scene transfer end-to-end policy learning approaches often suffer from poor sample efficiency or limited generalization capabilities, making them unsuitable for mobile robotics applications. This work proposes an adaptive multi- pair contrastive learning strategy for visual representation learning that enables zero-shot scene transfer and real-world deployment. Control policies relying on the embedding are able to operate in unseen environments without the need for finetuning in the deployment environment. We demonstrate the performance of our approach on the task of agile, vision-based quadrotor flight. Extensive simulation and real-world experi- ments demonstrate that our approach successfully generalizes beyond the training domain and outperforms all baselines.
References

Contrastive Initial State Buffer for Reinforcement Learning
In Reinforcement Learning, the trade-off between exploration and exploitation poses a complex challenge for achieving efficient learning from limited samples. While recent works have been effective in leveraging past experiences for policy updates, they often overlook the potential of reusing past experiences for data collection. Independent of the underlying RL algorithm, we introduce the concept of a Contrastive Initial State Buffer, which strategically selects states from past experiences and uses them to initialize the agent in the environment in order to guide it toward more informative states. We validate our approach on two complex robotic tasks without relying on any prior information about the environment: (i) locomotion of a quadruped robot traversing challenging terrains and (ii) a quadcopter drone racing through a track. The experimental results show that our initial state buffer achieves higher task performance than the nominal baseline while also speeding up training convergence.
References

Dense Continuous-Time Optical Flow from Events and Frames
We present a method for estimating dense continuous-time optical flow. Traditional dense optical flow methods compute the pixel displacement between two images. Due to missing information, these approaches cannot recover the pixel trajectories in the blind time between two images. In this work, we show that it is possible to compute per-pixel, continuous-time optical flow by additionally using events from an event camera. Events provide temporally fine-grained information about movement in image space due to their asynchronous nature and microsecond response time. We leverage these benefits to predict pixel trajectories densely in continuous-time via parameterized Bézier curves. To achieve this, we introduce multiple innovations to build a neural network with strong inductive biases for this task: First, we build multiple sequential correlation volumes in time using event data. Second, we use Bézier curves to index these correlation volumes at multiple timestamps along the trajectory. Third, we use the retrieved correlation to update the Bézier curve representations iteratively. Our method can optionally include image pairs to boost performance further. The proposed approach outperforms existing image-based and event-based methods by 11.5 % lower EPE on DSEC-Flow. Finally, we introduce a novel synthetic dataset MultiFlow for pixel trajectory regression on which our method is currently the only successful approach.
References
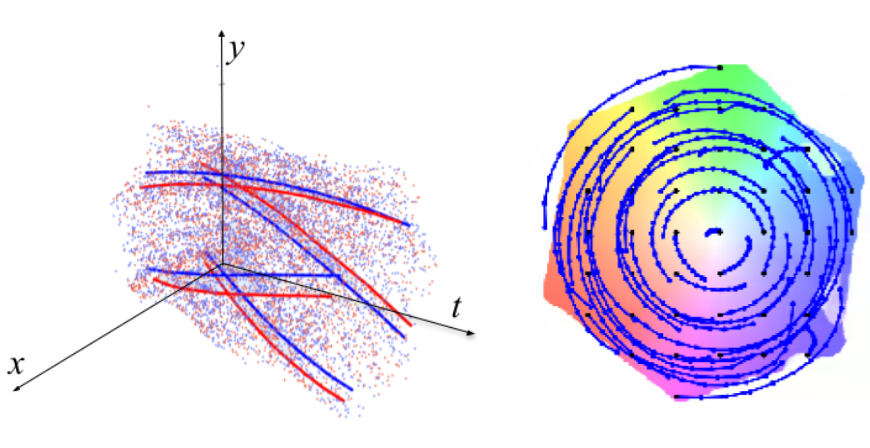
Dense Continuous-Time Optical Flow from Events and Frames
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024.
Seeing Behind Dynamic Occlusions with Event Cameras

Unwanted camera occlusions, such as debris, dust, rain-drops, and snow, can severely degrade the performance of computer-vision systems. Dynamic occlusions are particularly challenging because of the continuously changing pattern. Existing occlusion-removal methods currently use synthetic aperture imaging or image inpainting. However, they face issues with dynamic occlusions as these require multiple viewpoints or user-generated masks to hallucinate the background intensity. We propose a novel approach to reconstruct the background from a single viewpoint in the presence of dynamic occlusions. Our solution relies for the first time on the combination of a traditional camera with an event camera. When an occlusion moves across a background image, it causes intensity changes that trigger events. These events provide additional information on the relative intensity changes between foreground and background at a high temporal resolution, enabling a truer reconstruction of the background content. We show that our method outperforms image inpainting methods by 3dB in terms of PSNR on our dataset.
References
Revisiting Token Pruning for Object Detection and Instance Segmentation
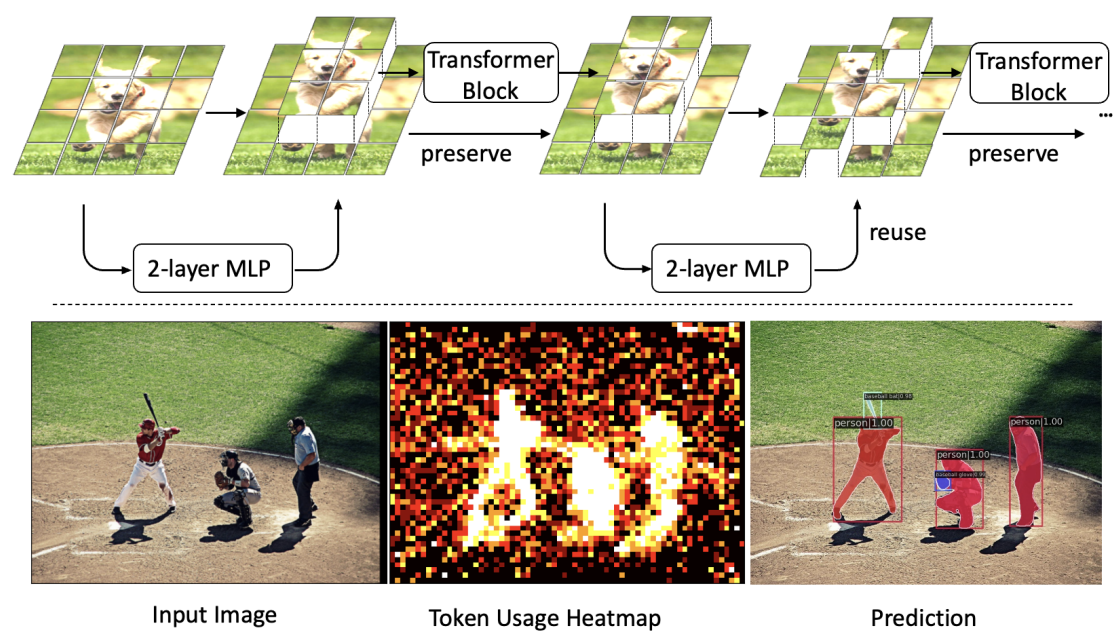
Vision Transformers (ViTs) have shown impressive performance in computer vision, but their high computational cost, quadratic in the number of tokens, limits their adoption in computation-constrained applications. However, this large number of tokens may not be necessary, as not all tokens are equally important. In this paper, we investigate token pruning to accelerate inference for object detection and instance segmentation, extending prior works from image classification. Through extensive experiments, we offer four insights for dense tasks: (i) tokens should not be completely pruned and discarded, but rather preserved in the feature maps for later use. (ii) reactivating previously pruned tokens can further enhance model performance. (iii) a dynamic pruning rate based on images is better than a fixed pruning rate. (iv) a lightweight, 2-layer MLP can effectively prune tokens, achieving accuracy comparable with complex gating networks with a simpler design. We evaluate the impact of these design choices on COCO dataset and present a method integrating these insights that outperforms prior art token pruning models, significantly reducing performance drop from ~1.5 mAP to ~0.3 mAP for both boxes and masks. Compared to the dense counterpart that uses all tokens, our method achieves up to 34% faster inference speed for the whole network and 46% for the backbone.
References

Reaching the Limit in Autonomous Racing: Optimal Control vs. Reinforcement Learning
Why can ReinforcementLearning (RL) achieve results beyond OptimalControl (OC) in many real-world robotics control tasks? We investigate this question in our paper published today in Science Robotics. We argue that this question can be investigated along two axes: the optimization method and the optimization objective. Our results indicate that RL does not outperform OC because RL optimizes its objective better. Rather, RL outperforms OC because it optimizes a better objective. RL can directly optimize a task-level objective and can leverage domain randomization to cope with model uncertainty, allowing the discovery of more robust control responses. Beyond the fundamental study, our work contributes an RL-based controller that delivers the highest performance ever demonstrated on an autonomous racing drone. Our drone achieved remarkable performance: peak acceleration greater than 12 g and peak velocity ~108 km/h, all within minutes of training with a standard workstation.
References

Champion-level Drone Racing using Deep Reinforcement Learning
First-person view (FPV) drone racing is a televised sport in which professional competitors pilot high-speed aircraft through a three-dimensional circuit. Each pilot sees the environment from their drone's perspective via video streamed from an onboard camera. Reaching the level of professional pilots with an autonomous drone is challenging since the robot needs to fly at its physical limits while estimating its speed and location in the circuit exclusively from onboard sensors. Here we introduce Swift, an autonomous system that can race physical vehicles at the level of the human world champions. The system combines deep reinforcement learning in simulation with data collected in the physical world. Swift competed against three human champions, including the world champions of two international leagues, in real-world head-to-head races. Swift won multiple races against each of the human champions and demonstrated the fastest recorded race time. This work represents a milestone for mobile robotics and machine intelligence, which may inspire the deployment of hybrid learning-based solutions in other physical systems.
References

Champion-level Drone Racing using Deep Reinforcement Learning
Nature, 2023
Real-time Neural MPC: Deep Learning Model Predictive Control for Quadrotors and Agile Robotic Platforms

Model Predictive Control (MPC) has become a popular framework in embedded control for high-performance autonomous systems. However, to achieve good control performance using MPC, an accurate dynamics model is key. To maintain real-time operation, the dynamics models used on embedded systems have been limited to simple first-principle models, which substantially limits their representative power. In contrast to such simple models, machine learning approaches, specifically neural networks, have been shown to accurately model even complex dynamic effects, but their large computational complexity hindered combination with fast real-time iteration loops. With this work, we present Real-time Neural MPC, a framework to efficiently integrate large, complex neural network architectures as dynamics models within a model-predictive control pipeline. Our experiments, performed in simulation and the real world onboard a highly agile quadrotor platform, demonstrate the capabilities of the described system to run learned models with, previously infeasible, large modeling capacity using gradient-based online optimization MPC. Compared to prior implementations of neural networks in online optimization MPC we can leverage models of over 4000 times larger parametric capacity in a 50Hz real-time window on an embedded platform. Further, we show the feasibility of our framework on real-world problems by reducing the positional tracking error by up to 82% when compared to state-of-the-art MPC approaches without neural network dynamics.
References
From Chaos Comes Order: Ordering Event Representations for Object Recognition and Detection
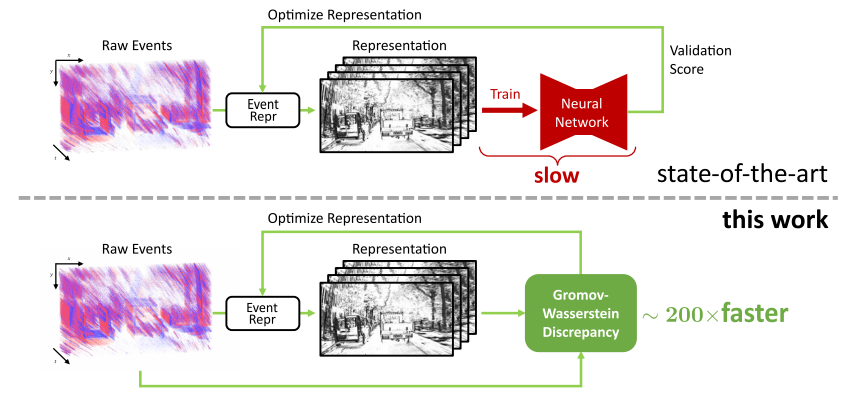
Selecting dense event representations for deep neural networks is exceedingly slow since it involves training a neural network for each representation and selecting the best one based on the validation score. In this work, we eliminate this bottleneck by selecting the representation based on the Gromov-Wasserstein Discrepancy (GWD) on the validation set. This metric is 200 times faster to compute and preserves the task performance ranking of event representations across multiple representations, network backbones, datasets and tasks. We use it to, for the first time, perform a hyperparameter search on a large family of event representations, revealing new and powerful event representations that exceed the state-of-the-art. Our optimized representations outperform existing representations by 1.7 mAP on the 1 Mpx dataset and 0.3 mAP on the Gen1 dataset, two established object detection benchmarks, and reach a 3.8% higher classification score on the mini N-ImageNet benchmark. Moreover, we outperform state-of-the-art by 2.1 mAP on Gen1 and state-of-the-art feed-forward methods by 6.0 mAP on the 1 Mpx datasets. This work opens a new unexplored field of explicit representation optimization for event-based learning.
References
Learning Deep Sensorimotor Policies for Vision-based Autonomous Drone Racing
Autonomous drones can operate in remote and unstructured environments, enabling various real-world applications. However, the lack of effective vision-based algorithms has been a stumbling block to achieving this goal. Existing systems often require hand-engineered components for state estimation, planning, and control. Such a sequential design involves laborious tuning, human heuristics, and compounding delays and errors. This paper tackles the vision-based autonomous-drone racing problem by learning deep sensorimotor policies. We use contrastive learning to extract robust feature representations from the input images and leverage a two-stage learning-by-cheating framework for training a neural network policy. The resulting policy directly infers control commands with feature representations learned from raw images, forgoing the need for globally-consistent state estimation, trajectory planning, and handcrafted control design. Our experimental results indicate that our vision-based policy can achieve the same level of racing performance as the state-based policy while being robust against different visual disturbances and distractors. This work serves as a stepping-stone toward developing intelligent vision-based autonomous systems that control the drone purely from image inputs, like human pilots.
References

