



Agile Drone Flight
We work on perception, learning, planning, and control strategies to enable extremely agile maneuvers, which reach the limits of the actuators. While pushing the boundaries of our quadrotors, we also enable them to recover from difficult conditions in case of a failure.
Superhuman Safe and Agile Racing through Multi-Agent Reinforcement Learning
Autonomous systems have achieved superhuman performance in isolation or simulation, yet they remain brittle in shared, dynamic real-world spaces. This failure stems from the dominant single-agent paradigm for physical applications, where other actors are ignored or treated as environmental noise, preventing effective coordination. Here we show that multi-agent reinforcement learning provides the essential safety scaffolding required for real-world interaction. Using high-speed quadrotor racing as a high-stakes testbed, we train agents to navigate complex aerodynamic interactions and strategic maneuvering with a variable number of racers. Through league-based self-play, agents evolve sophisticated anticipatory behaviors, including proactive collision avoidance, overtaking, and handling multi-agent physical interactions, including aerodynamic downwash. Our agents outperform a champion-level human pilot in multi-player races at speeds exceeding 22 m/s, while simultaneously reducing collision rates by 50% compared to state-of-the-art single-agent baselines. Crucially, training with diverse artificial agents enables zero-shot generalization to safer human interaction.
References

Superhuman Safe and Agile Racing through Multi-Agent Reinforcement Learning
ArXiv Preprint, 2026.
Dream to Fly: Model-Based Reinforcement Learning for Vision-Based Drone Flight

Can we use Model-based Reinforcement Learning (MBRL) to fly a drone from pixels to commands? In our paper, we present an approach for training quadrotor navigation policies from scratch using world models to map raw onboard camera pixels directly to control commands, much like a human pilot. While model-free methods such as PPO are sample-inefficient and struggle in this setting, we leverage MBRL to train visuomotor policies capable of agile flight through a racetrack using only raw pixel observations. Moreover, because our policies are trained end-to-end directly from pixels, we no longer require the perception-aware reward term used in previous methods. Instead, we show that this behavior naturally emerges, resulting in policies that guide the camera toward feature-rich areas of the observation space.
References
Approximate Imitation Learning for Event-based Quadrotor Flight in Cluttered Environments

Event cameras offer high temporal resolution and low latency, making them ideal sensors for high-speed robotic applications where conventional cameras suffer from image degradations such as motion blur. In addition, their low power consumption can enhance endurance, which is critical for resource-constrained platforms. Motivated by these properties, we present a novel approach that enables a quadrotor to fly through cluttered environments at high speed by perceiving the environment with a single event camera. Our proposed method employs an end-to-end neural network trained to map event data directly to control commands, eliminating the reliance on standard cameras. To enable efficient training in simulation, where rendering synthetic event data is computationally expensive, we propose Approximate Imitation Learning, a novel imitation learning framework. Our approach leverages a large-scale offline dataset to learn a task-specific representation space. Subsequently, the policy is trained through online interactions that rely solely on lightweight, simulated state information, eliminating the need to render events during training. This enables the efficient training of event-based control policies for fast quadrotor flight, highlighting the potential of our framework for other modalities where data simulation is costly or impractical. Our approach outperforms standard imitation learning baselines in simulation and demonstrates robust performance in real-world flight tests, achieving speeds up to 9.8 m/s in cluttered environments.
References
Perception-Aware Time-Optimal Planning for Quadrotor Waypoint Flight

Agile quadrotor flight pushes the limits of control, actuation, and onboard perception. While time-optimal trajectory planning has been extensively studied, existing approaches typically neglect the tight coupling between vehicle dynamics, environmental geometry, and the visual requirements of onboard state estimation. As a result, trajectories that are dynamically feasible may fail in closed-loop execution due to degraded visual quality. This paper introduces a unified time-optimal trajectory optimization framework for vision-based quadrotors that explicitly incorporates perception constraints alongside full nonlinear dynamics, rotor actuation limits, aerodynamic effects, camera field-of-view constraints, and convex geometric gate representations. The proposed formulation solves minimum-time lap trajectories for arbitrary racetracks with diverse gate shapes and orientations, while remaining numerically robust and computationally efficient. We derive an information-theoretic position uncertainty metric to quantify visual state-estimation quality and integrate it into the planner through three perception objectives: position uncertainty minimization, sequential field-of-view constraints, and look-ahead alignment. This enables systematic exploration of the trade-offs between speed and perceptual reliability. To accurately track the resulting perception-aware trajectories, we develop a model predictive contouring tracking controller that separates lateral and progress errors. Experiments demonstrate real-world flight speeds up to 9.8 m/s with 0.07 m average tracking error, and closed-loop success rates improved from 55\% to 100\% on a challenging Split-S course. The proposed system provides a scalable benchmark for studying the fundamental limits of perception-aware, time-optimal autonomous flight.
References
Event-Aided Sharp Radiance Field Reconstruction for Fast-Flying Drones

Fast-flying aerial robots promise rapid inspection under limited battery constraints, with direct applications in infrastructure inspection, terrain exploration, and search and rescue. However, high speeds lead to severe motion blur in images and induce significant drift and noise in pose estimates, making dense 3D reconstruction with Neural Radiance Fields (NeRFs) particularly challenging due to their high sensitivity to such degradations. In this work, we present a unified framework that leverages asynchronous event streams alongside motion-blurred frames to reconstruct high-fidelity radiance fields from agile drone flights. By embedding event-image fusion into NeRF optimization and jointly refining event-based visual-inertial odometry priors using both event and frame modalities, our method recovers sharp radiance fields and accurate camera trajectories without ground-truth supervision. We validate our approach on both synthetic data and real-world sequences captured by a fast-flying drone. Despite highly dynamic drone flights, where RGB frames are severely degraded by motion blur and pose priors become unreliable, our method reconstructs high-fidelity radiance fields and preserves fine scene details, delivering a performance gain of over 50% on real-world data compared to state-of-the-art methods.
References
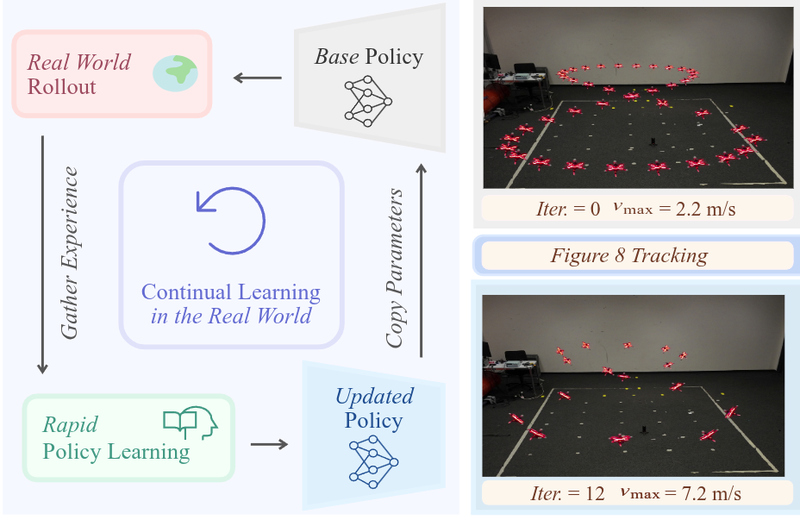
Learning Agile Quadrotor Flight in the Real World

