

Learning Monocular Dense Depth from Events
Description
Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. Compared to conventional image sensors, they offer significant advantages: high temporal resolution, high dynamic range, no motion blur, and much lower bandwidth. Recently, learning-based approaches have been applied to event-based data, thus unlocking their potential and making significant progress in a variety of tasks, such as monocular depth prediction. Most existing approaches use standard feed-forward architectures to generate network predictions, which do not leverage the temporal consistency presents in the event stream. We propose a recurrent architecture to solve this task and show significant improvement over standard feed-forward methods. In particular, our method generates dense depth predictions using a monocular setup, which has not been shown previously. We pretrain our model using a new dataset containing events and depth maps recorded in the CARLA simulator. We test our method on the Multi Vehicle Stereo Event Camera Dataset (MVSEC). Quantitative experiments show up to 50% improvement in average depth error with respect to previous event-based methods.
Code for Depth Prediction
The reconstruction code and a trained model are available here.
Depth Estimation oN Synthetic Events - DENSE Dataset
The dataset used to pretrain the model in our paper Learning Monocular Dense Depth from Events is available in the table below. The camera parameters are set to mimic the event camera at MVSEC with a sensor size of 346 x 260 pixels (resolution of the DAVIS346B) and a focal length of 83 degrees horizontal field of view. DENSE splits into five sequences for training, two sequences for validation, and one sequence for testing. Each sequence consists of 1000 samples at 30 FPS and each sample is a tuple of one RGB image, the stream of events between two consecutive images, ground truth depth, and segmentation labels.
Citing
Please cite the following paper if you use this dataset or the event camera sensor in CARLA for your research:

Learning Monocular Dense Depth from Events
IEEE International Conference on 3D Vision (3DV), 2020.
Training Sequences
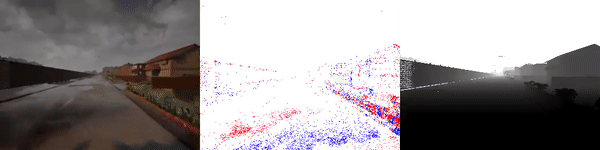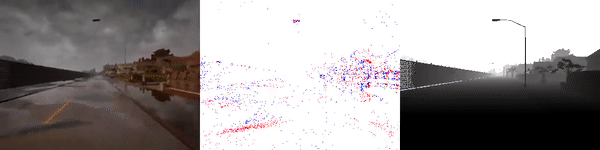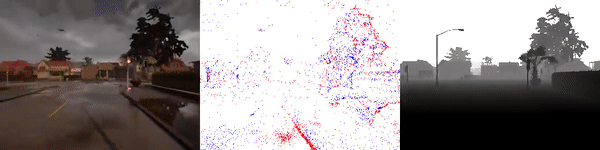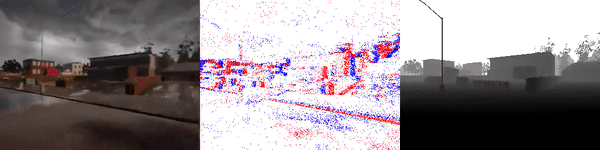
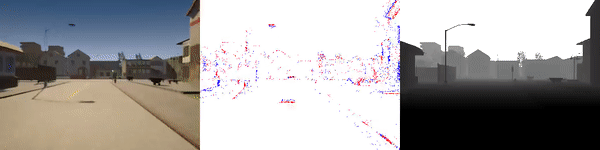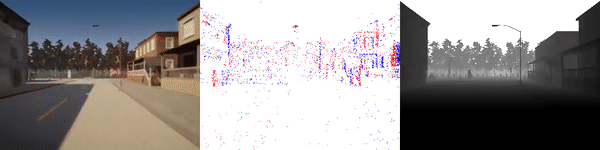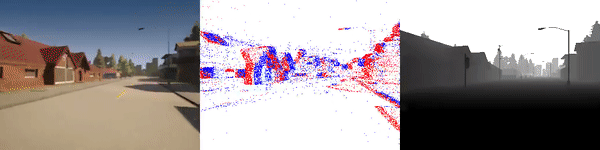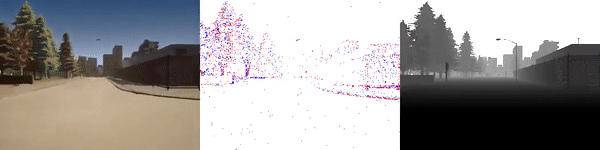
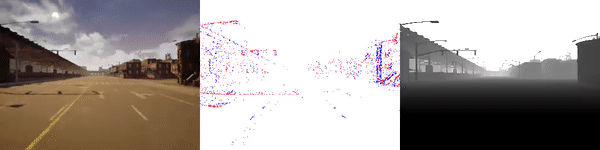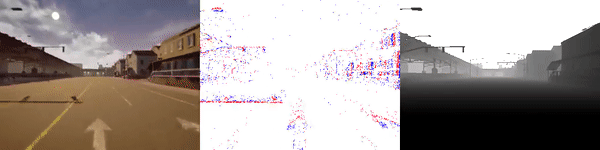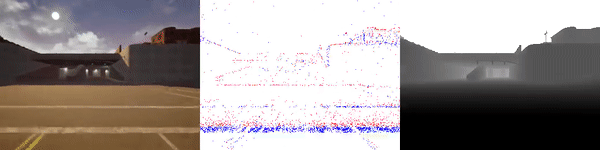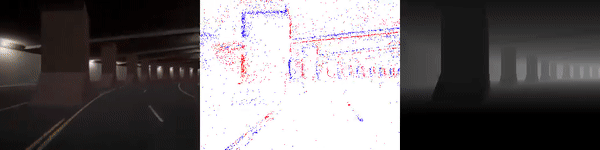