E-NeRF: Neural Radiance Fields from a Moving Event Camera
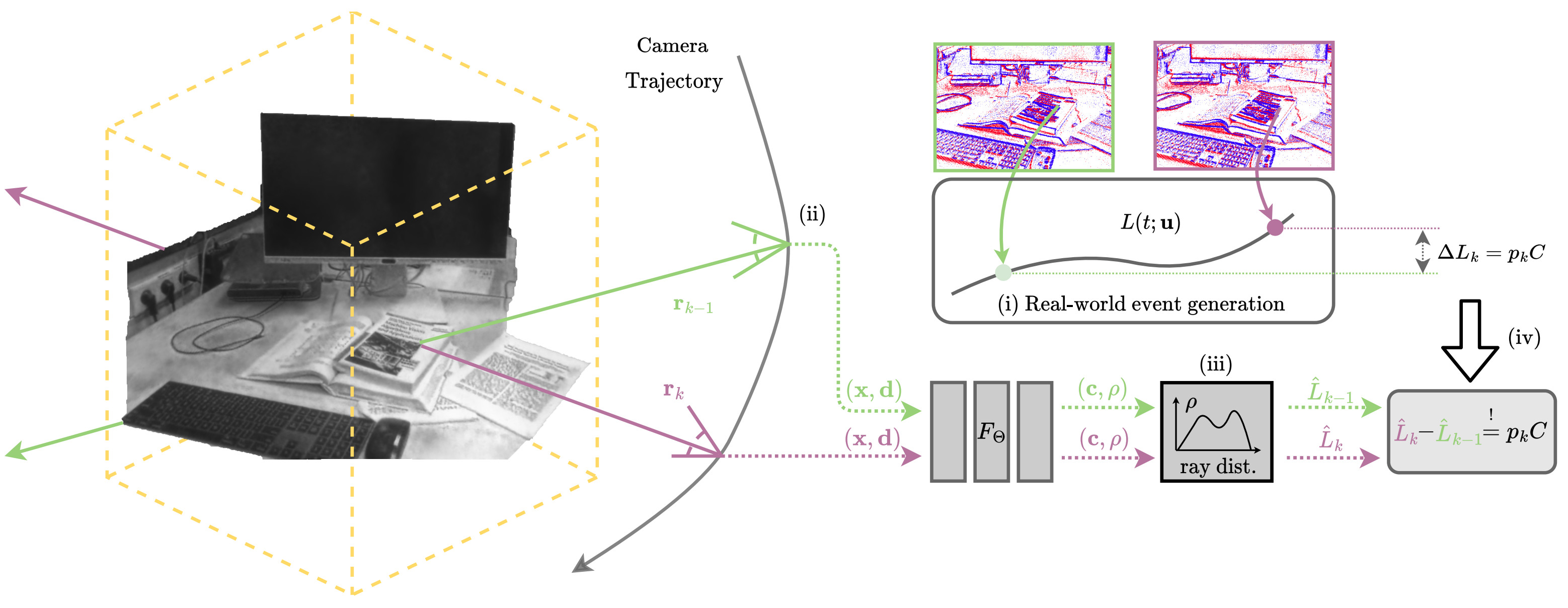
Estimating neural radiance fields (NeRFs) from "ideal" images has been extensively studied in the computer vision community. Most approaches assume optimal illumination and slow camera motion. These assumptions are often violated in robotic applications, where images may contain motion blur, and the scene may not have suitable illumination. This can cause significant problems for downstream tasks such as navigation, inspection, or visualization of the scene. To alleviate these problems, we present E-NeRF, the first method which estimates a volumetric scene representation in the form of a NeRF from a fast-moving event camera. Our method can recover NeRFs during very fast motion and in high-dynamic-range conditions where frame-based approaches fail. We show that rendering high-quality frames is possible by only providing an event stream as input. Furthermore, by combining events and frames, we can estimate NeRFs of higher quality than state-of-the-art approaches under severe motion blur. We also show that combining events and frames can overcome failure cases of NeRF estimation in scenarios where only a few input views are available without requiring additional regularization.
References
Training Efficient Controllers via Analytic Policy Gradient
Control design for robotic systems is complex and often requires solving an optimization to follow a trajectory accurately. Online optimization approaches like Model Predictive Control (MPC) have been shown to achieve great tracking performance, but require high computing power. Conversely, learning-based offline optimization approaches, such as Reinforcement Learning (RL), allow fast and efficient execution on the robot but hardly match the accuracy of MPC in trajectory tracking tasks. In systems with limited compute, such as aerial vehicles, an accurate controller that is efficient at execution time is imperative. We propose an Analytic Policy Gradient (APG) method to tackle this problem. APG exploits the availability of differentiable simulators by training a controller offline with gradient descent on the tracking error. We address training instabilities that frequently occur with APG through curriculum learning and experiment on a widely used controls benchmark, the CartPole, and two common aerial robots, a quadrotor and a fixed-wing drone. Our proposed method outperforms both model-based and model-free RL methods in terms of tracking error. Concurrently, it achieves similar performance to MPC while requiring more than an order of magnitude less computation time. Our work provides insights into the potential of APG as a promising control method for robotics. To facilitate the exploration of APG, we open-source our code and make it publicly available.
References

Neuromorphic Optical Flow and Real-time Implementation with Event Cameras
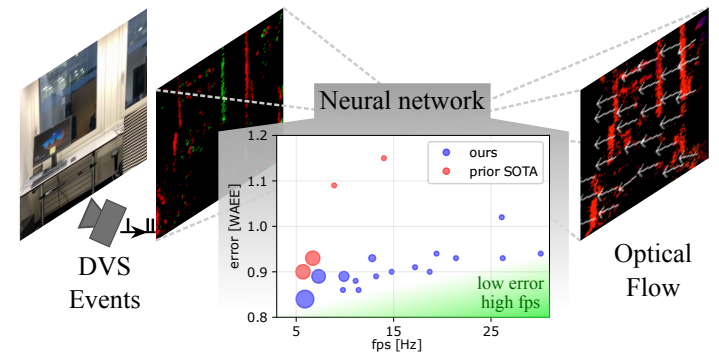
We present a new spiking neural network (SNN) architecture that significantly improves optical flow prediction accuracy while reducing complexity, making it ideal for real-time applications in edge devices and robots. By leveraging event-based vision and SNNs, our solution achieves high-speed optical flow prediction with nearly two orders of magnitude less complexity, without compromising accuracy. This breakthrough paves the way for efficient real-time deployments in various computer vision pipelines.
References
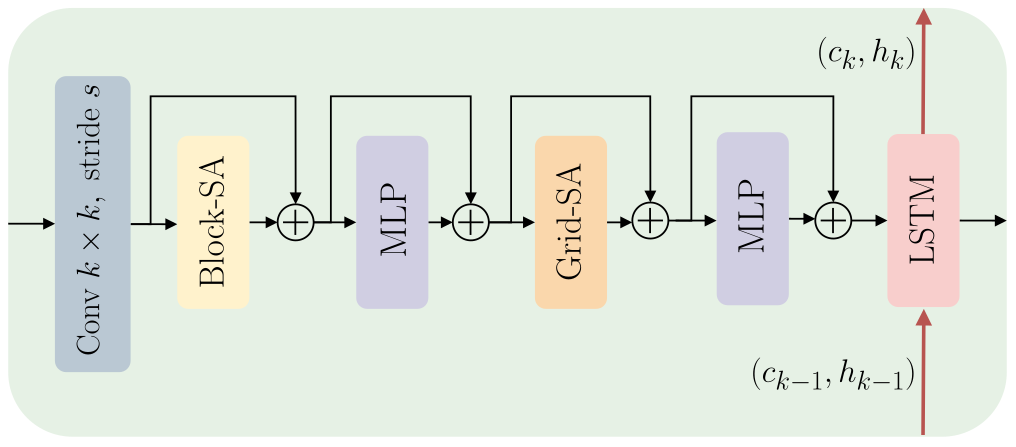
Recurrent Vision Transformers for Object Detection with Event Cameras
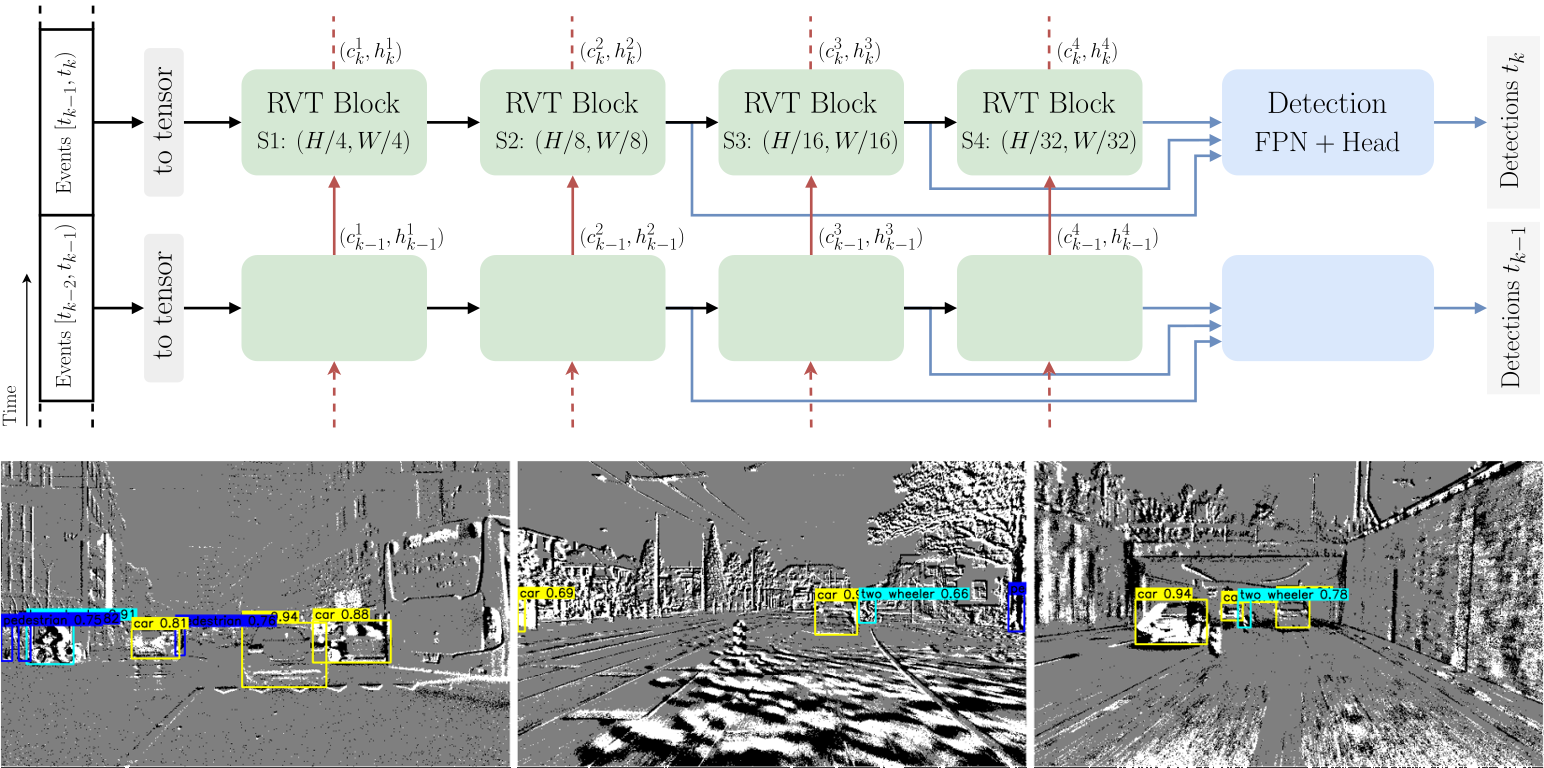
We present Recurrent Vision Transformers (RVTs), a novel backbone for object detection with event cameras. Event cameras provide visual information with sub-millisecond latency at a high-dynamic range and with strong robustness against motion blur. These unique properties offer great potential for low-latency object detection and tracking in time-critical scenarios. Prior work in event-based vision has achieved outstanding detection performance but at the cost of substantial inference time, typically beyond 40 milliseconds. By revisiting the high-level design of recurrent vision backbones, we reduce inference time by a factor of 5 while retaining similar performance. To achieve this, we explore a multi-stage design that utilizes three key concepts in each stage: First, a convolutional prior that can be regarded as a conditional positional embedding. Second, local- and dilated global self-attention for spatial feature interaction. Third, recurrent temporal feature aggregation to minimize latency while retaining temporal information. RVTs can be trained from scratch to reach state-of-the-art performance on event-based object detection - achieving an mAP of 47.2% on the Gen1 automotive dataset. At the same time, RVTs offer fast inference (12 ms on a T4 GPU) and favorable parameter efficiency (5 times fewer than prior art). Our study brings new insights into effective design choices that could be fruitful for research beyond event-based vision.
References
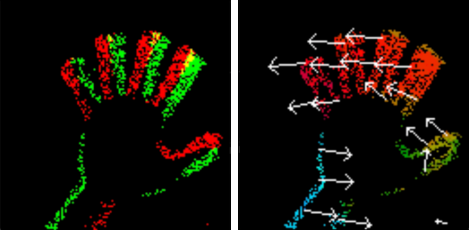
Data-driven Feature Tracking for Event Cameras
Because of their high temporal resolution, increased resilience to motion blur, and very sparse output, event cameras have been shown to be ideal for low-latency and low-bandwidth feature tracking, even in challenging scenarios. Existing feature tracking methods for event cameras are either handcrafted or derived from first principles but require extensive parameter tuning, are sensitive to noise, and do not generalize to different scenarios due to unmodeled effects. To tackle these deficiencies, we introduce the first data-driven feature tracker for event cameras, which leverages low-latency events to track features detected in a grayscale frame. We achieve robust performance via a novel frame attention module, which shares information across feature tracks. By directly transferring zero-shot from synthetic to real data, our data-driven tracker outperforms existing approaches in relative feature age by up to 120 % while also achieving the lowest latency. This performance gap is further increased to 130 % by adapting our tracker to real data with a novel self-supervision strategy.
References