Learning-based controllers have achieved impressive performance in agile quadrotor flight but typically rely on massive training in simulation, necessitating accurate system identification for effective Sim2Real transfer. However, even with precise modeling, fixed policies remain susceptible to out-of-distribution scenarios, ranging from external aerodynamic disturbances to internal hardware degradation. To ensure safety under these evolving uncertainties, such controllers are forced to operate with conservative safety margins, inherently constraining their agility outside of controlled settings. While online adaptation offers a potential remedy, safely exploring physical limits remains a critical bottleneck due to data scarcity and safety risks. To bridge this gap, we propose a self-adaptive framework that eliminates the need for precise system identification or offline Sim2Real transfer. We introduce Adaptive Temporal Scaling (ATS) to actively explore platform physical limits, and employ online residual learning to augment a simple nominal model. Based on the learned hybrid model, we further propose Real-world Anchored Short-horizon Backpropagation Through Time (RASH-BPTT) to achieve efficient and robust in-flight policy updates. Extensive experiments demonstrate that our quadrotor reliably executes agile maneuvers near actuator saturation limits. The system evolves a conservative base policy with a peak speed of 1.9 m/s to 7.3 m/s within approximately 100 seconds of flight time. These findings underscore that real-world adaptation serves not merely to compensate for modeling errors, but as a practical mechanism for sustained performance improvement in aggressive flight regimes.
References
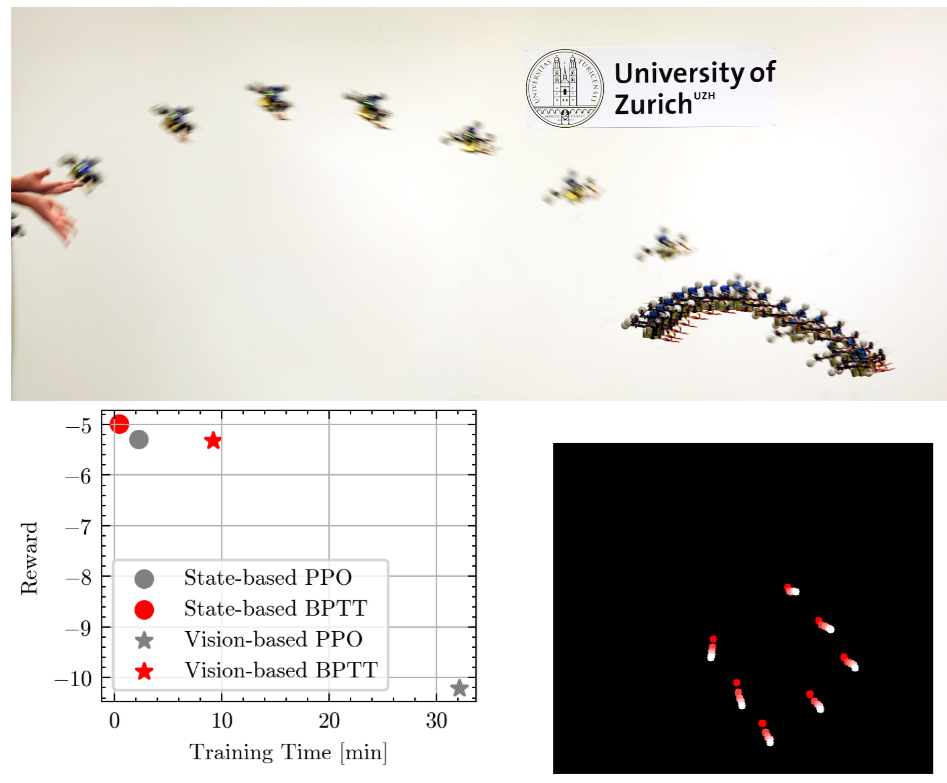
Learning Quadrotor Control From Visual Features Using Differentiable Simulation
The sample inefficiency of reinforcement learning (RL) remains a significant challenge in robotics. RL requires large-scale simulation and can still cause long training times, slowing research and innovation. This issue is particularly pronounced in vision-based control tasks where reliable state estimates are not accessible Differentiable simulation offers an alternative by enabling gradient back-propagation through the dynamics model, providing low-variance analytical policy gradients and, hence, higher sample efficiency. However, its usage for real-world robotic tasks has yet been limited. This work demonstrates the great potential of differentiable simulation for learning quadrotor control. We show that training in differentiable simulation significantly outperforms model-free RL in terms of both sample efficiency and training time, allowing a policy to learn to recover a quadrotor in seconds when providing vehicle states and in minutes when relying solely on visual features. The key to our success is two-fold. First, the use of a simple surrogate model for gradient computation greatly accelerates training without sacrificing control performance. Second, combining state representation learning with policy learning enhances convergence speed in tasks where only visual features are observable. These findings highlight the potential of differentiable simulation for real-world robotics and offer a compelling alternative to conventional RL approaches.
References
Low-Latency Event-Based Velocimetry for Quadrotor Control in a Narrow Pipe
Autonomous quadrotor flight in confined spaces such as pipes and tunnels presents significant challenges due to unsteady, self-induced aerodynamic disturbances. Very recent advances have enabled flight in such conditions, but they either rely on constant motion through the pipe to mitigate airflow recirculation effects or suffer from limited stability during hovering. In this work, we present the first closed-loop control system for quadrotors for hovering in narrow pipes that leverages real-time flow field measurements. We develop a low-latency, event-based smoke velocimetry method that estimates local airflow at high temporal resolution. This flow information is used by a disturbance estimator based on a recurrent convolutional neural network, which infers force and torque disturbances in real time. The estimated disturbances are integrated into a learning-based controller trained via reinforcement learning. The flow-feedback control proves particularly effective during lateral translation maneuvers in the pipe cross-section. There, the real-time disturbance information enables the controller to effectively counteract transient aerodynamic effects, thereby preventing collisions with the pipe wall. To the best of our knowledge, this work represents the first demonstration of an aerial robot with closed-loop control informed by real-time flow field measurements. This opens new directions for research on flight in aerodynamically complex environments. In addition, our work also sheds light on the characteristic flow structures that emerge during flight in narrow, circular pipes, providing new insights at the intersection of robotics and fluid dynamics.
References

Learning on the Fly: Rapid Policy Adaptation via Differentiable Simulation
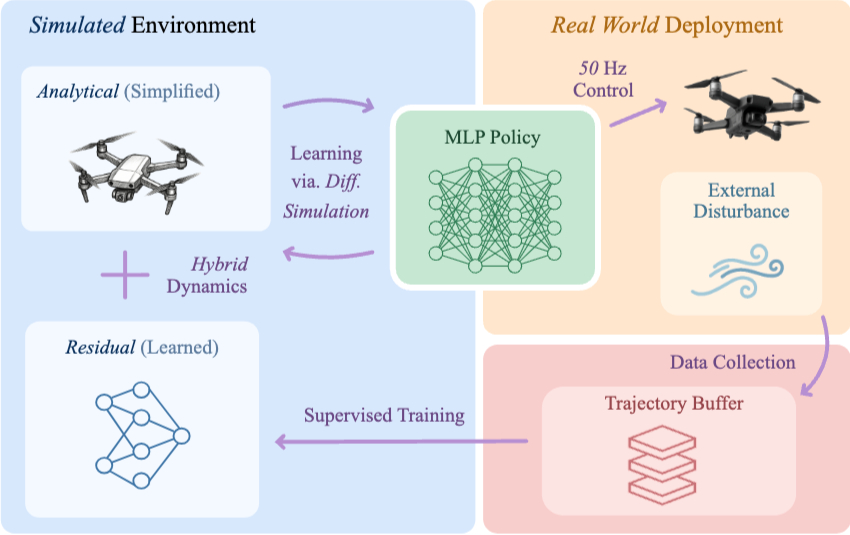
Learning control policies in simulation enables rapid, safe, and cost-effective development of advanced robotic capabilities. However, transferring these policies to the real world remains difficult due to the sim-to-real gap, where unmodeled dynamics and environmental disturbances can degrade policy performance. Existing approaches, such as domain randomization and Real2Sim2Real pipelines, can improve policy robustness, but either struggle under out-of-distribution conditions or require costly offline retraining. In this work, we approach these problems from a different perspective. Instead of relying on diverse training conditions before deployment, we focus on rapidly adapting the learned policy in the real world in an online fashion. To achieve this, we propose a novel online adaptive learning framework that unifies residual dynamics learning with real time policy adaptation inside a differentiable simulation. Starting from a simple dynamics model, our framework refines the model continuously with real-world data to captured unmodeled effects and disturbances such as payload changes and wind. The refined dynamics model is embedded in a differentiable simulation framework, enabling gradient backpropagation through the dynamics and thus rapid, sample-efficient policy updates beyond the reach of classical RL methods like PPO. All components of our system are designed for rapid adaptation, enabling the policy to adjust to unseen disturbances within 5 seconds of training. We validate the approach on agile quadrotor control under various disturbances in both simulation and the real world. Our framework reduces hovering error by up to 81% compared to L1-MPC and 55% compared to DATT, while also demonstrating robustness in vision-based control without explicit state estimation.
References
Unifying Quadrotor Motion Planning and Control by Chaining Different Fidelity Models

Many aerial tasks involving quadrotors demand both instant reactivity and long-horizon planning. High-fidelity models enable accurate control but are too slow for long horizons; low-fidelity planners scale but degrade closed-loop performance. We present Unique, a unified MPC that cascades models of different fidelity within a single optimization: a short-horizon, high-fidelity model for accurate control, and a long-horizon, low-fidelity model for planning. We align costs across horizons, derive feasibility-preserving thrust and body-rate constraints for the point-mass model, and introduce transition constraints that match the different states, thrust-induced acceleration, and jerk–body-rate relations. To prevent local minima emerging from nonsmooth clutter, we propose a 3D progressive smoothing schedule that morphs norm-based obstacles along the horizon. In addition, we deploy parallel randomly initialized MPC solvers to discover lower-cost local minima on the long, low-fidelity horizon. In simulation and real flights, under equal computational budgets, Unique improves closed-loop position or velocity tracking by up to 75 percent compared with standard MPC and hierarchical planner–tracker baselines. Ablations and Pareto analyses confirm robust gains across horizon variations, constraint approximations, and smoothing schedules.
References