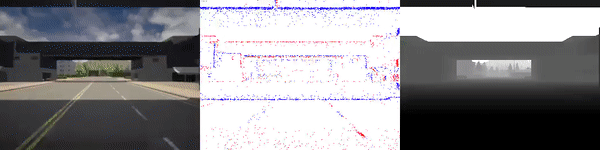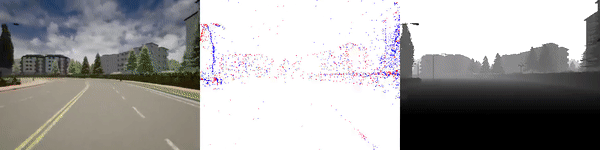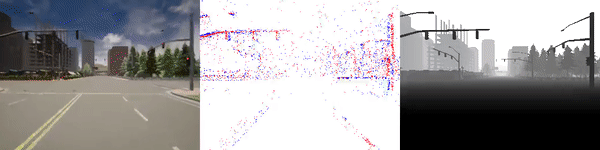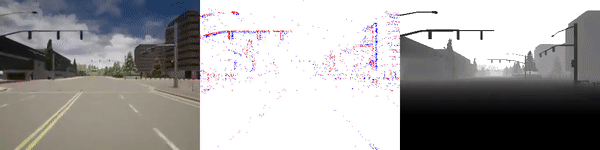
Validation Sequences
| Sequence Preview |
Download link |
|---|---|
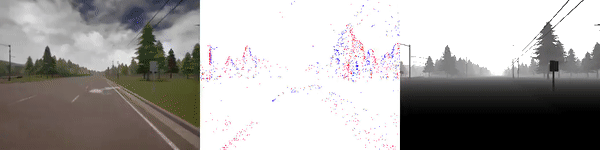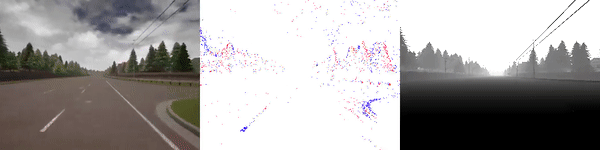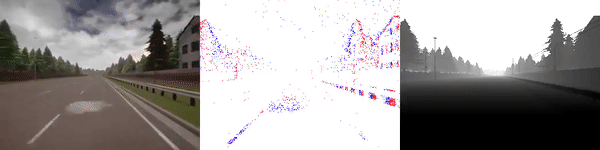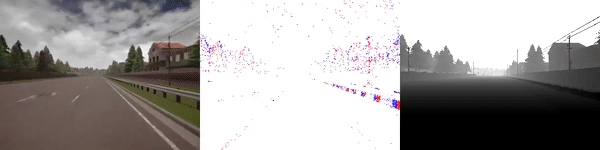 |
valid_sequence_00_town06.zip (274 MB) |
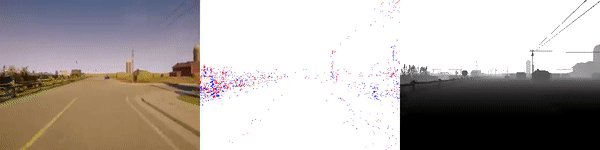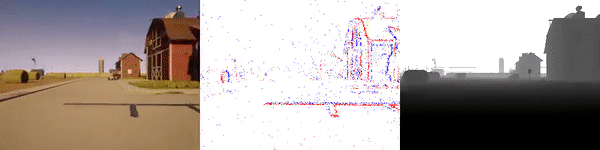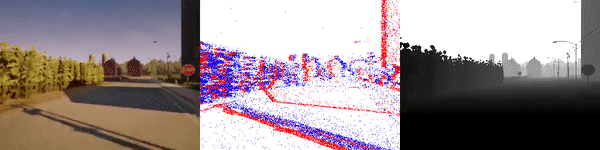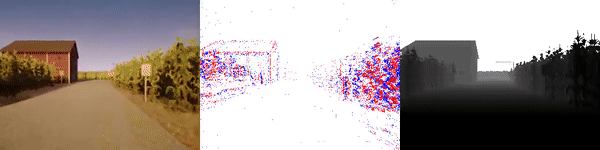 |
valid_sequence_01_town07.zip (402 MB) |
Test Sequences
| Sequence Preview |
Download link |
|---|---|
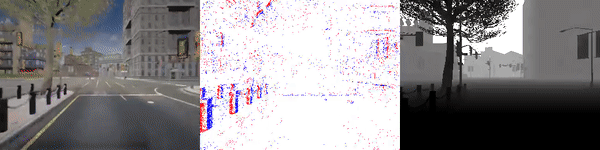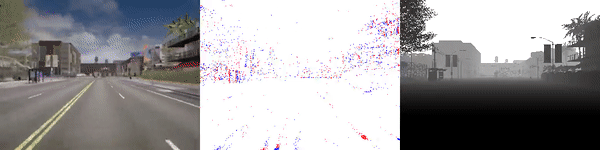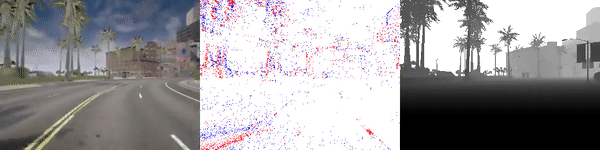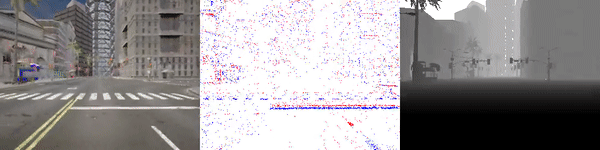 |
test_sequence_00_town10.zip (353 MB) |
MVSEC Sequences
| Outdoors Day1 |
Outdoors Day2 |
Outdoors Night1 |
Outdoors Night2 |
Outdoors Night3 |
|---|---|---|---|---|
| outdoor_day1.tar (4.1 GB) | outdoor_day2.tar (7.9 GB) | outdoor_night1.zip (3.3 GB) | outdoor_night2.zip (3.4 GB) | outdoor_night3.zip (3.0 GB) |
Acknowledgments
We thank Alessio Tonioni and Federico Tombari for their valuable help in this work.