Event-based Agile Object Catching with a Quadrupedal Robot

Quadrupedal robots are conquering various applications in indoor and outdoor environments due to their capability to navigate challenging uneven terrains. Exteroceptive information greatly enhances this capability since perceiving their surroundings allows them to adapt their controller and thus achieve higher levels of robustness. However, sensors such as LiDARs and RGB cameras do not provide sufficient information to quickly and precisely react in a highly dynamic environment since they suffer from a bandwidth-latency tradeoff. They require significant bandwidth at high frame rates while featuring significant perceptual latency at lower frame rates, thereby limiting their versatility on resource constrained platforms. In this work, we tackle this problem by equipping our quadruped with an event camera, which does not suffer from this tradeoff due to its asynchronous and sparse operation. In levering the low latency of the events, we push the limits of quadruped agility and demonstrating high-speed ball catching with a net for the first time. We show that our quadruped equipped with an event-camera can catch objects at maximum speeds of 15 m/s from 4 meters, with a success rate of 83%. With a VGA event camera, our method runs at 100 Hz on an NVIDIA Jetson Orin.
References

A Hybrid ANN-SNN Architecture for Low-Power and Low-Latency Visual Perception
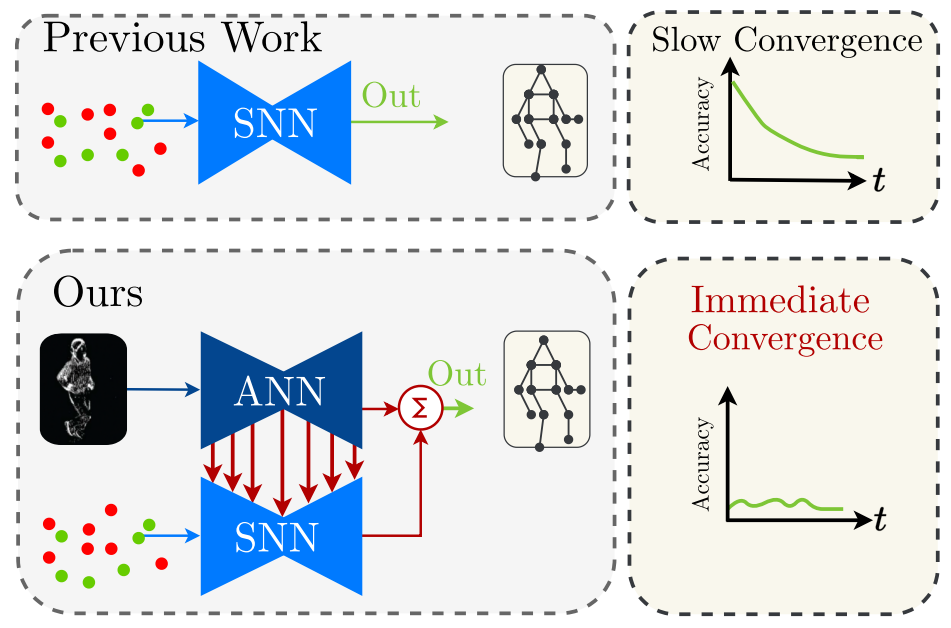
Spiking Neural Networks (SNN) are a class of bioinspired neural networks that promise to bring low-power and low-latency inference to edge-devices through the use of asynchronous and sparse processing. However, being temporal models, SNNs depend heavily on expressive states to generate predictions on par with classical artificial neural networks (ANNs). These states converge only after long transient time periods, and quickly decay in the absence of input data, leading to higher latency, power consumption, and lower accuracy. In this work, we address this issue by initializing the state with an auxiliary ANN running at a low rate. The SNN then uses the state to generate predictions with high temporal resolution until the next initialization phase. Our hybrid ANN-SNN model thus combines the best of both worlds: It does not suffer from long state transients and state decay thanks to the ANN, and can generate predictions with high temporal resolution, low latency, and low power thanks to the SNN. We show for the task of eventbased 2D and 3D human pose estimation that our method consumes 88% less power with only a 4% decrease in performance compared to its fully ANN counterparts when run at the same inference rate. Moreover, when compared to SNNs, our method achieves a 74% lower error. This research thus provides a new understanding of how ANNs and SNNs can be used to maximize their respective benefits.
References
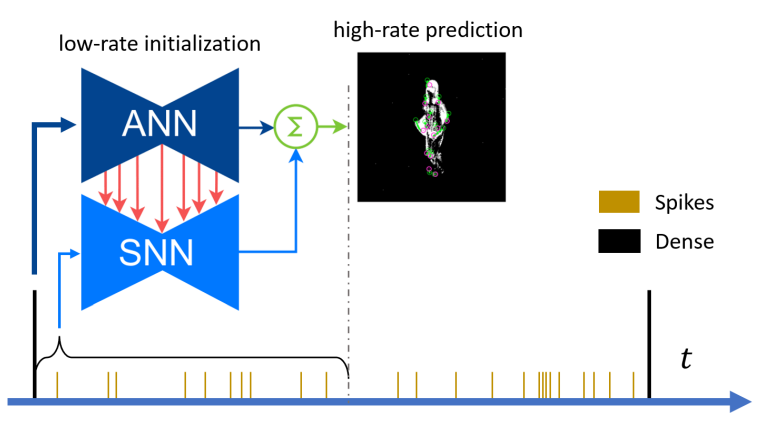
Pushing the Limits of Asynchronous Graph-based Object Detection with Event Cameras
State-of-the-art machine-learning methods for event cameras treat events as dense representations and process them with conventional deep neural networks. Thus, they fail to maintain the sparsity and asynchronous nature of event data, thereby imposing significant computation and latency constraints on downstream systems. A recent line of work tackles this issue by modeling events as spatiotemporally evolving graphs that can be efficiently and asynchronously processed using graph neural networks. These works showed impressive computation reductions, yet their accuracy is still limited by the small scale and shallow depth of their network, both of which are required to reduce computation. In this work, we break this glass ceiling by introducing several architecture choices which allow us to scale the depth and complexity of such models while maintaining low computation. On object detection tasks, our smallest model shows up to 3.7 times lower computation, while outperforming state-of-the-art asynchronous methods by 7.4 mAP. Even when scaling to larger model sizes, we are 13% more efficient than state-of-the-art while outperforming it by 11.5 mAP. As a result, our method runs 3.7 times faster than a dense graph neural network, taking only 8.4 ms per forward pass. This opens the door to efficient, and accurate object detection in edge-case scenarios.
References
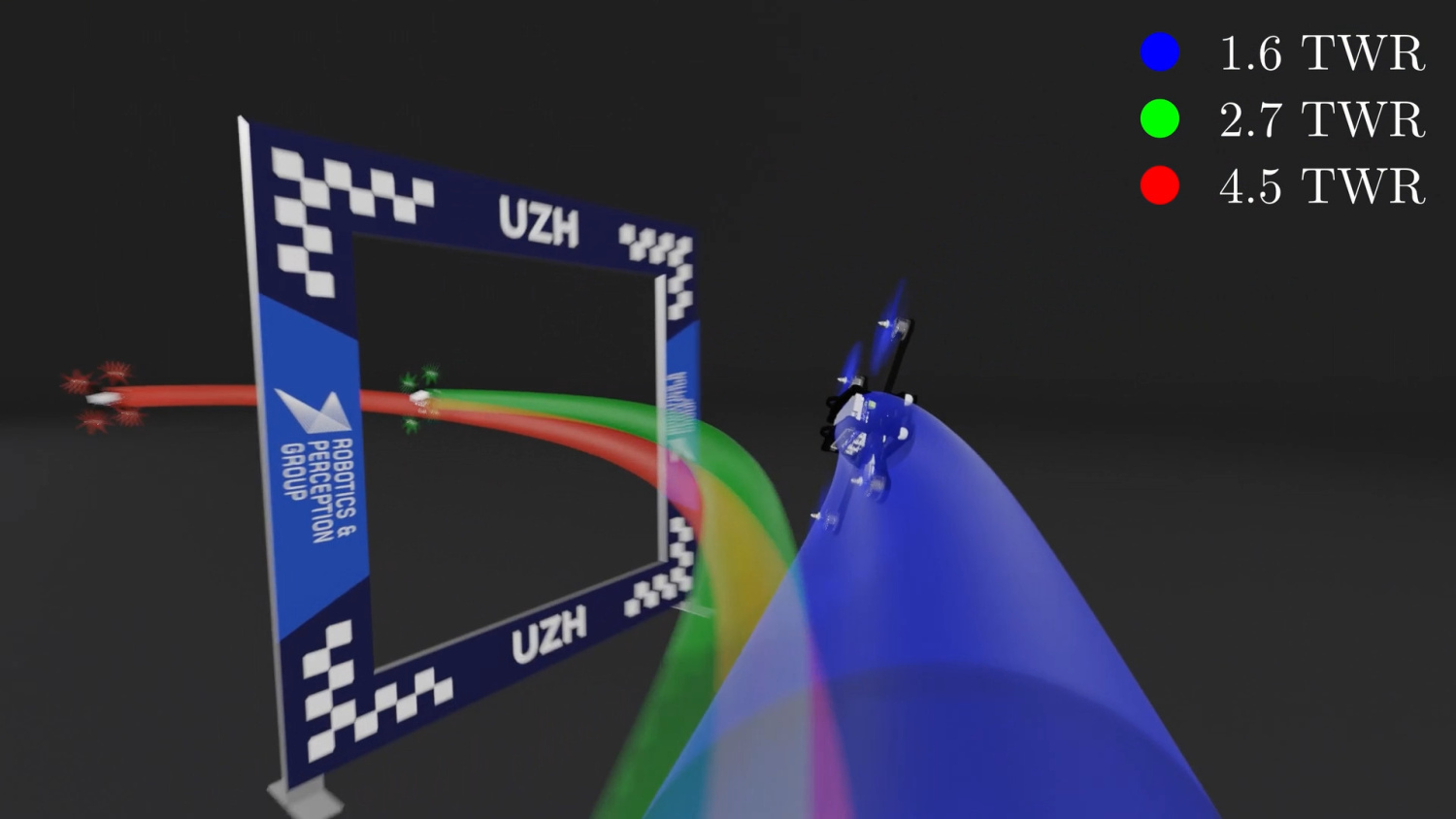
User-Conditioned Neural Control Policies for Mobile Robotics
Recently, learning-based controllers have been shown to push mobile robotic systems to their limits and provide the robustness needed for many real-world applications. However, only classical optimization-based control frameworks offer the inherent flexibility to be dynamically adjusted during execution by, for example, setting target speeds or actuator limits. We present a framework to overcome this shortcoming of neural controllers by conditioning them on an auxiliary input. This advance is enabled by including a feature-wise linear modulation layer (FiLM). We use model-free reinforcement-learning to train quadrotor control policies for the task of navigating through a sequence of waypoints in minimum time. By conditioning the policy on the maximum available thrust or the viewing direction relative to the next waypoint, a user can regulate the aggressiveness of the quadrotor’s flight during deployment. We demonstrate in simulation and in real-world experiments that a single control policy can achieve close to time-optimal flight performance across the entire performance envelope of the robot, reaching up to 60 km/h and 4.5 g in acceleration. The ability to guide a learned controller during task execution has implications beyond agile quadrotor flight, as conditioning the control policy on human intent helps safely bringing learning based systems out of the well-defined laboratory environment into the wild.
References
Learning Perception-Aware Agile Flight in Cluttered Environments
Recently, neural control policies have outperformed existing model-based planning-and-control methods for autonomously navigating quadrotors through cluttered environments in minimum time. However, they are not perception aware, a crucial requirement in vision-based navigation due to the camera's limited field of view and the underactuated nature of a quadrotor. We propose a method to learn neural network policies that achieve perception-aware, minimum-time flight in cluttered environments. Our method combines imitation learning and reinforcement learning (RL) by leveraging a privileged learning-by-cheating framework. Using RL, we first train a perception-aware teacher policy with full-state information to fly in minimum time through cluttered environments. Then, we use imitation learning to distill its knowledge into a vision-based student policy that only perceives the environment via a camera. Our approach tightly couples perception and control, showing a significant advantage in computation speed (10x faster) and success rate. We demonstrate the closed-loop control performance using a physical quadrotor and hardware-in-the-loop simulation at speeds up to 50 km/h.
References

Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Cars
Event cameras are bio-inspired vision sensors that naturally capture the dynamics of a scene, filtering out redundant information. This paper presents a deep neural network approach that unlocks the potential of event cameras on a challenging motion-estimation task: prediction of a vehicle's steering angle. To make the best out of this sensor-algorithm combination, we adapt state-of-the-art convolutional architectures to the output of event sensors and extensively evaluate the performance of our approach on a publicly available large scale event-camera dataset (~1000 km). We present qualitative and quantitative explanations of why event cameras allow robust steering prediction even in cases where traditional cameras fail, e.g. challenging illumination conditions and fast motion. Finally, we demonstrate the advantages of leveraging transfer learning from traditional to event-based vision, and show that our approach outperforms state-of-the-art algorithms based on standard cameras.
References