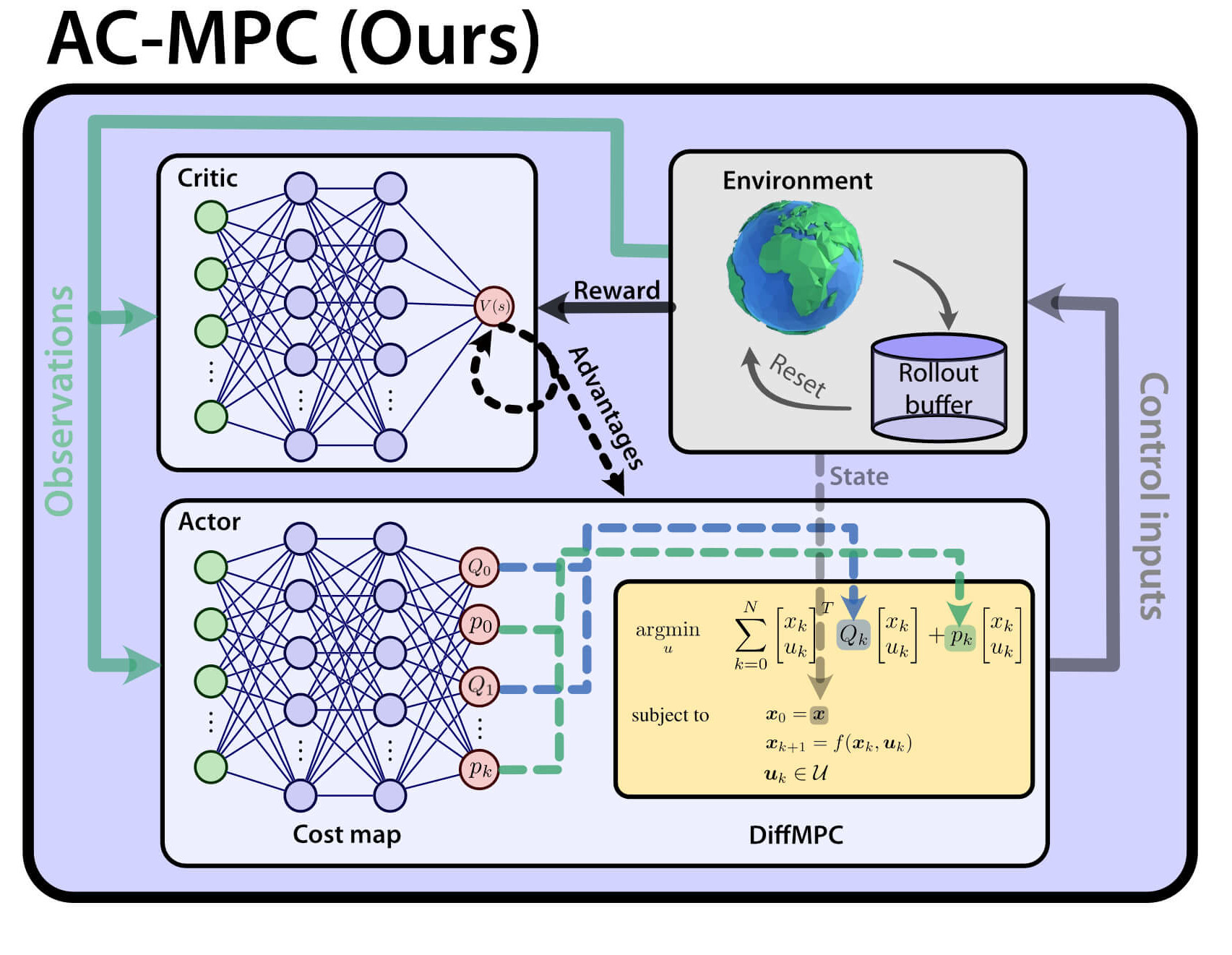
Actor-Critic Model Predictive Control: Differentiable Optimization meets Reinforcement Learning
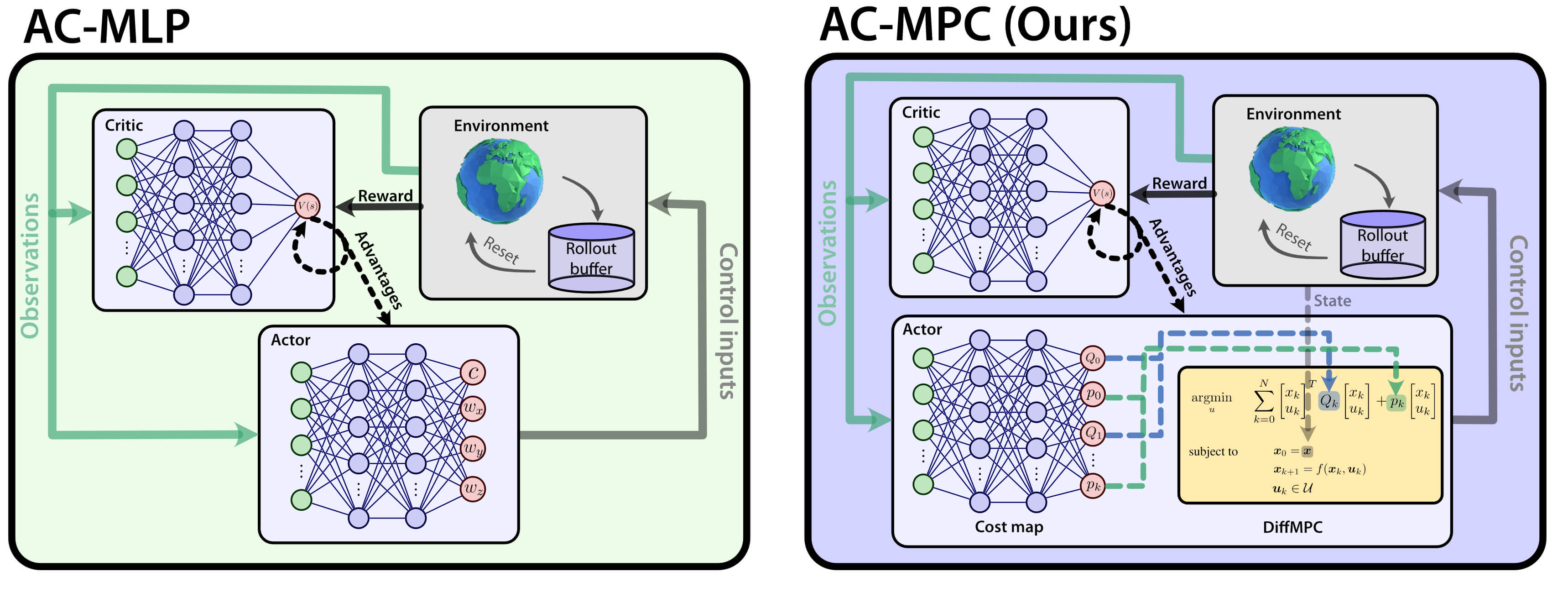
Is it possible to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC)? This extension digs deeper into the answer by studying our new framework called Actor-Critic Model Predictive Control. We conduct a deep study that exposes the benefits of the proposed approach: it achieves better out-of-distribution behaviour, better robustness to changes in the dynamics and improved sample efficiency. Additionally, we conduct an empirical analysis that reveals a relationship between the critic's learned value function and the cost function of the differentiable MPC, providing a deeper understanding of the interplay between the critic's value and the MPC cost functions. Our method achieves the same superhuman performance as state-of-the-art model-free RL, showcasing speeds of up to 21 m/s.
References
HDVIO2.0: Wind and Disturbance Estimation with Hybrid Dynamics VIO

Visual-inertial odometry (VIO) is widely used for state estimation in autonomous micro aerial vehicles using onboard sensors. Current methods improve VIO by incorporating a model of the translational vehicle dynamics, yet their performance degrades when faced with low-accuracy vehicle models or continuous external disturbances, like wind. Additionally, incorporating rotational dynamics in these models is computationally intractable when they are deployed in online applications, e.g., in a closed-loop control system. We present HDVIO2.0, which models full 6-DoF, translational and rotational, vehicle dynamics and tightly incorporates them into a VIO with minimal impact on the runtime. HDVIO2.0 builds upon the previous work, HDVIO, and addresses these challenges through a hybrid dynamics model combining a point-mass vehicle model with a learning-based component, with access to control commands and IMU history, to capture complex aerodynamic effects. The key idea behind modeling the rotational dynamics is to represent them with continuous-time functions. HDVIO2.0 leverages the divergence between the actual motion and the predicted motion from the hybrid dynamics model to estimate external forces as well as the robot state. Our system surpasses the performance of state-of-the-art methods in experiments using public and new drone dynamics datasets, as well as real-world flights in winds up to 25 km/h. Unlike existing approaches, we also show that accurate vehicle dynamics predictions are achievable without precise knowledge of the full vehicle state.
References
Learning Acrobatic Flight from Preferences
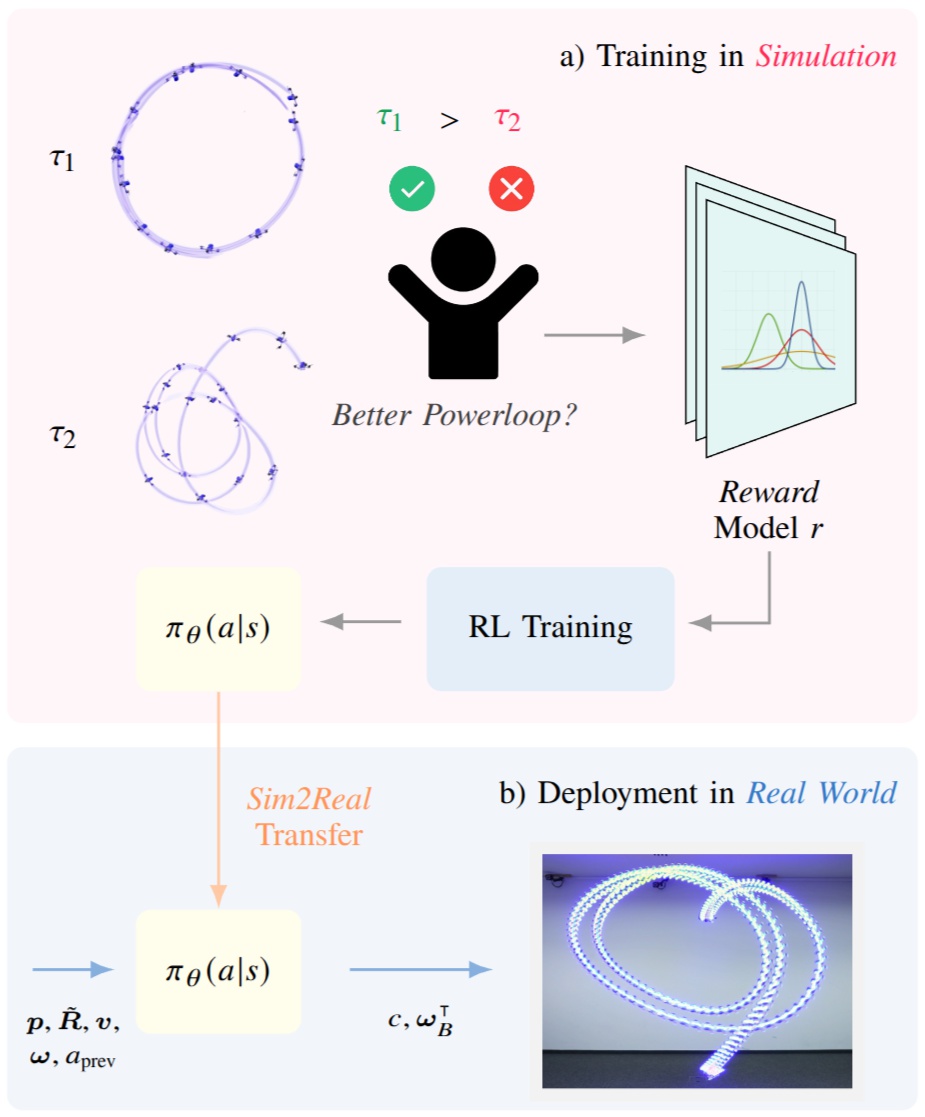
Preference-based reinforcement learning (PbRL) enables agents to learn control policies without requiring manually designed reward functions, making it well-suited for tasks where objectives are difficult to formalize or inherently subjective. Acrobatic flight poses a particularly challenging problem due to its complex dynamics, rapid movements, and the importance of precise execution. However, manually designed reward functions for such tasks often fail to capture the qualities that matter: we find that hand-crafted rewards agree with human judgment only 60.7% of the time, underscoring the need for preference-driven approaches. In this work, we propose Reward Ensemble under Confidence (REC), a probabilistic reward learning framework for PbRL that explicitly models per-timestep reward uncertainty through an ensemble of distributional reward models. By propagating uncertainty into the preference loss and leveraging disagreement for exploration, REC achieves 88.4% of shaped reward performance on acrobatic quadrotor control, compared to 55.2% with standard Preference PPO. We train policies in simulation and successfully transfer them zero-shot to the real world, demonstrating complex acrobatic maneuvers learned purely from preference feedback. We further validate REC on a continuous control benchmark, confirming its applicability beyond the domain of aerial robotics.
References
Regularity and Stability Properties of Selective SSMs with Discontinuous Gating
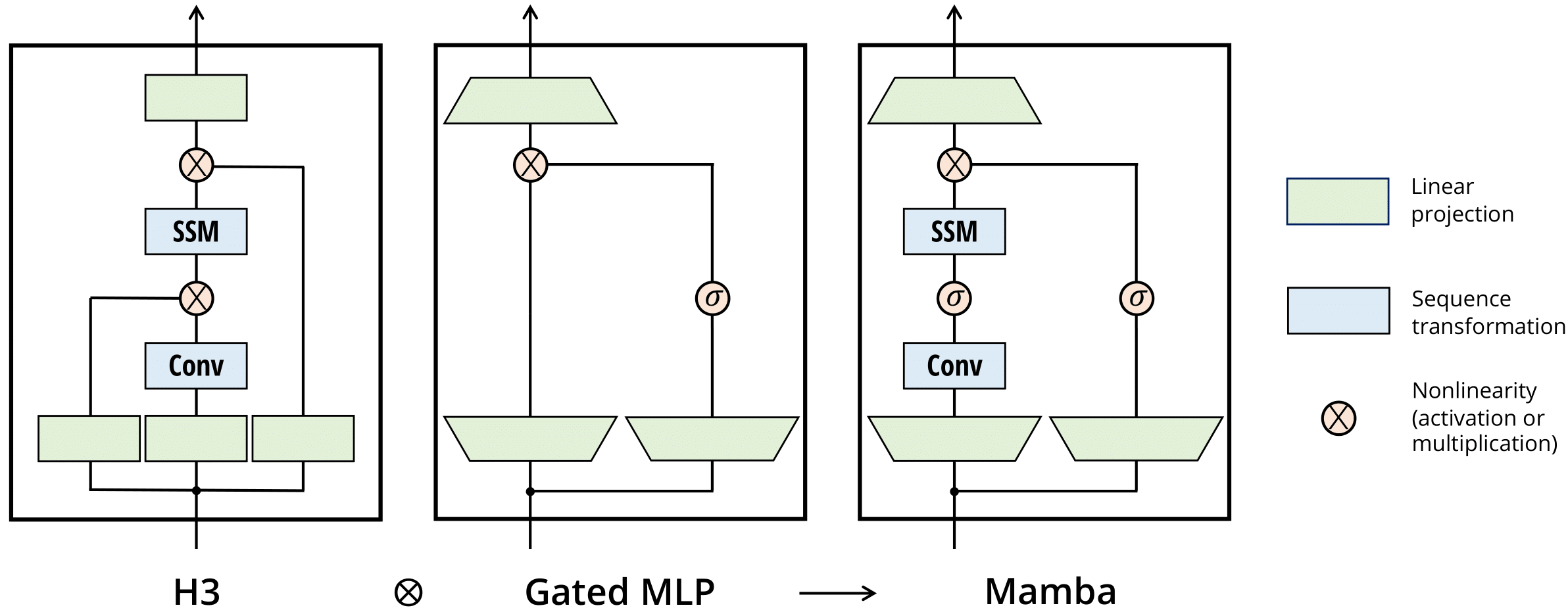
Deep Selective State-Space Models (SSMs), characterized by input-dependent, time-varying parameters, offer significant expressive power but pose challenges for stability analysis, especially with discontinuous gating signals. In this paper, we investigate the stability and regularity properties of continuous-time selective SSMs through the lens of passivity and Input-to-State Stability (ISS). We establish that intrinsic energy dissipation guarantees exponential forgetting of past states. Crucially, we prove that the unforced system dynamics possess an underlying minimal quadratic energy function whose defining matrix exhibits robust AUCloc regularity, accommodating discontinuous gating. Furthermore, assuming a universal quadratic storage function ensures passivity across all inputs, we derive parametric LMI conditions and kernel constraints that limit gating mechanisms, formalizing "irreversible forgetting" of recurrent models. Finally, we provide sufficient conditions for global ISS, linking uniform local dissipativity to overall system robustness. Our findings offer a rigorous framework for understanding and designing stable and reliable deep selective SSMs.
References
Environment as Policy: Learning to Race in Unseen Tracks