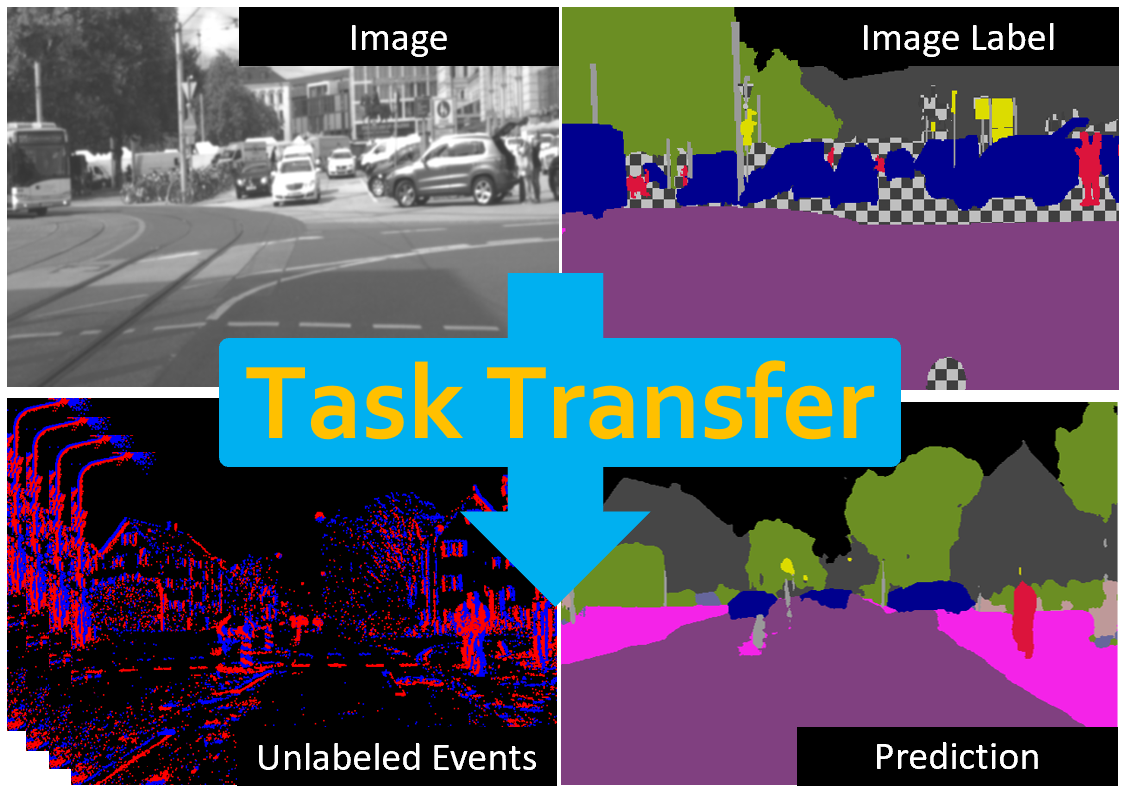
ESS: Learning Event-based Semantic Segmentation from Still Images
References
Multi-Bracket High Dynamic Range Imaging with Event Cameras
References

Time Lens++: Event-based Frame Interpolation with Parametric Non-linear Flow and Multi-scale Fusion

References
Time Lens++: Event-based Frame Interpolation with Parametric Non-linear Flow and Multi-scale Fusion
IEEE Conference of Computer Vision and Pattern Recognition (CVPR), 2022, New Orleans, USA.


Visual Attention Prediction Improves Performance of Autonomous Drone Racing Agents

Humans race drones faster than neural networks trained for end-to-end autonomous flight. This may be related to the ability of human pilots to select task-relevant visual information effectively. This work investigates whether neural networks capable of imitating human eye gaze behavior and attention can improve neural network performance for the challenging task of vision-based autonomous drone racing. We hypothesize that gaze-based attention prediction can be an efficient mechanism for visual information selection and decision making in a simulator-based drone racing task. We test this hypothesis using eye gaze and flight trajectory data from 18 human drone pilots to train a visual attention prediction model. We then use this visual attention prediction model to train an end-to-end controller for vision-based autonomous drone racing using imitation learning. We compare the drone racing performance of the attention-prediction controller to those using raw image inputs and image-based abstractions (i.e., feature tracks). Comparing success rates for completing a challenging race track by autonomous flight, our results show that the attention-prediction based controller (88% success rate) outperforms the RGB-image (61% success rate) and feature-tracks (55% success rate) controller baselines. Furthermore, visual attention-prediction and feature-track based models showed better generalization performance than image-based models when evaluated on hold-out reference trajectories. Our results demonstrate that human visual attention prediction improves the performance of autonomous vision-based drone racing agents and provides an essential step towards vision-based, fast, and agile autonomous flight that eventually can reach and even exceed human performances.
References
A Benchmark Comparison of Learned Control Policies for Agile Quadrotor Flight
Quadrotors are highly nonlinear dynamical systems that require carefully tuned controllers to be pushed to their physical limits. Recently, learning-based control policies have been proposed for quadrotors, as they would potentially allow learning direct mappings from high-dimensional raw sensory observations to actions. Due to sample inefficiency, training such learned controllers on the real platform is impractical or even impossible. Training in simulation is attractive but requires to transfer policies between domains, which demands trained policies to be robust to such domain gap. In this work, we make two contributions: (i) we perform the first benchmark comparison of existing learned control policies for agile quadrotor flight and show that training a control policy that commands body-rates and thrust results in more robust sim-to-real transfer compared to a policy that directly specifies individual rotor thrusts, (ii) we demonstrate for the first time that such a control policy trained via deep reinforcement learning can control a quadrotor in real-world experiments at speeds over 45km/h.
References
Bridging the Gap between Events and Frames through Unsupervised Domain Adaptation
References

Policy Search for Model Predictive Control with Application to Agile Drone Flight
Policy Search and Model Predictive Control (MPC) are two different paradigms for robot control: policy search has the strength of automatically learning complex policies using experienced data, while MPC can offer optimal control performance using models and trajectory optimization. An open research question is how to leverage and combine the advantages of both approaches. In this work, we provide an answer by using policy search for automatically choosing high-level decision variables for MPC, which leads to a novel policy-search-for-model-predictive-control framework. Specifically, we formulate the MPC as a parameterized controller, where the hard-to-optimize decision variables are represented as high-level policies. Such a formulation allows optimizing policies in a self-supervised fashion. We validate this framework by focusing on a challenging problem in agile drone flight: flying a quadrotor through fast-moving gates. Experiments show that our controller achieves robust and real-time control performance in both simulation and the real world. The proposed framework offers a new perspective for merging learning and control.
References

Policy Search for Model Predictive Control with Application to Agile Drone Flight
IEEE Transactions on Robotics (T-RO), 2022.
Learning High-Speed Flight in the Wild

Quadrotors are agile. Unlike most other machines, they can traverse extremely complex environments at high speeds. To date, only expert human pilots have been able to fully exploit their capabilities. Autonomous operation with onboard sensing and computation has been limited to low speeds. State-of-the-art methods generally separate the navigation problem into subtasks: sensing, mapping, and planning. While this approach has proven successful at low speeds, the separation it builds upon can be problematic for high-speed navigation in cluttered environments. Indeed, the subtasks are executed sequentially, leading to increased processing latency and a compounding of errors through the pipeline. Here we propose an end-to-end approach that can autonomously fly quadrotors through complex natural and man-made environments at high speeds, with purely onboard sensing and computation. The key principle is to directly map noisy sensory observations to collision-free trajectories in a receding-horizon fashion. This direct mapping drastically reduces processing latency and increases robustness to noisy and incomplete perception. The sensorimotor mapping is performed by a convolutional network that is trained exclusively in simulation via privileged learning: imitating an expert with access to privileged information. By simulating realistic sensor noise, our approach achieves zero-shot transfer from simulation to challenging real-world environments that were never experienced during training: dense forests, snow-covered terrain, derailed trains, and collapsed buildings. Our work demonstrates that end-to-end policies trained in simulation enable high-speed autonomous flight through challenging environments, outperforming traditional obstacle avoidance pipelines. We release the code open source.
References

Learning High-Speed Flight in the Wild
Science Robotics, 2021.
E-RAFT: Dense Optical Flow from Event Cameras

We propose to incorporate feature correlation and sequential processing into dense optical flow estimation from event cameras. Modern frame-based optical flow methods heavily rely on matching costs computed from feature correlation. In contrast, there exists no optical flow method for event cameras that explicitly computes matching costs. Instead, learning-based approaches using events usually resort to the U-Net architecture to estimate optical flow sparsely. Our key finding is that introducing correlation features significantly improves results compared to previous methods that solely rely on convolution layers. Compared to the state-of-the-art, our proposed approach computes dense optical flow and reduces the end-point error by 23% on MVSEC. Furthermore, we show that all existing optical flow methods developed so far for event cameras have been evaluated on datasets with very small displacement fields with a maximum flow magnitude of 10 pixels. We introduce a new real-world dataset that exhibits displacement fields with magnitudes up to 210 pixels and 3 times higher camera resolution based on this observation. Our proposed approach reduces the end-point error on this dataset by 66%.
References

TimeLens: Event-based Video Frame Interpolation
References

TimeLens: Event-based Video Frame Interpolation
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, 2021.
NeuroBEM: Hybrid Aerodynamic Quadrotor Model
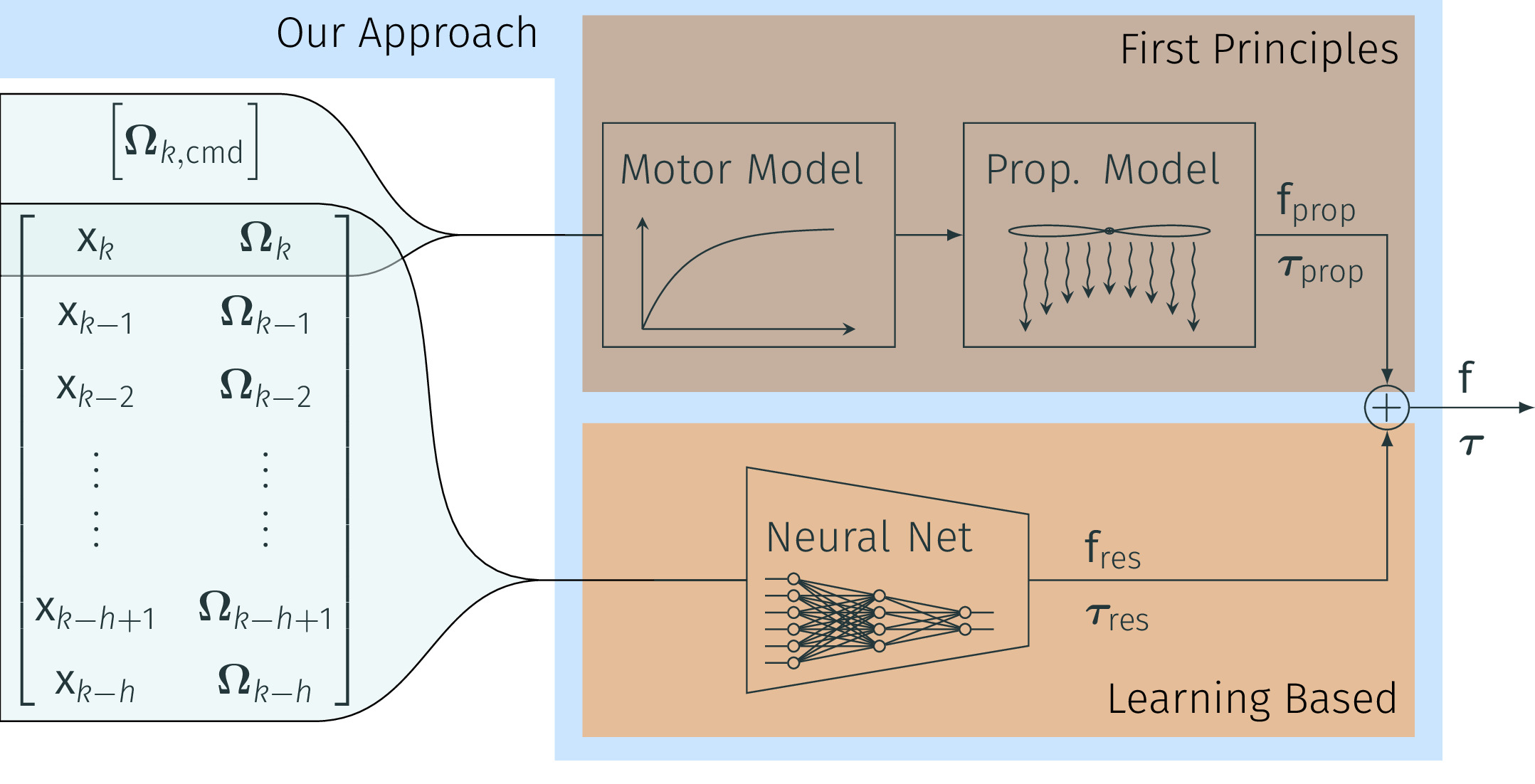
Quadrotors are extremely agile, so much in fact, that classic first-principle-models come to their limits. Aerodynamic effects, while insignificant at low speeds, become the dominant model defect during high speeds or agile maneuvers. Accurate modeling is needed to design robust high-performance control systems and enable flying close to the platform's physical limits. We propose a hybrid approach fusing first principles and learning to model quadrotors and their aerodynamic effects with unprecedented accuracy. First principles fail to capture such aerodynamic effects, rendering traditional approaches inaccurate when used for simulation or controller tuning. Data-driven approaches try to capture aerodynamic effects with blackbox modeling, such as neural networks; however, they struggle to robustly generalize to arbitrary flight conditions. Our hybrid approach unifies and outperforms both first-principles blade-element theory and learned residual dynamics. It is evaluated in one of the world's largest motion-capture systems, using autonomous-quadrotor-flight data at speeds up to 65km/h. The resulting model captures the aerodynamic thrust, torques, and parasitic effects with astonishing accuracy, outperforming existing models with 50% reduced prediction errors, and shows strong generalization capabilities beyond the training set.
References

NeuroBEM: Hybrid Aerodynamic Quadrotor Model
Robotics: Science and Systems (RSS), 2021.
Autonomous Overtaking in Gran Turismo Sport Using Curriculum Reinforcement Learning
Professional race-car drivers can execute extreme overtaking maneuvers. However, existing algorithms for autonomous overtaking either rely on simplified assumptions about the vehicle dynamics or try to solve expensive trajectory-optimization problems online. When the vehicle approaches its physical limits, existing model-based controllers struggle to handle highly nonlinear dynamics, and cannot leverage the large volume of data generated by simulation or real-world driving. To circumvent these limitations, we propose a new learning-based method to tackle the autonomous overtaking problem. We evaluate our approach in the popular car racing game Gran Turismo Sport, which is known for its detailed modeling of various cars and tracks. By leveraging curriculum learning, our approach leads to faster convergence as well as increased performance compared to vanilla reinforcement learning. As a result, the trained controller outperforms the built-in model-based game AI and achieves comparable overtaking performance with an experienced human driver.
References

DSEC: A Stereo Event Camera Dataset for Driving Scenarios

References

DSEC: A Stereo Event Camera Dataset for Driving Scenarios
IEEE Robotics and Automation Letters (RA-L), 2021.
PDF Project Page and Dataset Code Teaser ICRA 2021 Video Pitch Slides
Autonomous Drone Racing with Deep Reinforcement Learning
In many robotic tasks, such as drone racing, the goal is to travel through a set of waypoints as fast as possible. A key challenge for this task is planning the minimum-time trajectory, which is typically solved by assuming perfect knowledge of the waypoints to pass in advance. The resulting solutions are either highly specialized for a single-track layout, or suboptimal due to simplifying assumptions about the platform dynamics. In this work, a new approach to minimum-time trajectory generation for quadrotors is presented. Leveraging deep reinforcement learning and relative gate observations, this approach can adaptively compute near-time-optimal trajectories for random track layouts. Our method exhibits a significant computational advantage over approaches based on trajectory optimization for non-trivial track configurations. The proposed approach is evaluated on a set of race tracks in simulation and the real world, achieving speeds of up to 17 m/s with a physical quadrotor.
References
AutoTune: Controller Tuning for High-Speed Flight

Due to noisy actuation and external disturbances, tuning controllers for high-speed flight is very challenging. In this paper, we ask the following questions: How sensitive are controllers to tuning when tracking high-speed maneuvers? What algorithms can we use to automatically tune them? To answer the first question, we study the relationship between parameters and performance and find out that the faster the maneuver, the more sensitive a controller becomes to its parameters. To answer the second question, we review existing methods for controller tuning and discover that prior works often perform poorly on the task of high-speed flight. Therefore, we propose AutoTune, a sampling-based tuning algorithm specifically tailored to high-speed flight. In contrast to previous work, our algorithm does not assume any prior knowledge of the drone or its optimization function and can deal with the multi-modal characteristics of the parameters' optimization space. We thoroughly evaluate AutoTune both in simulation and in the physical world. In our experiments, we outperform existing tuning algorithms by up to 90\% in trajectory completion. The resulting controllers are tested in the AirSim Game of Drones competition, where we outperform the winner by up to 25\% in lap-time. Finally, we show that AutoTune improves tracking error when flying a physical platform with respect to parameters tuned by a human expert.
References
Combining Events and Frames using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction
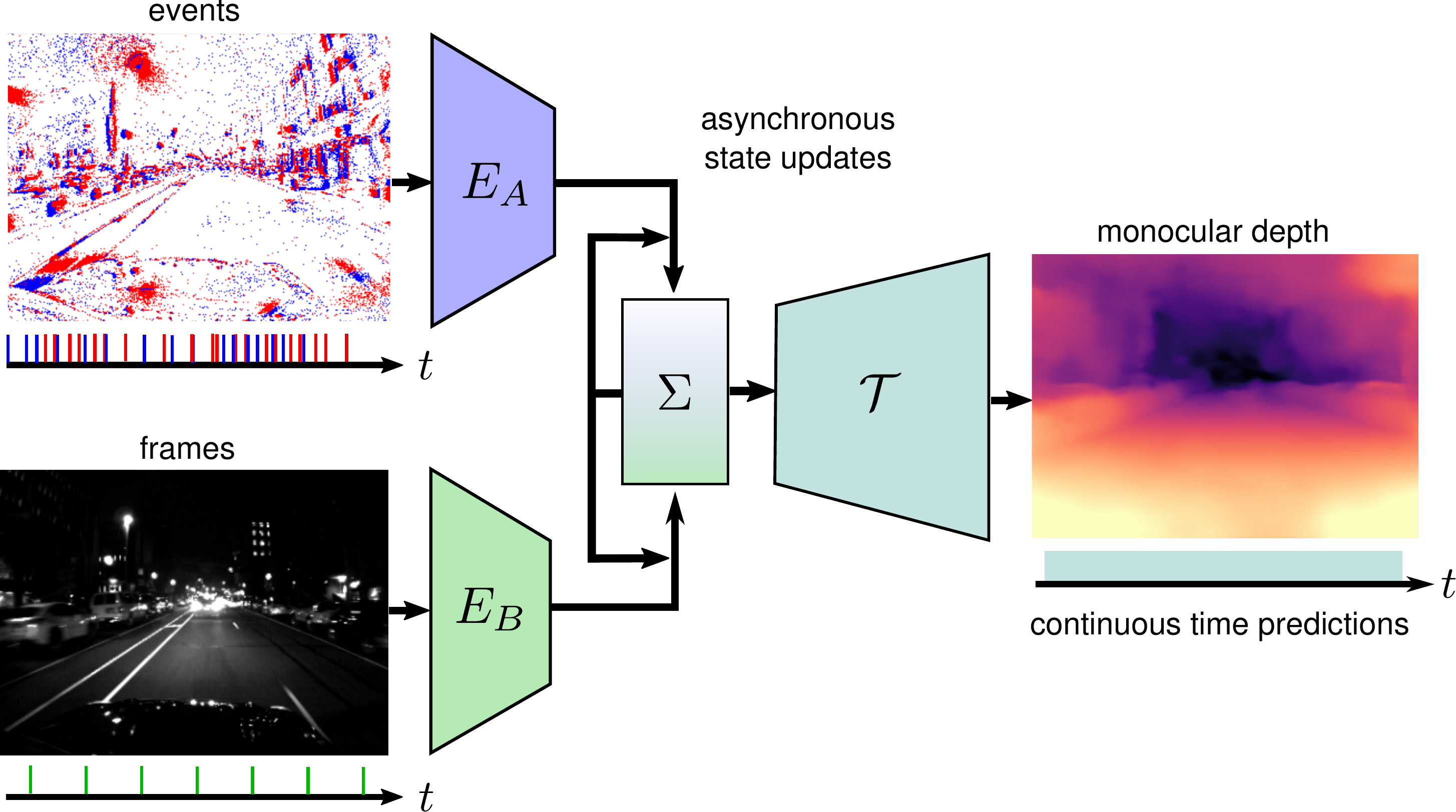
Event cameras are novel vision sensors that report per-pixel brightness changes as a stream of asynchronous "events". They offer significant advantages compared to standard cameras due to their high temporal resolution, high dynamic range and lack of motion blur. However, events only measure the varying component of the visual signal, which limits their ability to encode scene context. By contrast, standard cameras measure absolute intensity frames, which capture a much richer representation of the scene. Both sensors are thus complementary. However, due to the asynchronous nature of events, combining them with synchronous images remains challenging, especially for learning-based methods. This is because traditional recurrent neural networks (RNNs) are not designed for asynchronous and irregular data from additional sensors. To address this challenge, we introduce Recurrent Asynchronous Multimodal (RAM) networks, which generalize traditional RNNs to handle asynchronous and irregular data from multiple sensors. Inspired by traditional RNNs, RAM networks maintain a hidden state that is updated asynchronously and can be queried at any time to generate a prediction. We apply this novel architecture to monocular depth estimation with events and frames where we show an improvement over state-of-the-art methods by up to 30\% in terms of mean absolute depth error. To enable further research on multimodal learning with events, we release EventScape, a new dataset with events, intensity frames, semantic labels, and depth maps recorded in the CARLA simulator.
References
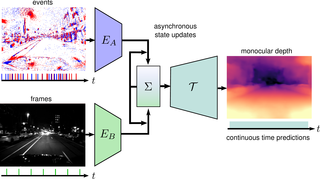
Combining Events and Frames using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction
IEEE Robotics and Automation Letters (RA-L), 2021.
Primal-Dual Mesh Convolutional Neural Networks
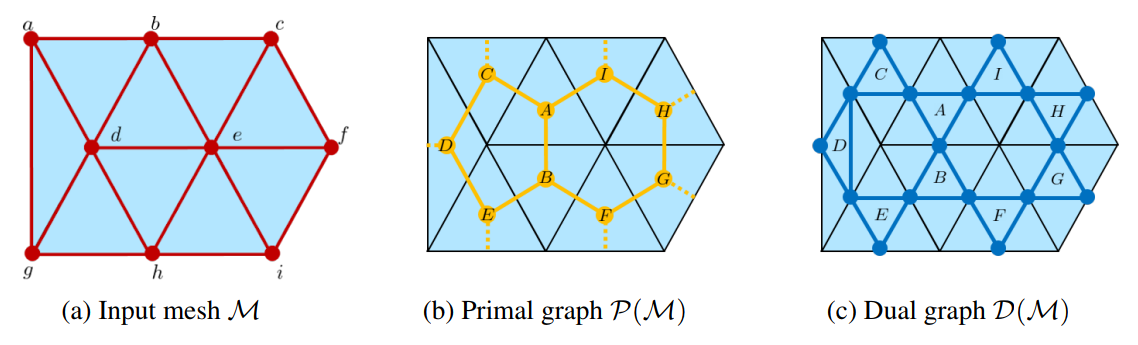
Recent works in geometric deep learning have introduced neural networks that allow performing inference tasks on three-dimensional geometric data by defining convolution, and sometimes pooling, operations on triangle meshes. These methods, however, either consider the input mesh as a graph, and do not exploit specific geometric properties of meshes for feature aggregation and downsampling, or are specialized for meshes, but rely on a rigid definition of convolution that does not properly capture the local topology of the mesh. We propose a method that combines the advantages of both types of approaches, while addressing their limitations: we extend a primal-dual framework drawn from the graph-neural-network literature to triangle meshes, and define convolutions on two types of graphs constructed from an input mesh. Our method takes features for both edges and faces of a 3D mesh as input and dynamically aggregates them using an attention mechanism. At the same time, we introduce a pooling operation with a precise geometric interpretation, that allows handling variations in the mesh connectivity by clustering mesh faces in a task-driven fashion. We provide theoretical insights of our approach using tools from the mesh-simplification literature. In addition, we validate experimentally our method in the tasks of shape classification and shape segmentation, where we obtain comparable or superior performance to the state of the art.
References
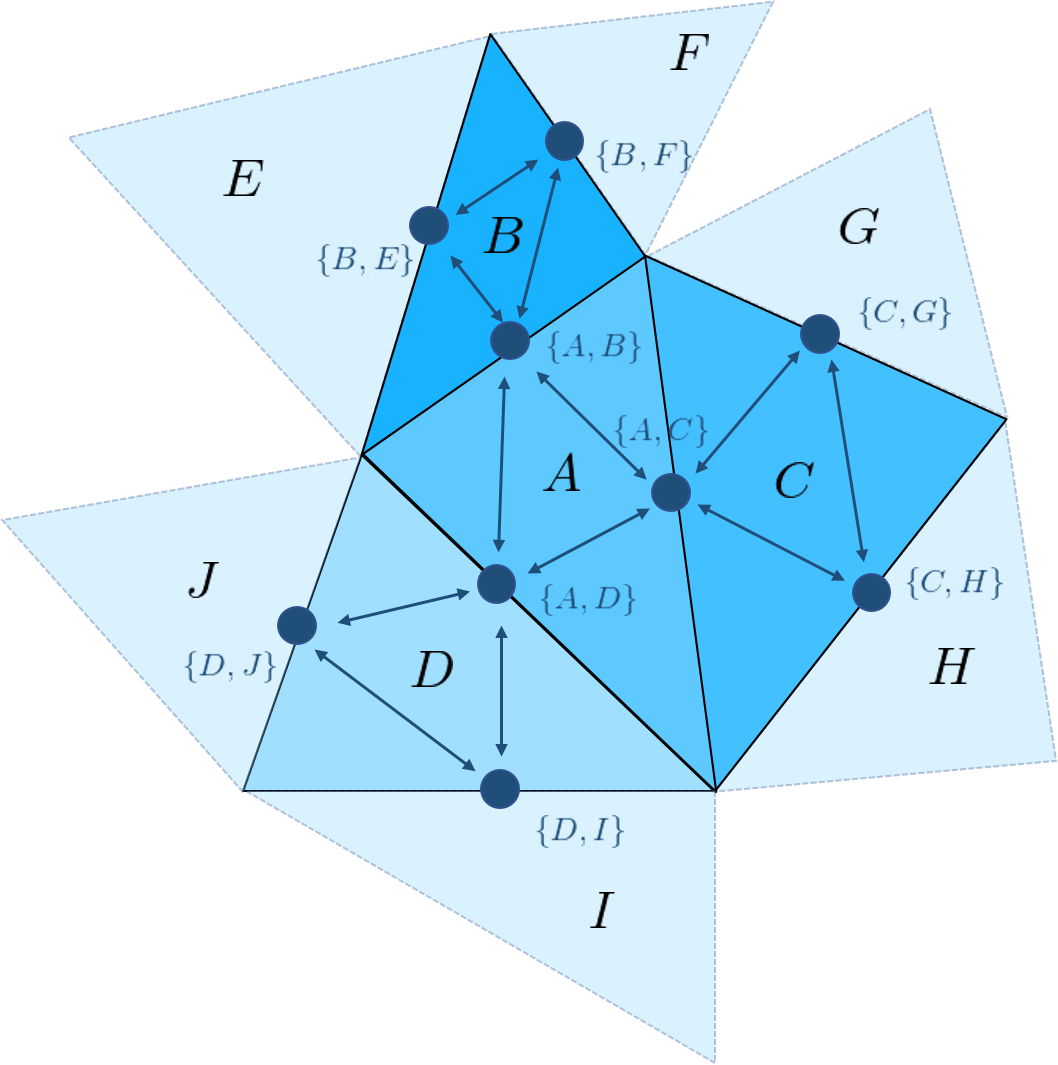
Learning Monocular Dense Depth from Events
Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. Compared to conventional image sensors, they offer significant advantages: high temporal resolution, high dynamic range, no motion blur, and much lower bandwidth. Recently, learning-based approaches have been applied to event-based data, thus unlocking their potential and making significant progress in a variety of tasks, such as monocular depth prediction. Most existing approaches use standard feed-forward architectures to generate network predictions, which do not leverage the temporal consistency presents in the event stream. We propose a recurrent architecture to solve this task and show significant improvement over standard feed-forward methods. In particular, our method generates dense depth predictions using a monocular setup, which has not been shown previously. We pretrain our model using a new dataset containing events and depth maps recorded in the CARLA simulator. We test our method on the Multi Vehicle Stereo Event Camera Dataset (MVSEC). Quantitative experiments show up to 50% improvement in average depth error with respect to previous event-based methods.
References