Reinforcement learning (RL) has achieved outstanding success in complex robot control tasks, such as drone racing, where the RL agents have outperformed human champions in a known racing track. However, these agents fail in unseen track configurations, always requiring complete retraining when presented with new track layouts. This work aims to develop RL agents that generalize effectively to novel track configurations without retraining. The na¨ıve solution of training directly on a diverse set of track layouts can overburden the agent, resulting in suboptimal policy learning as the increased complexity of the environment impairs the agent’s ability to learn to fly. To enhance the generalizability of the RL agent, we propose an adaptive environment-shaping framework that dynamically adjusts the training environment based on the agent’s performance. We achieve this by leveraging a secondary RL policy to design environments that strike a balance between being challenging and achievable, allowing the agent to adapt and improve progressively. Using our adaptive environment shaping, one single racing policy efficiently learns to race in diverse challenging tracks. Experimental results validated in both simulation and the real world show that our method enables drones to successfully fly complex and unseen race tracks, outperforming existing environment-shaping techniques.
References

Environment as Policy: Learning to Race in Unseen Tracks
IEEE International Conference on Robotics and Automation (ICRA), 2025.
Student-Informed Teacher Training
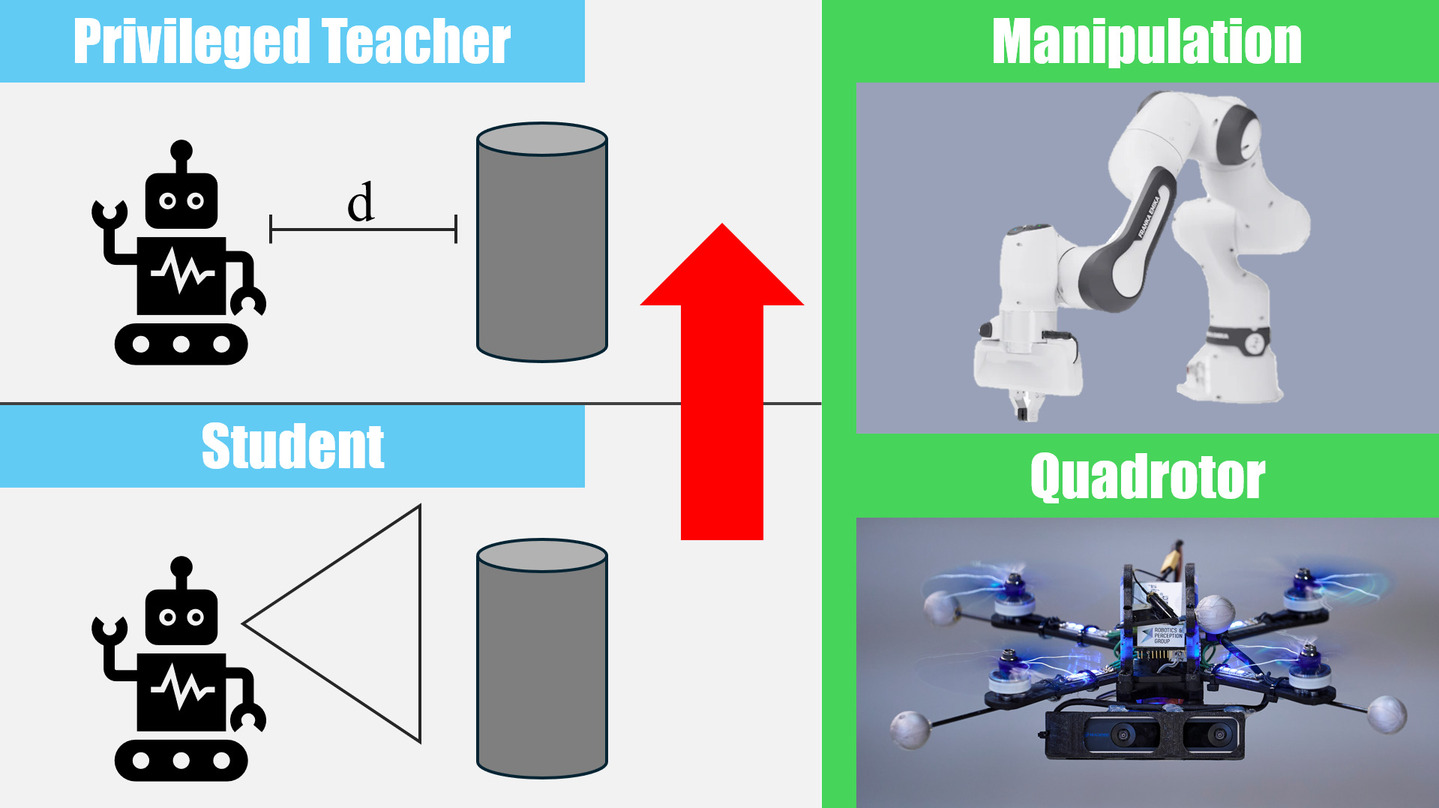
Imitation learning with a privileged teacher has proven effective for learning complex control behaviors from high-dimensional inputs, such as images. In this framework, a teacher is trained with privileged task information, while a student tries to predict the actions of the teacher with more limited observations, e.g., in a robot navigation task, the teacher might have access to distances to nearby obstacles, while the student only receives visual observations of the scene. However, privileged imitation learning faces a key challenge: the student might be unable to imitate the teacher's behavior due to partial observability. This problem arises because the teacher is trained without considering if the student is capable of imitating the learned behavior. To address this teacher-student asymmetry, we propose a framework for joint training of the teacher and student policies, encouraging the teacher to learn behaviors that can be imitated by the student despite the latters' limited access to information and its partial observability. Based on the performance bound in imitation learning, we add (i) the approximated action difference between teacher and student as a penalty term to the reward function of the teacher, and (ii) a supervised teacher-student alignment step. We motivate our method with a maze navigation task and demonstrate its effectiveness on complex vision-based quadrotor flight and manipulation tasks.
References
Student-Informed Teacher Training
International Conference on Learning Representations (ICLR), 2025.
Spotlight Presentation.
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control