Learning Monocular Dense Depth from Events
IEEE International Conference on 3D Vision (3DV), 2020.
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
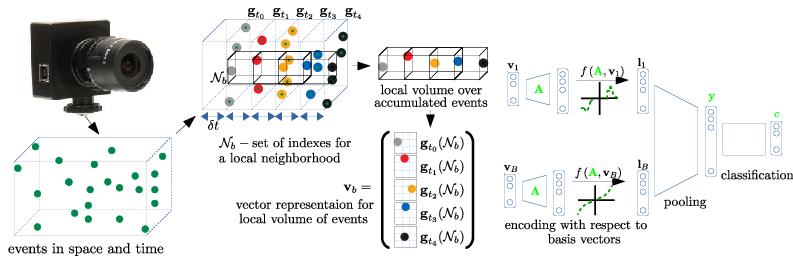
Event-based cameras record an asynchronous stream of per-pixel brightness changes. As such, they have numerous advantages over the standard frame-based cameras,including high temporal resolution, high dynamic range, and no motion blur. Due to the asynchronous nature, efficient learning of compact representation for event data is challenging. While it remains not explored the extent to which the spatial and temporal event "information" is useful for pattern recognition tasks. Inthis paper, we focus on single-layer architectures. We analyze the performance of two general problem formulations: the directand the inverse, for unsupervised feature learning from local event data (local volumes of events described in space-time).We identify and show the main advantages of each approach.Theoretically, we analyze guarantees for an optimal solution,possibility for asynchronous, parallel parameter update, and the computational complexity. We present numerical experiments for object recognition. We evaluate the solution under the direct and the inverse problem and give a comparison with the state-of-the-art methods. Our empirical results highlight the advantages of both approaches for representation learning from event data. Weshow improvements of up to 9%in the recognition accuracy compared to the state-of-the-art methods from the same class of methods.
References
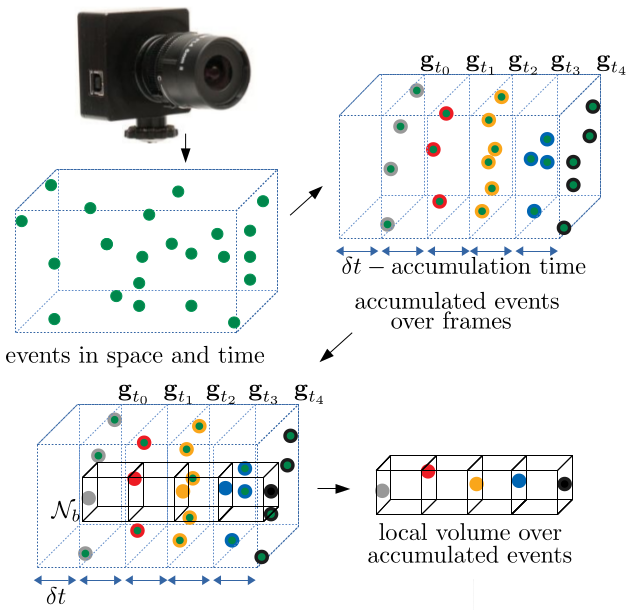
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
IAPR IEEE/Computer Society International Conference on Pattern Recognition (ICPR), Milan, 2021.
Flightmare: A Flexible Quadrotor Simulator
Currently available quadrotor simulators have a rigid and highly-specialized structure: either are they really fast, physically accurate, or photo-realistic. In this work, we propose a paradigm-shift in the development of simulators: moving the trade-off between accuracy and speed from the developers to the end-users. We release a new modular quadrotor simulator: Flightmare. Flightmare is composed of two main components: a configurable rendering engine built on Unity and a flexible physics engine for dynamics simulation. Those two components are totally decoupled and can run independently from each other. Flightmare comes with several desirable features: (i) a large multi-modal sensor suite, including an interface to extract the 3D point-cloud of the scene; (ii) an API for reinforcement learning which can simulate hundreds of quadrotors in parallel; and (iii) an integration with a virtual-reality headset for interaction with the simulated environment. Flightmare can be used for various applications, including path-planning, reinforcement learning, visual-inertial odometry, deep learning, human-robot interaction, etc.
References

Flightmare: A Flexible Quadrotor Simulator
Conference on Robot Learning (CoRL), 2020
Super-Human Performance in Gran Turismo Sport Using Deep Reinforcement Learning
Autonomous car racing raises fundamental robotics challenges such as planning minimum-time trajectories under uncertain dynamics and controlling the car at its friction limits. In this project, we consider the task of autonomous car racing in the top-selling car racing game Gran Turismo Sport. Gran Turismo Sport is known for its detailed physics simulation of various cars and tracks. Our approach makes use of maximum-entropy deep reinforcement learning and a new reward design to train a sensorimotor policy to complete a given race track as fast as possible. We evaluate our approach in three different time trial settings with different cars and tracks. Our results show that the obtained controllers not only beat the built-in non-player character of Gran Turismo Sport, but also outperform the fastest known times in a dataset of personal best lap times of over 50,000 human drivers.
References

Learning High-Level Policies for Model Predictive Control
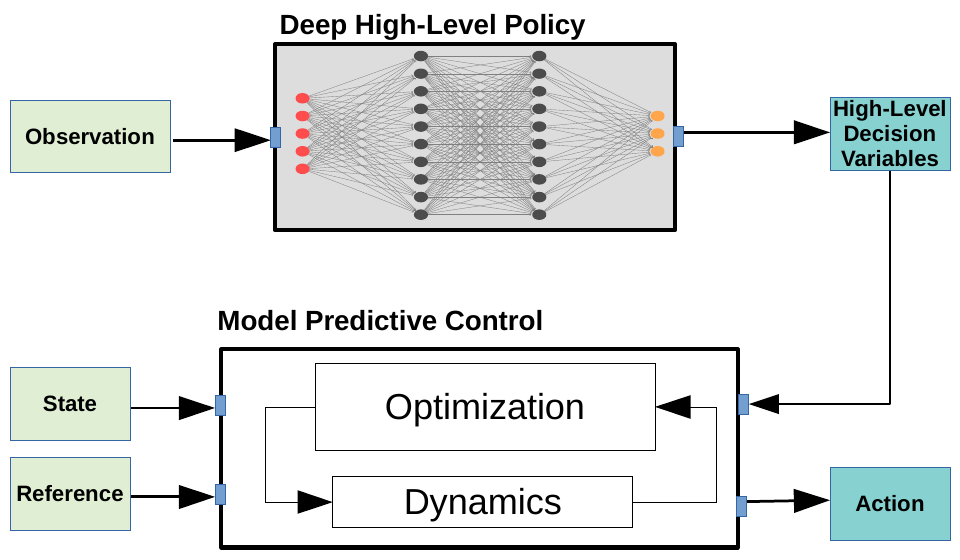
The combination of policy search and deep neural networks holds the promise of automating a variety of decision- making tasks. Model Predictive Control (MPC) provides robust solutions to robot control tasks by making use of a dynamical model of the system and solving an optimization problem online over a short planning horizon. In this work, we leverage probabilistic decision-making approaches and the generalization capability of artificial neural networks to the powerful online optimization by learning a deep high-level policy for the MPC (High-MPC). Conditioning on robot’s local observations, the trained neural network policy is capable of adaptively selecting high-level decision variables for the low-level MPC controller, which then generates optimal control commands for the robot. First, we formulate the search of high-level decision variables for MPC as a policy search problem, specifically, a probabilistic inference problem. The problem can be solved in a closed-form solution. Second, we propose a self-supervised learning algorithm for learning a neural network high-level policy, which is useful for online hyperparameter adaptations in highly dynamic environments. We demonstrate the importance of incorporating the online adaption into autonomous robots by using the proposed method to solve a challenging control problem, where the task is to control a simulated quadrotor to fly through a swinging gate. We show that our approach can handle situations that are difficult for standard MPC.
References
Event-based Asynchronous Sparse Convolutional Networks
Event cameras are bio-inspired sensors that respond to per-pixel brightness changes in the form of asynchronous and sparse "events". Recently, pattern recognition algorithms, such as learning-based methods, have made significant progress with event cameras by converting events into synchronous dense, image-like representations and applying traditional machine learning methods developed for standard cameras. However, these approaches discard the spatial and temporal sparsity inherent in event data at the cost of higher computational complexity and latency. In this work, we present a general framework for converting models trained on synchronous image-like event representations into asynchronous models with identical output, thus directly leveraging the intrinsic asynchronous and sparse nature of the event data. We show both theoretically and experimentally that this drastically reduces the computational complexity and latency of high-capacity, synchronous neural networks without sacrificing accuracy. In addition, our framework has several desirable characteristics: (i) it exploits spatio-temporal sparsity of events explicitly, (ii) it is agnostic to the event representation, network architecture, and task, and (iii) it does not require any train-time change, since it is compatible with the standard neural networks' training process. We thoroughly validate the proposed framework on two computer vision tasks: object detection and object recognition. In these tasks, we reduce the computational complexity up to 20 times with respect to high-latency neural networks. At the same time, we outperform state-of-the-art asynchronous approaches up to 24% in prediction accuracy.
References

Event-based Asynchronous Sparse Convolutional Networks
European Conference on Computer Vision (ECCV), Glasgow, 2020.
Learning Depth with Very Sparse Supervision

Motivated by the astonishing capabilities of natural intelligent agents and inspired by theories from psychology, this paper explores the idea that perception gets coupled to 3D properties of the world via interaction with the environment. Existing works for depth estimation require either massive amounts of annotated training data or some form of hard-coded geometrical constraint. This paper explores a new approach to learning depth perception requiring neither of those. Specifically, we train a specialized global-local network architecture with what would be available to a robot interacting with the environment: from extremely sparse depth measurements down to even a single pixel per image. From a pair of consecutive images, our proposed network outputs a latent representation of the observer’s motion between the images and a dense depth map.
Experiments on several datasets show that, when ground truth is available even for just one of the image pixels, the proposed network can learn monocular dense depth estimation up to 22.5% more accurately than state-of-the-art approaches. We believe that this work, despite its scientific interest, lays the foundations to learn depth from extremely sparse supervision, which can be valuable to all robotic systems acting under severe bandwidth or sensing constraints.
References
Deep Drone Acrobatics
Performing acrobatic maneuvers with quadrotors is extremely challenging. Acrobatic flight requires high thrust and extreme angular accelerations that push the platform to its physical limits. Professional drone pilots often measure their level of mastery by flying such maneuvers in competitions. In this paper, we propose to learn a sensorimotor policy that enables an autonomous quadrotor to fly extreme acrobatic maneuvers with only onboard sensing and computation. We train the policy entirely in simulation by leveraging demonstrations from an optimal controller that has access to privileged information. We use appropriate abstractions of the visual input to enable transfer to a real quadrotor. We show that the resulting policy can be directly deployed in the physical world without any fine-tuning on real data. Our methodology has several favorable properties: it does not require a human expert to provide demonstrations, it cannot harm the physical system during training, and it can be used to learn maneuvers that are challenging even for the best human pilots. Our approach enables a physical quadrotor to fly maneuvers such as the Power Loop, the Barrel Roll, and the Matty Flip, during which it incurs accelerations of up to 3g.
References

Deep Drone Acrobatics
Robotics: Science and Systems (RSS), 2020.
Reference Pose Generation for Visual Localization via Learned Features and View Synthesis
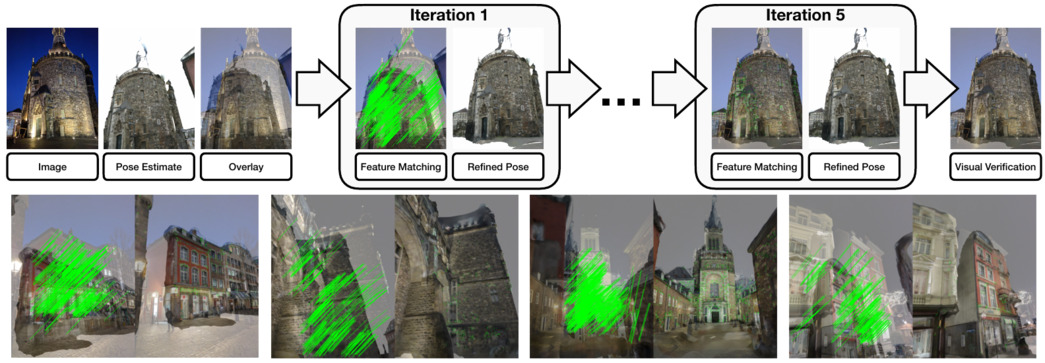
Visual Localization is one of the key enabling technologies for autonomous driving and augmented reality. High quality datasets with accurate 6 Degree-of-Freedom (DoF) reference poses are the foundation for benchmarking and improving existing methods. Traditionally, reference poses have been obtained via Structure-from-Motion (SfM). However, SfM itself relies on local features which are prone to fail when images were taken under different conditions, e.g., day/night changes. At the same time, manually annotating feature correspondences is not scalable and potentially inaccurate. In this work, we propose a semi-automated approach to generate reference poses based on feature matching between renderings of a 3D model and real images via learned features. Given an initial pose estimate, our approach iteratively refines the pose based on feature matches against a rendering of the model from the current pose estimate. We significantly improve the nighttime reference poses of the popular Aachen Day-Night dataset, showing that state-of-the-art visual localization methods perform better (up to 47%) than predicted by the original reference poses. We extend the dataset with new nighttime test images, provide uncertainty estimates for our new reference poses, and introduce a new evaluation criterion. We will make our reference poses and our framework publicly available upon publication.
References

Reference Pose Generation for Long-term Visual Localization via Learned Features
and View Synthesis
International Journal of Computer Vision (IJCV), 2020.
Event-Based Angular Velocity Regression with Spiking Networks
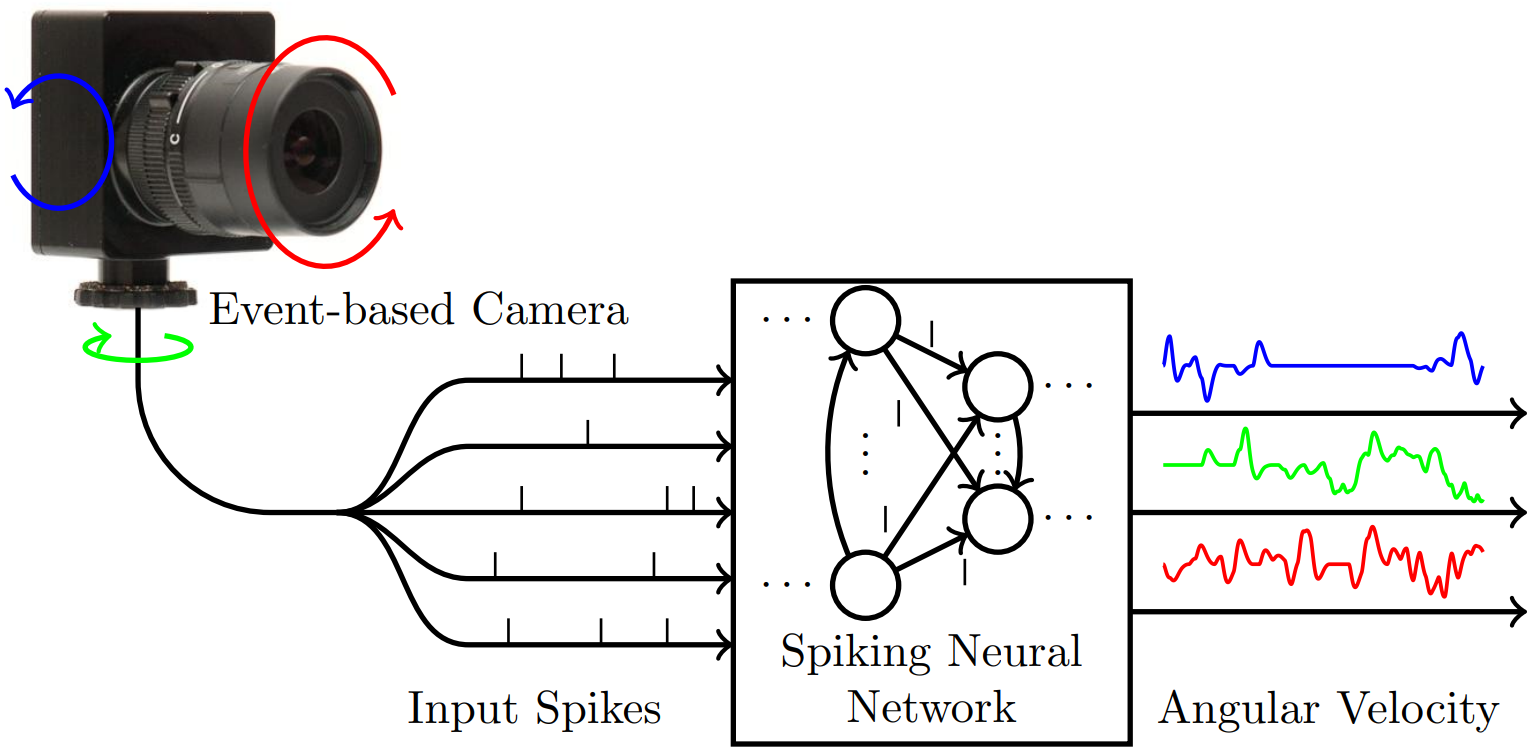
Spiking Neural Networks (SNNs) are bio-inspired networks that process information conveyed as temporal spikes rather than numeric values. An example of a sensor providing such data is the event camera. It only produces an event when a pixel reports a significant brightness change. Similarly, the spiking neuron of an SNN only produces a spike whenever a significant number of spikes occur within a short period of time. Due to their spike-based computational model, SNNs can process output from event-based, asynchronous sensors without any pre-processing at extremely lower power unlike standard artificial neural networks. This is possible due to specialized neuromorphic hardware that implements the highly-parallelizable concept of SNNs in silicon. Yet, SNNs have not enjoyed the same rise of popularity as artificial neural networks. This not only stems from the fact that their input format is rather unconventional but also due to the challenges in training spiking networks. Despite their temporal nature and recent algorithmic advances, they have been mostly evaluated on classification problems. We propose, for the first time, a temporal regression problem of numerical values given events from an event camera.
We specifically investigate the prediction of the 3-DOF angular velocity of a rotating event camera with an SNN. The difficulty of this problem arises from the prediction of angular velocities continuously in time directly from irregular, asynchronous event-based input. Directly utilising the output of event cameras without any pre-processing ensures that we inherit all the benefits that they provide over conventional cameras. That is high-temporal resolution, high-dynamic range and no motion blur. To assess the performance of SNNs on this task, we introduce a synthetic event camera dataset generated from real-world panoramic images and show that we can successfully train an SNN to perform angular velocity regression.
References
Augmenting Visual Place Recognition with Structural Cues
In this work, we propose to augment image-based place recognition with structural cues. Specifically, these structural cues are obtained using structure-from-motion, such that no additional sensors are needed for place recognition. This is achieved by augmenting the 2D convolutional neural network (CNN) typically used for image-based place recognition with a 3D CNN that takes as input a voxel grid derived from the structure-from-motion point cloud. We evaluate different methods for fusing the 2D and 3D features and obtain best performance with global average pooling and simple concatenation. The resulting descriptor exhibits superior recognition performance compared to descriptors extracted from only one of the input modalities, including state-of-the-art image-based descriptors. Especially at low descriptor dimensionalities, we outperform state-of-the-art descriptors by up to 90%.
References

A General Framework for Uncertainty Estimation in Deep Learning
Neural networks predictions are unreliable when the input sample is out of the training data distribution or corrupted by noise. Being able to detect such failures automatically is fundamental to integrate deep learning algorithms into robotic systems. Current approaches for uncertainty estimation of neural networks require changes to the network and optimization process, typically ignore prior knowledge about the data, and tend to make over-simplifying assumptions which underestimate uncertainty. To address these limitations, we propose a novel framework for uncertainty estimation. Based on Bayesian belief networks and Monte-Carlo sampling, our framework not only fully models the different sources of prediction uncertainty, but also incorporates prior data information, e.g. sensor noise. We show theoretically that this gives us the ability to capture uncertainty better than existing methods. In addition, our framework has several desirable properties: (i) it is agnostic to the network architecture and task; (ii) it does not require changes in the optimization process; (iii) it can be applied to already trained architectures. We thoroughly validate the proposed framework through extensive experiments on both computer vision and control tasks, where we outperform previous methods by up to 23%.
References

A General Framework for Uncertainty Estimation in Deep Learning
Robotics And Automation Letters, 2020.
Video to Events: Recycling Video Dataset for Event Cameras
Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. They offer significant advantages with respect to conventional cameras: high dynamic range (HDR), high temporal resolution, and no motion blur. Recently, novel learning approaches operating on event data have achieved impressive results. Yet, these methods require a large amount of event data for training, which is hardly available due the novelty of event sensors in computer vision research. In this paper, we present a method that addresses these needs by converting any existing video dataset recorded with conventional cameras to \emph{synthetic} event data. This unlocks the use of a virtually unlimited number of existing video datasets for training networks designed for real event data. We evaluate our method on two relevant vision tasks, i.e., object recognition and semantic segmentation, and show that models trained on synthetic events have several benefits: (i) they generalize well to real event data, even in scenarios where standard-camera images are blurry or overexposed, by inheriting the outstanding properties of event cameras; (ii) they can be used for fine-tuning on real data to improve over state-of-the-art for both classification and semantic segmentation.
References

Video to Events: Recycling Video Dataset for Event Cameras
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2020.
Deep Drone Racing: From Simulation to Reality with Domain Randomization
Dynamically changing environments, unreliable state estimation, and operation under severe resource constraints are fundamental challenges for robotics, which still limit the deployment of small autonomous drones. We address these challenges in the context of autonomous, vision-based drone racing in dynamic environments. A racing drone must traverse a track with possibly moving gates at high speed. We enable this functionality by combining the performance of a state-of-the-art path-planning and control system with the perceptual awareness of a convolutional neural network (CNN). The CNN directly maps raw images to a desired waypoint and speed. Given the CNN output, the planner generates a short minimum-jerk trajectory segment that is tracked by a model-based controller to actuate the drone towards the waypoint. The resulting modular system has several desirable features: (i) it can run fully on-board, (ii) it does not require globally consistent state estimation, and (iii) it is both platform and domain independent. We extensively test the precision and robustness of our system, both in simulation and on a physical platform. In both domains, our method significantly outperforms the prior state of the art. In order to understand the limits of our approach, we additionally compare against professional human drone pilots with different skill levels.
References

Smart Interest Points
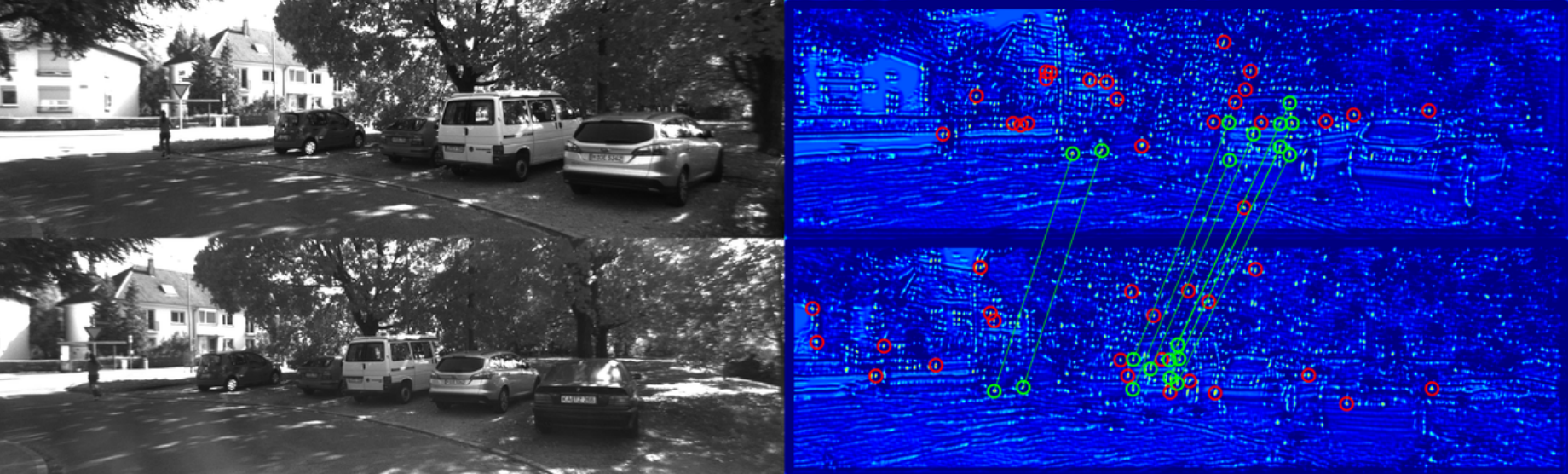
Detecting interest points is a key component of vision-based estimation algorithms, such as visual odometry or visual SLAM. In the context of distributed visual SLAM, we have encountered the need to minimize the amount of data that is sent between robots, which, for relative pose estimation, translates into the need to find a minimum set of interest points that is sufficiently reliably detected between viewpoints to ensure relative pose estimation. We have decided to solve this problem at a fundamental level, that is, at the point detector, using machine learning.
In SIPS, we introduce the succinctness metric, which allows to quantify performance of interest point detectors with respect to this goal. At the same time, we propose an unsupervised training method for CNN interest point detectors which requires no labels - only uncalibrated image sequences. The proposed method is able to establish relative poses with a minimum of extracted interest points. However, descriptors still need to be extracted and transmitted to establish these poses.
This problem is addressed in IMIPs, where we propose the first feature matching pipeline that works by implicit matching, without the need of descriptors. In IMIPs, the detector CNN has multiple output channels, and each channel generates a single interest point. Between viewpoints, interest points obtained from the same channel are considered implicitly matched. This allows matching points with as little as 3 bytes per point - the point coordinates in an up to 4096 x 4096 image.
References

Matching Features without Descriptors:
Implicitly Matched Interest
Points
British Machine Vision Conference (BMVC), Cardiff, 2019.