We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego- trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, egotrajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations.
References
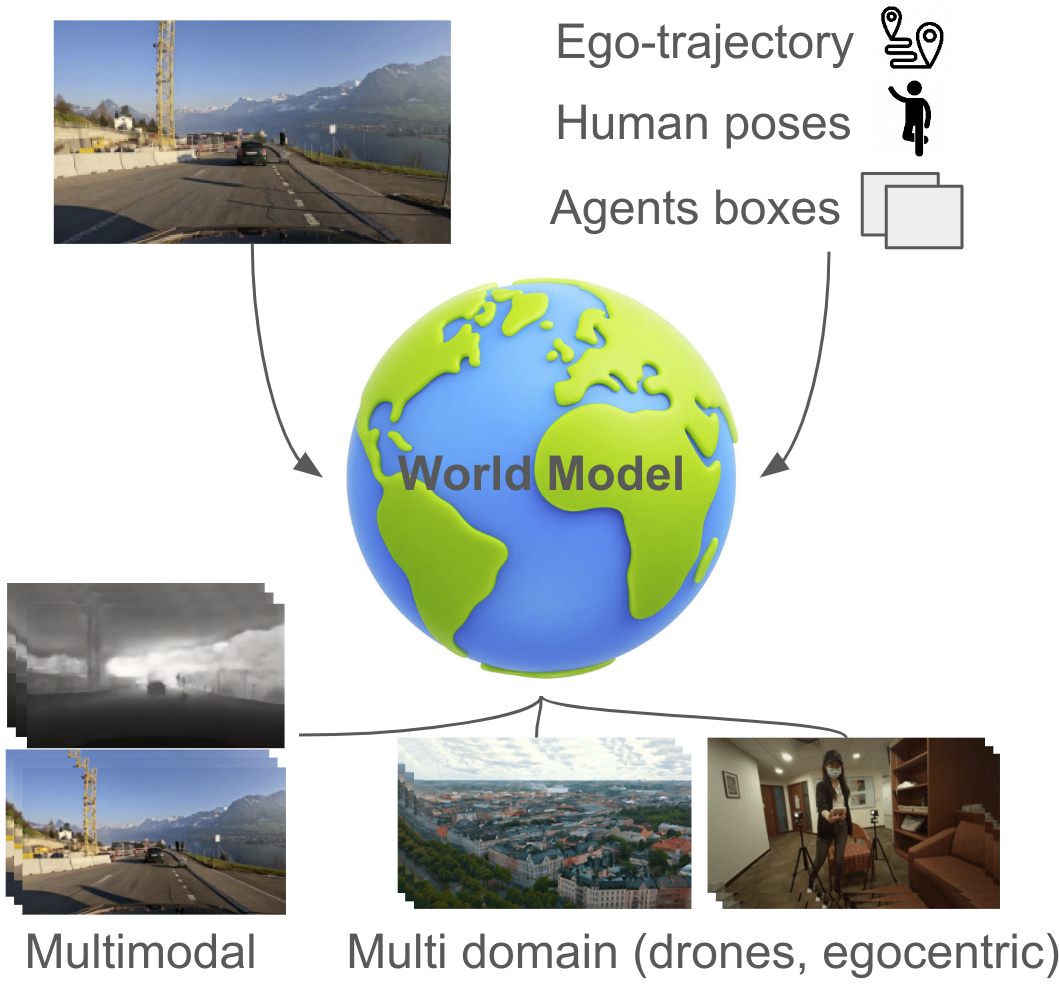
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
ArXiv, 2024.
Multi-task Reinforcement Learning for Quadrotors
Reinforcement learning (RL) has shown great effectiveness in quadrotor control, enabling specialized policies to develop even human-champion-level performance in single-task scenarios. However, these specialized policies often struggle with novel tasks, requiring a complete retraining of the policy from scratch. To address this limitation, this paper presents a novel multi-task reinforcement learning (MTRL) framework tailored for quadrotor control, leveraging the shared physical dynamics of the platform to enhance sample efficiency and task performance. By employing a multi-critic architecture and shared task encoders, our framework facilitates knowledge transfer across tasks, enabling a single policy to execute diverse maneuvers, including high-speed stabilization, velocity tracking, and autonomous racing. Our experimental results, validated both in simulation and real-world scenarios, demonstrate that our framework outperforms baseline approaches in terms of sample efficiency and overall task performance.
References

Robotics meets Fluid Dynamics: A Characterization of the Induced Airflow around a Quadrotor
The widespread adoption of quadrotors for diverse applications, from agriculture to public safety, necessitates an understanding of the aerodynamic disturbances they create. This paper introduces a computationally lightweight model for estimating the time-averaged magnitude of the induced flow below quadrotors in hover. Unlike related approaches that rely on expensive computational fluid dynamics (CFD) simulations or drone specific time-consuming empirical measurements, our method leverages classical theory from turbulent flows. By analyzing over 16 hours of flight data from drones of varying sizes within a large motion capture system, we show for the first time that the combined flow from all drone propellers is well-approximated by a turbulent jet after 2.5 drone-diameters below the vehicle. Using a novel normalization and scaling, we experimentally identify model parameters that describe a unified mean velocity field below differently sized quadrotors. The model, which requires only the drone's mass, propeller size, and drone size for calculations, accurately describes the far-field airflow over a long-range in a very large volume which is impractical to simulate using CFD. Our model offers a practical tool for ensuring safer operations near humans, optimizing sensor placements and drone control in multi-agent scenarios. We demonstrate the latter by designing a controller that compensates for the downwash of another drone, leading to a four times lower altitude deviation when passing below.
References

Bootstrapping Reinforcement Learning with Imitation for Vision-Based Agile Flight

We combine the effectiveness of Reinforcement Learning (RL) and the efficiency of Imitation Learning (IL) in the context of vision-based, autonomous drone racing. We focus on directly processing visual input without explicit state estimation. While RL offers a general framework for learning complex controllers through trial and error, it faces challenges regarding sample efficiency and computational demands due to the high dimensionality of visual inputs. Conversely, IL demonstrates efficiency in learning from visual demonstrations but is limited by the quality of those demonstrations and faces issues like covariate shift. To overcome these limitations, we propose a novel training framework combining RL and IL advantages. Our framework involves three stages: (i) initial training of a teacher policy using privileged state information, (ii) distilling this policy into a student policy using IL, (iii) performance-constrained adaptive RL fine-tuning. Our experiments in both simulated and real-world environments demonstrate that our approach achieves superior performance and robustness than IL or RL alone in navigating a quadrotor through a racing course using only visual information without explicit state estimation.
References
Monocular Event-Based Vision for Obstacle Avoidance with a Quadrotor
We present the first static-obstacle avoidance method for quadrotors using just an onboard, monocular event camera. Quadrotors are capable of fast and agile flight in cluttered environments when piloted manually, but vision-based autonomous flight in unknown environments is difficult in part due to the sensor limitations of traditional onboard cameras. Event cameras, however, promise nearly zero motion blur and high dynamic range, but produce a very large volume of events under significant ego-motion and further lack a continuous-time sensor model in simulation, making direct sim-to-real transfer not possible. By leveraging depth prediction as a pretext task in our learning framework, we can pre-train a reactive obstacle avoidance events-to-control policy with approximated, simulated events and then fine-tune the perception component with limited events-and-depth real-world data to achieve obstacle avoidance in indoor and outdoor settings. We demonstrate this across two quadrotor-event camera platforms in multiple settings and find, contrary to traditional vision-based works, that low speeds (1m/s) make the task harder and more prone to collisions, while high speeds (5m/s) result in better event-based depth estimation and avoidance. We also find that success rates in outdoor scenes can be significantly higher than in certain indoor scenes.
References

Monocular Event-Based Vision for Obstacle Avoidance with a Quadrotor
Conference on Robot Learning (CoRL), 2024
Demonstrating Agile Flight from Pixels without State Estimation
We present the first vision-based quadrotor system that autonomously navigates through a sequence of gates at high speeds while directly mapping pixels to control commands. Like professional drone-racing pilots, our system does not use explicit state estimation and leverages the same control commands humans use (collective thrust and body rates). We demonstrate agile flight at speeds up to 40km/h with accelerations up to 2g. This is achieved by training vision-based policies with reinforcement learning (RL). The training is facilitated using an asymmetric actor-critic with access to privileged information. To overcome the computational complexity during image-based RL training, we use the inner edges of the gates as a sensor abstraction. Our approach enables autonomous agile flight with standard, off-the-shelf hardware.
References

Learning Agile, Vision-Based Drone Flight: From Simulation to Reality

We present our latest research in learning deep sensorimotor policies for agile, vision-based quadrotor flight. We show methodologies for the successful transfer of such policies from simulation to the real world. In addition, we discuss the open research questions that still need to be answered to improve the agility and robustness of autonomous drones toward human-pilot performance.
References
MPCC++: Model Predictive Contouring Control for Time-Optimal Flight with Safety Constraints
This paper introduces three key components that enhance the MPCC approach for drone racing. First, we provide safety guarantees in the form of a constraint and tunnel-shaped terminal set, which prevents gate collisions. Second, we augment the dynamics with a residual term that captures complex aerodynamic effects and thrust forces learned directly from real world data. Third, we use Trust Region Bayesian Optimization (TuRBO) to tune the hyperparameters of the MPC controller given a sparse reward based on lap time minimization. The proposed approach achieves similar lap times to the best state-of-the-art RL while satisfying constraints, achieving 100% success rate in simulation and real-world.
References

Autonomous Drone Racing: A Survey

Over the last decade, the use of autonomous drone systems for surveying, search and rescue, or last-mile delivery has increased exponentially. With the rise of these applications comes the need for highly robust, safety-critical algorithms which can operate drones in complex and uncertain environments. Additionally, flying fast enables drones to cover more ground which in turn increases productivity and further strengthens their use case. One proxy for developing algorithms used in high-speed navigation is the task of autonomous drone racing, where researchers program drones to fly through a sequence of gates and avoid obstacles as quickly as possible using onboard sensors and limited computational power. Speeds and accelerations exceed over 80 kph and 4 g respectively, raising significant challenges across perception, planning, control, and state estimation. To achieve maximum performance, systems require real-time algorithms that are robust to motion blur, high dynamic range, model uncertainties, aerodynamic disturbances, and often unpredictable opponents. This survey covers the progression of autonomous drone racing across model-based and learning-based approaches. We provide an overview of the field, its evolution over the years, and conclude with the biggest challenges and open questions to be faced in the future.
References
Actor-Critic Model Predictive Control
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the robustness inherent to MPC.
References

Actor-Critic Model Predictive Control
IEEE International Conference on Robotics and Automation (ICRA), Yokohama, 2024.
Contrastive Initial State Buffer for Reinforcement Learning
In Reinforcement Learning, the trade-off between exploration and exploitation poses a complex challenge for achieving efficient learning from limited samples. While recent works have been effective in leveraging past experiences for policy updates, they often overlook the potential of reusing past experiences for data collection. Independent of the underlying RL algorithm, we introduce the concept of a Contrastive Initial State Buffer, which strategically selects states from past experiences and uses them to initialize the agent in the environment in order to guide it toward more informative states. We validate our approach on two complex robotic tasks without relying on any prior information about the environment: (i) locomotion of a quadruped robot traversing challenging terrains and (ii) a quadcopter drone racing through a track. The experimental results show that our initial state buffer achieves higher task performance than the nominal baseline while also speeding up training convergence.
References

Contrastive Learning for Enhancing Robust Scene Transfer in Vision-based Agile Flight
Scene transfer for vision-based mobile robotics applications is a highly relevant and challenging problem. The utility of a robot greatly depends on its ability to perform a task in the real world, outside of a well-controlled lab environment. Existing scene transfer end-to-end policy learning approaches often suffer from poor sample efficiency or limited generalization capabilities, making them unsuitable for mobile robotics applications. This work proposes an adaptive multi- pair contrastive learning strategy for visual representation learning that enables zero-shot scene transfer and real-world deployment. Control policies relying on the embedding are able to operate in unseen environments without the need for finetuning in the deployment environment. We demonstrate the performance of our approach on the task of agile, vision-based quadrotor flight. Extensive simulation and real-world experi- ments demonstrate that our approach successfully generalizes beyond the training domain and outperforms all baselines.
References

Reaching the Limit in Autonomous Racing: Optimal Control vs. Reinforcement Learning
Why can ReinforcementLearning (RL) achieve results beyond OptimalControl (OC) in many real-world robotics control tasks? We investigate this question in our paper published today in Science Robotics. We argue that this question can be investigated along two axes: the optimization method and the optimization objective. Our results indicate that RL does not outperform OC because RL optimizes its objective better. Rather, RL outperforms OC because it optimizes a better objective. RL can directly optimize a task-level objective and can leverage domain randomization to cope with model uncertainty, allowing the discovery of more robust control responses. Beyond the fundamental study, our work contributes an RL-based controller that delivers the highest performance ever demonstrated on an autonomous racing drone. Our drone achieved remarkable performance: peak acceleration greater than 12 g and peak velocity ~108 km/h, all within minutes of training with a standard workstation.
References

Champion-level Drone Racing using Deep Reinforcement Learning
First-person view (FPV) drone racing is a televised sport in which professional competitors pilot high-speed aircraft through a three-dimensional circuit. Each pilot sees the environment from their drone's perspective via video streamed from an onboard camera. Reaching the level of professional pilots with an autonomous drone is challenging since the robot needs to fly at its physical limits while estimating its speed and location in the circuit exclusively from onboard sensors. Here we introduce Swift, an autonomous system that can race physical vehicles at the level of the human world champions. The system combines deep reinforcement learning in simulation with data collected in the physical world. Swift competed against three human champions, including the world champions of two international leagues, in real-world head-to-head races. Swift won multiple races against each of the human champions and demonstrated the fastest recorded race time. This work represents a milestone for mobile robotics and machine intelligence, which may inspire the deployment of hybrid learning-based solutions in other physical systems.
References

Champion-level Drone Racing using Deep Reinforcement Learning
Nature, 2023
Real-time Neural MPC: Deep Learning Model Predictive Control for Quadrotors and Agile Robotic Platforms

Model Predictive Control (MPC) has become a popular framework in embedded control for high-performance autonomous systems. However, to achieve good control performance using MPC, an accurate dynamics model is key. To maintain real-time operation, the dynamics models used on embedded systems have been limited to simple first-principle models, which substantially limits their representative power. In contrast to such simple models, machine learning approaches, specifically neural networks, have been shown to accurately model even complex dynamic effects, but their large computational complexity hindered combination with fast real-time iteration loops. With this work, we present Real-time Neural MPC, a framework to efficiently integrate large, complex neural network architectures as dynamics models within a model-predictive control pipeline. Our experiments, performed in simulation and the real world onboard a highly agile quadrotor platform, demonstrate the capabilities of the described system to run learned models with, previously infeasible, large modeling capacity using gradient-based online optimization MPC. Compared to prior implementations of neural networks in online optimization MPC we can leverage models of over 4000 times larger parametric capacity in a 50Hz real-time window on an embedded platform. Further, we show the feasibility of our framework on real-world problems by reducing the positional tracking error by up to 82% when compared to state-of-the-art MPC approaches without neural network dynamics.
References
Learning Deep Sensorimotor Policies for Vision-based Autonomous Drone Racing
Autonomous drones can operate in remote and unstructured environments, enabling various real-world applications. However, the lack of effective vision-based algorithms has been a stumbling block to achieving this goal. Existing systems often require hand-engineered components for state estimation, planning, and control. Such a sequential design involves laborious tuning, human heuristics, and compounding delays and errors. This paper tackles the vision-based autonomous-drone racing problem by learning deep sensorimotor policies. We use contrastive learning to extract robust feature representations from the input images and leverage a two-stage learning-by-cheating framework for training a neural network policy. The resulting policy directly infers control commands with feature representations learned from raw images, forgoing the need for globally-consistent state estimation, trajectory planning, and handcrafted control design. Our experimental results indicate that our vision-based policy can achieve the same level of racing performance as the state-based policy while being robust against different visual disturbances and distractors. This work serves as a stepping-stone toward developing intelligent vision-based autonomous systems that control the drone purely from image inputs, like human pilots.
References

Microgravity induces overconfidence in perceptual decision-making
Does gravity affect decision-making? This question comes into sharp focus as plans for interplanetary human space missions solidify. In the framework of Bayesian brain theories, gravity encapsulates a strong prior, anchoring agents to a reference frame via the vestibular system, informing their decisions and possibly their integration of uncertainty. What happens when such a strong prior is altered? We address this question using a self-motion estimation task in a space analog environment under conditions of altered gravity. Two participants were cast as remote drone operators orbiting Mars in a virtual reality environment on board a parabolic flight, where both hyper- and microgravity conditions were induced. From a first-person perspective, participants viewed a drone exiting a cave and had to first predict a collision and then provide a confidence estimate of their response. We evoked uncertainty in the task by manipulating the motion's trajectory angle. Post-decision subjective confidence reports were negatively predicted by stimulus uncertainty, as expected. Uncertainty alone did not impact overt behavioral responses (performance, choice) differentially across gravity conditions. However microgravity predicted higher subjective confidence, especially in interaction with stimulus uncertainty. These results suggest that variables relating to uncertainty affect decision-making distinctly in microgravity, highlighting the possible need for automatized, compensatory mechanisms when considering human factors in space research.
References

HDVIO: Improving Localization and Disturbance Estimation with Hybrid Dynamics VIO
Visual-inertial odometry (VIO) is the most common approach for estimating the state of autonomous micro aerial vehicles using only onboard sensors. Existing methods improve VIO performance by including a dynamics model in the estimation pipeline. However, such methods degrade in the presence of low-fidelity vehicle models and continuous external disturbances, such as wind. Our proposed method, HDVIO, overcomes these limitations by using a hybrid dynamics model that combines a point-mass vehicle model with a learning-based component that captures complex aerodynamic effects. HDVIO estimates the external force and the full robot state by leveraging the discrepancy between the actual motion and the predicted motion of the hybrid dynamics model. Our hybrid dynamics model uses a history of thrust and IMU measurements to predict the vehicle dynamics. To demonstrate the performance of our method, we present results on both public and novel drone dynamics datasets and show real-world experiments of a quadrotor flying in strong winds up to 25 km/h. The results show that our approach improves the motion and external force estimation compared to the state-of-the-art by up to 33% and 40%, respectively. Furthermore, differently from existing methods, we show that it is possible to predict the vehicle dynamics accurately while having no explicit knowledge of its full state.
References
Training Efficient Controllers via Analytic Policy Gradient
Control design for robotic systems is complex and often requires solving an optimization to follow a trajectory accurately. Online optimization approaches like Model Predictive Control (MPC) have been shown to achieve great tracking performance, but require high computing power. Conversely, learning-based offline optimization approaches, such as Reinforcement Learning (RL), allow fast and efficient execution on the robot but hardly match the accuracy of MPC in trajectory tracking tasks. In systems with limited compute, such as aerial vehicles, an accurate controller that is efficient at execution time is imperative. We propose an Analytic Policy Gradient (APG) method to tackle this problem. APG exploits the availability of differentiable simulators by training a controller offline with gradient descent on the tracking error. We address training instabilities that frequently occur with APG through curriculum learning and experiment on a widely used controls benchmark, the CartPole, and two common aerial robots, a quadrotor and a fixed-wing drone. Our proposed method outperforms both model-based and model-free RL methods in terms of tracking error. Concurrently, it achieves similar performance to MPC while requiring more than an order of magnitude less computation time. Our work provides insights into the potential of APG as a promising control method for robotics. To facilitate the exploration of APG, we open-source our code and make it publicly available.
References