SIPs: Succinct Interest Points from Unsupervised Inlierness Probability Learning
IEEE International Conference on 3D Vision (3DV), 2019.
High Speed and High Dynamic Range Video with an Event Camera
Event cameras are novel sensors that report brightness changes in the form of a stream of asynchronous events instead of intensity frames. They offer significant advantages with respect to conventional cameras: high temporal resolution, high dynamic range, and no motion blur. While the stream of events encodes in principle the complete visual signal, the reconstruction of an intensity image from a stream of events is an ill-posed problem in practice. Existing reconstruction approaches are based on hand-crafted priors and strong assumptions about the imaging process as well as the statistics of natural images.
In this work we propose to learn to reconstruct intensity images from event streams directly from data instead of relying on any hand-crafted priors. We propose a novel recurrent network to reconstruct videos from a stream of events, and train it on a large amount of simulated event data. During training we propose to use a perceptual loss to encourage reconstructions to follow natural image statistics. We further extend our approach to synthesize color images from color event streams.
Our quantitative experiments show that our network surpasses state-of-the-art reconstruction methods by a large margin in terms of image quality (> 20%), while comfortably running in real-time. We show that the network is able to synthesize high framerate videos (> 5,000 frames per second) of high-speed phenomena (e.g. a bullet hitting an object) and is able to provide high dynamic range reconstructions in challenging lighting conditions. As an additional contribution, we demonstrate the effectiveness of our reconstructions as an intermediate representation for event data. We show that off-the-shelf computer vision algorithms can be applied to our reconstructions for tasks such as object classification and visual-inertial odometry and that this strategy consistently outperforms algorithms that were specifically designed for event data. We release the reconstruction code and a pre-trained model to enable further research.
We presented our approach in two different papers (references below). Our first paper (CVPR19) introduced the network architecture (a simple recurrent neural network), the training data, and our first video reconstruction results. In our follow-up paper (T-PAMI), we improved the network architecture by using convolutional LSTM blocks and a temporal consistency loss, leading to improved stability and temporal consistency. Furthermore, the improved network now works well with windows containing variable number of events, which allows to synthesize videos at a very high framerate (> 5,000 frames per second), which we additionally demonstrated in a series of new experiments featuring extremely fast motions.
References

High Speed and High Dynamic Range Video with an Event Camera
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 2020.

Fast Image Reconstruction with an Event Camera
IEEE Winter Conference on Applications of Computer Vision (WACV), 2020.
A 64mW DNN-based Visual Navigation Engine for Autonomous Nano-Drones
PULP-DroNet is a deep learning-powered visual navigation engine that enables autonomous navigation of a pocket-size quadrotor in a previously unseen environment. Thanks to PULP-DroNet the nano-drone can explore the environment, avoiding collisions also with dynamic obstacles, in complete autonomy -- no human operator, no ad-hoc external signals, and no remote laptop! This means that all the complex computations are done directly aboard the vehicle and very fast. The visual navigation engine is composed of both a software and a hardware part. The former is based on the previous DroNet project developed by the RPG from the University of Zürich (UZH). DroNet is a shallow convolutional neural network (CNN) which has been used to control a standard-size quadrotor in a set of environments via remote computation. The hardware soul of PULP-DroNet is embodied by the PULP-Shield an ultra-low power visual navigation module featuring a Parallel Ultra-Low-Power (PULP) GAP8 System-on-Chip (SoC) from GreenWaves Technologies (GWT), an ultra-low power camera, and off-chip Flash/DRAM memory; the shield is designed as a pluggable PCB for the Crazyflie 2.0 nano-drone. Then, we developed a general methodology for deploying state-of-the-art deep learning algorithms on top of ultra-low power embedded computation nodes, like a miniaturized drone. Our novel methodology allowed us first to deploy DroNet on the PULP-Shield, and then demonstrating how it enables the execution the CNN on board the CrazyFlie 2.0 within only 64-284mW and with a throughput of 6-18 frame-per-second! Finally, we field-prove our methodology presenting a closed-loop fully working demonstration of vision-driven autonomous navigation relying only on onboard resources, and within an ultra-low power budget. See the videos on the PULP Platform Youtube channel (Video1). We release here, as open source, all our code, hardware designs, datasets, and trained networks.
References

End-to-End Learning of Representations for Asynchronous Event-Based Data
Event cameras are vision sensors that record asynchronous streams of per-pixel brightness changes, referred to as "events". They have appealing advantages over frame-based cameras for computer vision, including high temporal resolution, high dynamic range, and no motion blur. Due to the sparse, non-uniform spatiotemporal layout of the event signal, pattern recognition algorithms typically aggregate events into a grid-based representation and subsequently process it by a standard vision pipeline, e.g., Convolutional Neural Network (CNN). In this work, we introduce a general framework to convert event streams into grid-based representations through a sequence of differentiable operations. Our framework comes with two main advantages: (i) allows learning the input event representation together with the task dedicated network in an end to end manner, and (ii) lays out a taxonomy that unifies the majority of extant event representations in the literature and identifies novel ones. Empirically, we show that our approach to learning the event representation end-to-end yields an improvement of approximately 12% on optical flow estimation and object recognition over state-of-the-art methods.
References
Events-to-Video: Bringing Modern Computer Vision to Event Cameras
Event cameras are novel sensors that report brightness changes in the form of asynchronous “events” instead of intensity frames. They have significant advantages over conventional cameras: high temporal resolution, high dynamic range, and no motion blur. Since the output of event cameras is fundamentally different from conventional cameras, it is commonly accepted that they require the development of specialized algorithms to accommodate the particular nature of events. In this work, we take a different view and propose to apply existing, mature computer vision techniques to videos reconstructed from event data. We propose a novel recurrent network to reconstruct videos from a stream of events, and train it on a large amount of simulated event data. Our experiments show that our approach surpasses state-of-the-art reconstruction methods by a large margin (20%) in terms of image quality. We further apply off-the-shelf computer vision algorithms to videos reconstructed from event data on tasks such as object classification and visual-inertial odometry, and show that this strategy consistently outperforms algorithms that were specifically designed for event data. We believe that our approach opens the door to bringing the outstanding properties of event cameras to an entirely new range of tasks.
References
Unsupervised Moving Object Detection via Contextual Information Separation

We propose an adversarial contextual model for detecting moving objects in images. A deep neural network is trained to predict the optical flow in a region using information from everywhere else but that region (context), while another network attempts to make such context as uninformative as possible. The result is a model where hypotheses naturally compete with no need for explicit regularization or hyper-parameter tuning. Although our method requires no supervision whatsoever, it outperforms several methods that are pre-trained on large annotated datasets. Our model can be thought of as a generalization of classical variational generative region-based segmentation, but in a way that avoids explicit regularization or solution of partial differential equations at run-time. We publicly release all our code and trained networks.
References

Unsupervised Moving Object Detection via Contextual Information Separation
IEEE International Conference on Pattern Recognition (CVPR), 2019.
PDF YouTube Project PageBeauty and the Beast: Optimal Methods Meet Learning for Drone Racing
Autonomous micro aerial vehicles still struggle with fast and agile maneuvers, dynamic environments, imperfect sensing, and state estimation drift. Autonomous drone racing brings these challenges to the fore. Human pilots can fly a previously unseen track after a handful of practice runs. In contrast, state-of-the-art autonomous navigation algorithms require either a precise metric map of the environment or a large amount of training data collected in the track of interest. To bridge this gap, we propose an approach that can fly a new track in a previously unseen environment without a precise map or expensive data collection. Our approach represents the global track layout with coarse gate locations, which can be easily estimated from a single demonstration flight. At test time, a convolutional network predicts the poses of the closest gates along with their uncertainty. These predictions are incorporated by an extended Kalman filter to maintain optimal maximum-a-posteriori estimates of gate locations. This allows the framework to cope with misleading high-variance estimates that could stem from poor observability or lack of visible gates. Given the estimated gate poses, we use model predictive control to quickly and accurately navigate through the track. We conduct extensive experiments in the physical world, demonstrating agile and robust flight through complex and diverse previously-unseen race tracks. The presented approach was used to win the IROS 2018 Autonomous Drone Race Competition, outracing the second-placing team by a factor of two.
References

Deep Drone Racing: Learning Agile Flight in Dynamic Environments
Autonomous agile flight brings up fundamental challenges in robotics, such as coping with unreliable state estimation, reacting optimally to dynamically changing environments, and coupling perception and action in real time under severe resource constraints. In this paper, we consider these challenges in the context of autonomous, vision-based drone racing in dynamic environments. Our approach combines a convolutional neural network (CNN) with a state-of-the-art path-planning and control system. The CNN directly maps raw images into a robust representation in the form of a waypoint and desired speed. This information is then used by the planner to generate a short, minimum-jerk trajectory segment and corresponding motor commands to reach the desired goal. We demonstrate our method in autonomous agile flight scenarios, in which a vision-based quadrotor traverses drone-racing tracks with possibly moving gates. Our method does not require any explicit map of the environment and runs fully onboard. We extensively test the precision and robustness of the approach in simulation and in the physical world. We also evaluate our method against state-of-the-art navigation approaches and professional human drone pilots.
References

DroNet: Learning to Fly by Driving
References

DroNet: Learning to Fly by Driving
IEEE Robotics and Automation Letters (RA-L), 2018.
PDF YouTube Software and DatasetsPlace Recognition in Semi-Dense Maps: Geometric and Learning-Based Approaches

For robotics and augmented reality systems operating in large and dynamic environments, place recognition and tracking using vision represent very challenging tasks. Additionally, when these systems need to reliably operate for very long time periods, such as months or years, further challenges are introduced by severe environmental changes, that can significantly alter the visual appearance of a scene. Thus, to unlock long term, large scale visual place recognition, it is necessary to develop new methodologies for improving localization under difficult conditions. As shown in previous work, gains in robustness can be achieved by exploiting the 3D structural information of a scene. The latter, extracted from image sequences, carries in fact more discriminative clues than individual images only. In this paper, we propose to represent a scene's structure with semi-dense point clouds, due to their highly informative power, and the simplicity of their generation through mature visual odometry and SLAM systems. Then we cast place recognition as an instance of pose retrieval and evaluate several techniques, including recent learning based approaches, to produce discriminative descriptors of semi-dense point clouds. Our proposed methodology, evaluated on the recently published and challenging Oxford Robotcar Dataset, shows to outperform image-based place recognition, with improvements up to 30% in precision across strong appearance changes. To the best of our knowledge, we are the first to propose place recognition in semi-dense maps.
References

Learning-based Image Enhancement for Visual Odometry in Challenging HDR Environments
One of the main open challenges in visual odometry (VO) is the robustness to difficult illumination conditions or high dynamic range (HDR) environments. The main difficulties in these situations come from both the limitations of the sensors and the inability to perform a successful tracking of interest points because of the bold assumptions in VO, such as brightness constancy. We address this problem from a deep learning perspective, for which we first fine-tune a Deep Neural Network (DNN) with the purpose of obtaining enhanced representations of the sequences for VO. Then, we demonstrate how the insertion of Long Short Term Memory (LSTM) allows us to obtain temporally consistent sequences, as the estimation depends on previous states. However, the use of very deep networks does not allow the insertion into a real-time VO framework; therefore, we also propose a Convolutional Neural Network (CNN) of reduced size capable of performing faster. Finally, we validate the enhanced representations by evaluating the sequences produced by the two architectures in several state-of-art VO algorithms, such as ORB-SLAM and DSO.
References

Learning-based Image Enhancement for Visual Odometry in Challenging HDR Environments
IEEE International Conference on Robotics and Automation (ICRA), 2018.
Towards Domain Independence for Learning-Based Monocular Depth Estimation
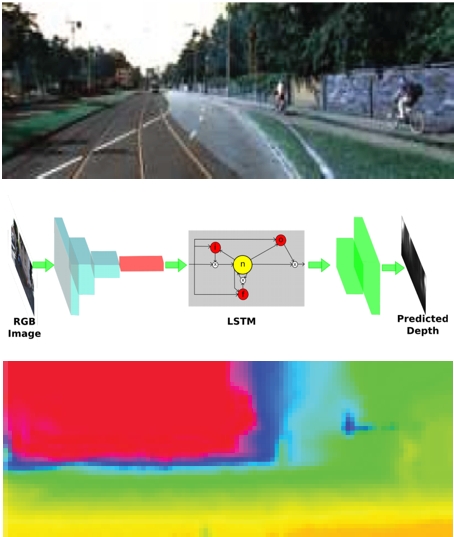
Most state-of-the-art learning-based monocular depth depth estimators do not consider generalization and only benchmark their performance on publicly available datasets "only after specific fine tuning". Generalization can be achieved by training on several heterogeneous datasets but their collection and labeling is costly. In this work, we propose two Deep Neural Networks (one based on CNN and one on LSTM) for monocular depth estimation, which we train on heterogeneous synthetic datasets (forest and urban scenarios), generated using Unreal Engine, and show that, although trained only on synthetic data, the network is able to generalize well across different, unseen real-world scenarios (KITTI and new collected datasets from Zurich, Switzerland, and Perugia, Italy) without any fine-tuning, achieving comparable performance to state-of-the-art methods. Additionally, we also show that the LSTM network is able to estimate well the absolute scale with low additional computational overhead. We release the Unreal Engine 3D models and all the collected datasets (from Switzerland and Italy) freely to the public.
References
Towards Domain Independence for Learning-Based Monocular Depth Estimation
IEEE Robotics and Automation Letters (RA-L), 2017.
A Deep Learning Approach for Automatic Recognition and Following of Forest Trails with Drones
References
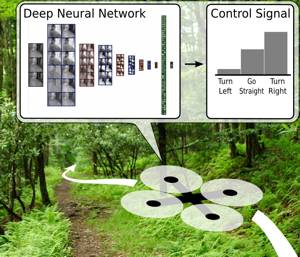
A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots
IEEE Robotics and Automation Letters (RA-L), pages 661 - 667, 2016