Learned Inertial Odometry for Autonomous Drone Racing
Inertial odometry is an attractive solution to the problem of state estimation for agile quadrotor flight. It is inexpensive, lightweight, and it is not affected by perceptual degradation. However, only relying on the integration of the inertial measurements for state estimation is infeasible. The errors and time-varying biases present in such measurements cause the accumulation of large drift in the pose estimates. Recently, inertial odometry has made significant progress in estimating the motion of pedestrians. State-of-the-art algorithms rely on learning a motion prior that is typical of humans but cannot be transferred to drones. In this work, we propose a learning-based odometry algorithm that uses an inertial measurement unit (IMU) as the only sensor modality for autonomous drone racing tasks. The core idea of our system is to couple a model-based filter, driven by the inertial measurements, with a learning-based module that has access to the thrust measurements. We show that our inertial odometry algorithm is superior to the state-of-the-art filter-based and optimization-based visual-inertial odometry as well as the state-of-the-art learned-inertial odometry in estimating the pose of an autonomous racing drone. Additionally, we show that our system is comparable to a visual-inertial odometry solution that uses a camera and exploits the known gate location and appearance. We believe that the application in autonomous drone racing paves the way for novel research in inertial odometry for agile quadrotor flight.
References
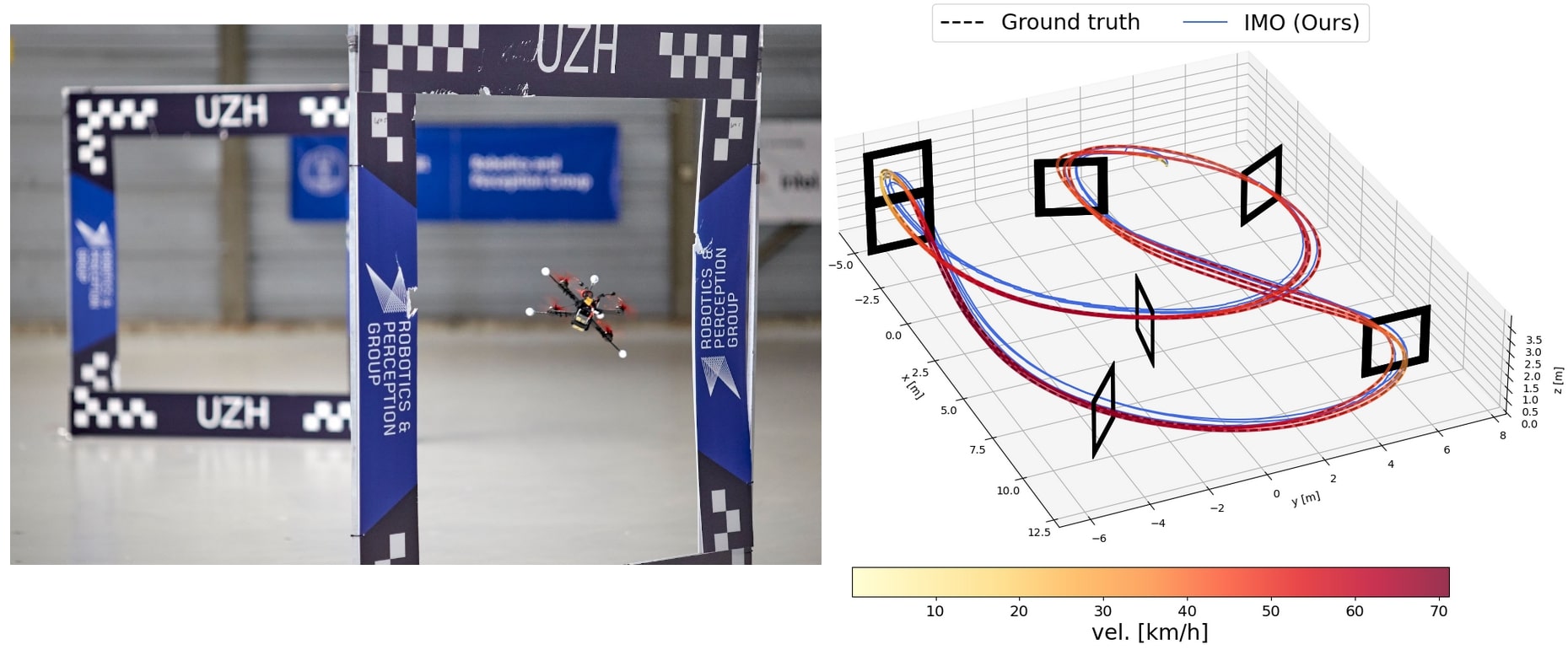
Learned Inertial Odometry for Autonomous Drone Racing
IEEE Robotics and Automation Letters (RA-L), 2023.
Agilicious: Open-Source and Open-Hardware Agile Quadrotor for Vision-Based Flight
We are excited to present Agilicious, a co-designed hardware and software framework tailored to autonomous, agile quadrotor flight. It is completely open-source and open-hardware and supports both model-based and neural-network-based controllers. Also, it provides high thrust-to-weight and torque-to-inertia ratios for agility, onboard vision sensors, GPU-accelerated compute hardware for real-time perception and neural-network inference, a real-time flight controller, and a versatile software stack. In contrast to existing frameworks, Agilicious offers a unique combination of flexible software stack and high-performance hardware. We compare Agilicious with prior works and demonstrate it on different agile tasks, using both modelbased and neural-network-based controllers. Our demonstrators include trajectory tracking at up to 5 g and 70 km/h in a motion-capture system, and vision-based acrobatic flight and obstacle avoidance in both structured and unstructured environments using solely onboard perception. Finally, we demonstrate its use for hardware-in-the-loop simulation in virtual-reality environments. Thanks to its versatility, we believe that Agilicious supports the next generation of scientific and industrial quadrotor research. For more details check our paper, video and webpage.
References

User-Conditioned Neural Control Policies for Mobile Robotics
Recently, learning-based controllers have been shown to push mobile robotic systems to their limits and provide the robustness needed for many real-world applications. However, only classical optimization-based control frameworks offer the inherent flexibility to be dynamically adjusted during execution by, for example, setting target speeds or actuator limits. We present a framework to overcome this shortcoming of neural controllers by conditioning them on an auxiliary input. This advance is enabled by including a feature-wise linear modulation layer (FiLM). We use model-free reinforcement-learning to train quadrotor control policies for the task of navigating through a sequence of waypoints in minimum time. By conditioning the policy on the maximum available thrust or the viewing direction relative to the next waypoint, a user can regulate the aggressiveness of the quadrotor’s flight during deployment. We demonstrate in simulation and in real-world experiments that a single control policy can achieve close to time-optimal flight performance across the entire performance envelope of the robot, reaching up to 60 km/h and 4.5 g in acceleration. The ability to guide a learned controller during task execution has implications beyond agile quadrotor flight, as conditioning the control policy on human intent helps safely bringing learning based systems out of the well-defined laboratory environment into the wild.
References
Weighted Maximum Likelihood for Controller Tuning
Recently, Model Predictive Contouring Control (MPCC) has arisen as the state-of-the-art approach for modelbased agile flight. MPCC benefits from great flexibility in trading-off between progress maximization and path following at runtime without relying on globally optimized trajectories. However, finding the optimal set of tuning parameters for MPCC is challenging because (i) the full quadrotor dynamics are non-linear, (ii) the cost function is highly non-convex, and (iii) of the high dimensionality of the hyperparameter space. This paper leverages a probabilistic Policy Search method, Weighted Maximum Likelihood (WML), to automatically learn the optimal objective for MPCC. WML is sampleefficient due to its closed-form solution for updating the learning parameters. Additionally, the data efficiency provided by the use of a model-based approach allows us to directly train in a high-fidelity simulator, which in turn makes our approach able to transfer zero-shot to the real world. We validate our approach in the real world, where we show that our method outperforms both the previous manually tuned controller and the state-of-the-art auto-tuning baseline reaching speeds of 75 km/h.
References

Learning Perception-Aware Agile Flight in Cluttered Environments
Recently, neural control policies have outperformed existing model-based planning-and-control methods for autonomously navigating quadrotors through cluttered environments in minimum time. However, they are not perception aware, a crucial requirement in vision-based navigation due to the camera's limited field of view and the underactuated nature of a quadrotor. We propose a method to learn neural network policies that achieve perception-aware, minimum-time flight in cluttered environments. Our method combines imitation learning and reinforcement learning (RL) by leveraging a privileged learning-by-cheating framework. Using RL, we first train a perception-aware teacher policy with full-state information to fly in minimum time through cluttered environments. Then, we use imitation learning to distill its knowledge into a vision-based student policy that only perceives the environment via a camera. Our approach tightly couples perception and control, showing a significant advantage in computation speed (10x faster) and success rate. We demonstrate the closed-loop control performance using a physical quadrotor and hardware-in-the-loop simulation at speeds up to 50 km/h.
References

Time-optimal Online Replanning for Agile Quadrotor Flight
In this paper, we tackle the problem of flying a quadrotor using time-optimal control policies that can be replanned online when the environment changes or when encountering unknown disturbances. This problem is challenging as the time-optimal trajectories that consider the full quadrotor dynamics are computationally expensive to generate (order of minutes or even hours). We introduce a sampling-based method for efficient generation of time-optimal paths of a point-mass model. These paths are then tracked using a Model Predictive Contouring Control approach that considers the full quadrotor dynamics and the single rotor thrust limits. Our combined approach is able to run in real-time, being the first time-optimal method that is able to adapt to changes on-the-fly. We showcase our approach's adaption capabilities by flying a quadrotor at more than 60 km/h in a racing track where gates are moving. Additionally, we show that our online replanning approach can cope with strong disturbances caused by winds of up to 68 km/h.
References

Learning Minimum-Time Flight in Cluttered Environments

Planning minimum-time trajectories in cluttered environments with obstacles is a challenging problem. It is even more challenging to track such a trajectory without collisions when flying on the edge of actuation limits using traditional control methods. To this end, we leverage deep reinforcement learning and classical topological path planning to train robust neural-network controllers for minimum-time quadrotor flight in cluttered environments. The learned policy solves the planning and control problem simultaneously online to account for disturbances, thus achieving much higher robustness. The presented method achieves 100% success rate of flying minimum-time policies without collision, while traditional planning and control approaches achieve only 40%. We show the approach in real-world flight with speeds reaching 42 km/h and accelerates up to 3.6g.
References
A Comparative Study of Nonlinear MPC and Differential-Flatness-Based Control for Quadrotor Agile Flight
Accurate trajectory tracking control for quadrotors is essential for safe navigation in cluttered environments. However, this is challenging in agile flights due to nonlinear dynamics, complex aerodynamic effects, and actuation constraints. Our work empirically compares two state-of-the-art control frameworks: the nonlinear-model-predictive controller (NMPC) and the differential-flatness-based controller (DFBC), by tracking a wide variety of agile trajectories at speeds up to 72km/h. The comparisons are performed in both simulation and real-world environments to systematically evaluate both methods from the aspect of tracking accuracy, robustness, and computational efficiency. We show the superiority of NMPC in tracking dynamically infeasible trajectories, at the cost of higher computation time and risk of numerical convergence issues. For both methods, we also quantitatively study the effect of adding an inner-loop controller using the incremental nonlinear dynamic inversion (INDI) method, and the effect of adding an aerodynamic drag model. Our real-world experiments, performed in one of the world's largest motion capture systems, demonstrate more than 78% tracking error reduction of both NMPC and DFBC, indicating the necessity of using an inner-loop controller and aerodynamic drag model for agile trajectory tracking.
References

Model Predictive Contouring Control for Time-Optimal Quadrotor Flight
We tackle the problem of flying time-optimal trajectories through multiple waypoints with quadrotors. State-of-the-art solutions split the problem into a planning task - where a global, time-optimal trajectory is generated - and a control task - where this trajectory is accurately tracked. However, at the current state, generating a time-optimal trajectory that takes the full quadrotor model into account is computationally demanding (in the order of minutes or even hours). This is detrimental for replanning in presence of disturbances. We overcome this issue by solving the time-optimal planning and control problems concurrently via Model Predictive Contouring Control (MPCC). Our MPCC optimally selects the future states of the platform at runtime, while maximizing the progress along the reference path and minimizing the distance to it. We show that, even when tracking simplified trajectories, the proposed MPCC results in a path that approaches the true time-optimal one, and which can be generated in real-time. We validate our approach in the real-world, where we show that our method outperforms both the current state-of-the-art and a world-class human pilot in terms of lap time achieving speeds of up to 60 km/h.
References

Visual Attention Prediction Improves Performance of Autonomous Drone Racing Agents

Humans race drones faster than neural networks trained for end-to-end autonomous flight. This may be related to the ability of human pilots to select task-relevant visual information effectively. This work investigates whether neural networks capable of imitating human eye gaze behavior and attention can improve neural network performance for the challenging task of vision-based autonomous drone racing. We hypothesize that gaze-based attention prediction can be an efficient mechanism for visual information selection and decision making in a simulator-based drone racing task. We test this hypothesis using eye gaze and flight trajectory data from 18 human drone pilots to train a visual attention prediction model. We then use this visual attention prediction model to train an end-to-end controller for vision-based autonomous drone racing using imitation learning. We compare the drone racing performance of the attention-prediction controller to those using raw image inputs and image-based abstractions (i.e., feature tracks). Comparing success rates for completing a challenging race track by autonomous flight, our results show that the attention-prediction based controller (88% success rate) outperforms the RGB-image (61% success rate) and feature-tracks (55% success rate) controller baselines. Furthermore, visual attention-prediction and feature-track based models showed better generalization performance than image-based models when evaluated on hold-out reference trajectories. Our results demonstrate that human visual attention prediction improves the performance of autonomous vision-based drone racing agents and provides an essential step towards vision-based, fast, and agile autonomous flight that eventually can reach and even exceed human performances.
References
Minimum-Time Quadrotor Waypoint Flight in Cluttered Environments
Planning minimum-time trajectories in cluttered environments with obstacles is a challenging problem. The quadrotor has to fly on the edge of its capabilities and, at the same time, avoid obstacles. However, planning such trajectories is vital for applications like search and rescue, where after disasters, it is essential to search for survivors as quickly as possible. Nevertheless, planning minimum-time trajectories in cluttered environments has not been addressed before in its entirety, using the full quadrotor model that can leverage the full actuation of the platform. We address this problem by using a hierarchical, sampling-based method with an incrementally more complex quadrotor model. The proposed method outperforms all related baselines in cluttered environments and is further validated in real-world flights at over 60km/h.
References

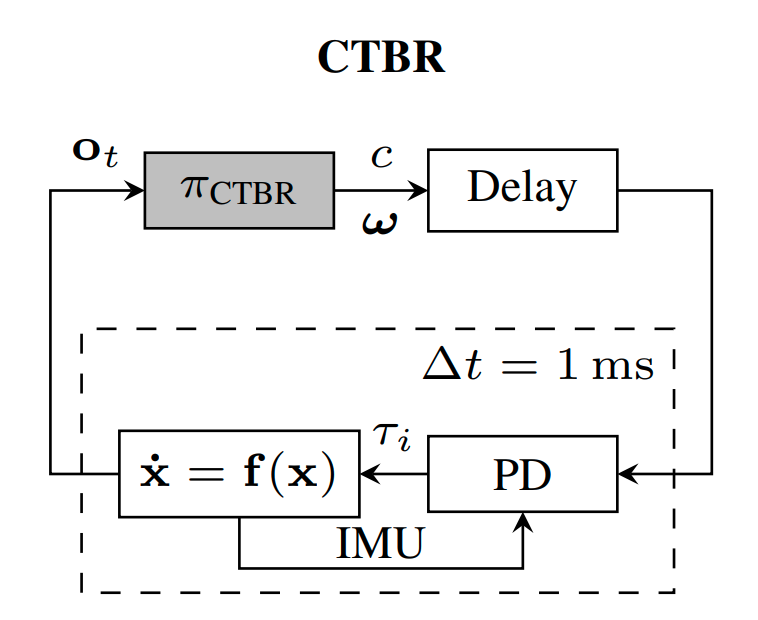
A Benchmark Comparison of Learned Control Policies for Agile Quadrotor Flight
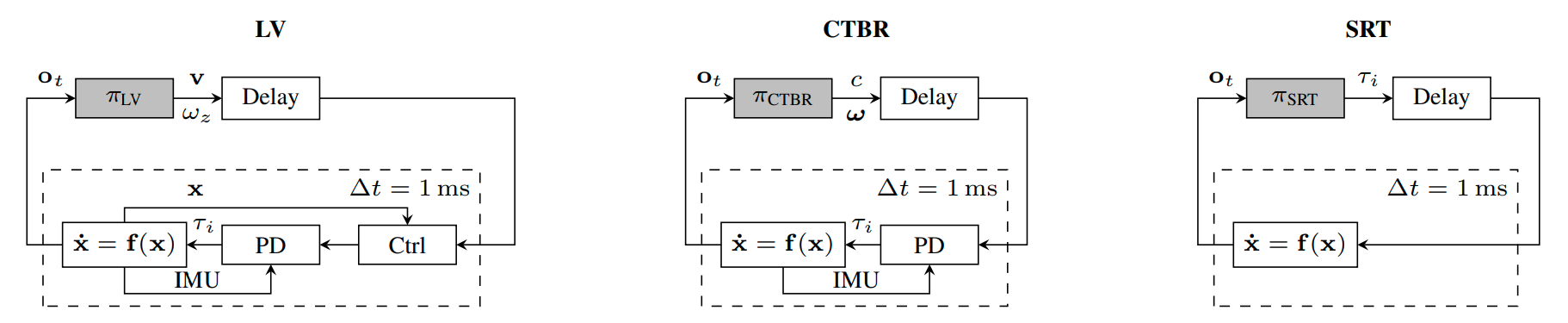
Quadrotors are highly nonlinear dynamical systems that require carefully tuned controllers to be pushed to their physical limits. Recently, learning-based control policies have been proposed for quadrotors, as they would potentially allow learning direct mappings from high-dimensional raw sensory observations to actions. Due to sample inefficiency, training such learned controllers on the real platform is impractical or even impossible. Training in simulation is attractive but requires to transfer policies between domains, which demands trained policies to be robust to such domain gap. In this work, we make two contributions: (i) we perform the first benchmark comparison of existing learned control policies for agile quadrotor flight and show that training a control policy that commands body-rates and thrust results in more robust sim-to-real transfer compared to a policy that directly specifies individual rotor thrusts, (ii) we demonstrate for the first time that such a control policy trained via deep reinforcement learning can control a quadrotor in real-world experiments at speeds over 45km/h.
References
Nonlinear MPC for Quadrotor Fault-Tolerant Control
The mechanical simplicity, hover capabilities, and high agility of quadrotors lead to a fast adaption in the industry for inspection, exploration, and urban aerial mobility. On the other hand, the unstable and underactuated dynamics of quadrotors render them highly susceptible to system faults, especially rotor failures. In this work, we propose a fault-tolerant controller using nonlinear model predictive control (NMPC) to stabilize and control a quadrotor subjected to the complete failure of a single rotor. Differently from existing works, which either rely on linear assumptions or resort to cascaded structures neglecting input constraints in the outer-loop, our method leverages full nonlinear dynamics of the damaged quadrotor and considers the thrust constraint of each rotor. Hence, this method could effectively perform upset recovery from extreme initial conditions. Extensive simulations and real-world experiments are conducted for validation, which demonstrates that the proposed NMPC method can effectively recover the damaged quadrotor even if the failure occurs during aggressive maneuvers, such as flipping and tracking agile trajectories.
References

Nonlinear MPC for Quadrotor Fault-Tolerant Control
Robotics and Automation Letters (RAL), 2022
Perception-Aware Perching on Powerlines with Multirotors
Multirotor aerial robots are becoming widely used for the inspection of powerlines. To enable continuous, robust inspection without human intervention, the robots must be able to perch on the powerlines to recharge their batteries. Highly versatile perching capabilities are necessary to adapt to the variety of configurations and constraints that are present in real powerline systems. This paper presents a novel perching trajectory generation framework that computes perception-aware, collision-free, and dynamically-feasible maneuvers to guide the robot to the desired final state. Trajectory generation is achieved via solving a Nonlinear Programming problem using the Primal-Dual Interior Point method. The problem considers the full dynamic model of the robot down to its single rotor thrusts and minimizes the final pose and velocity errors while avoiding collisions and maximizing the visibility of the powerline during the maneuver. The generated maneuvers consider both the perching and the posterior recovery trajectories. The framework adopts costs and constraints defined by efficient mathematical representations of powerlines, enabling online onboard execution in resource-constrained hardware. The method is validated on-board an agile quadrotor conducting powerline inspection and various perching maneuvers with final pitch values of up to 180 degrees.
References

Policy Search for Model Predictive Control with Application to Agile Drone Flight
Policy Search and Model Predictive Control (MPC) are two different paradigms for robot control: policy search has the strength of automatically learning complex policies using experienced data, while MPC can offer optimal control performance using models and trajectory optimization. An open research question is how to leverage and combine the advantages of both approaches. In this work, we provide an answer by using policy search for automatically choosing high-level decision variables for MPC, which leads to a novel policy-search-for-model-predictive-control framework. Specifically, we formulate the MPC as a parameterized controller, where the hard-to-optimize decision variables are represented as high-level policies. Such a formulation allows optimizing policies in a self-supervised fashion. We validate this framework by focusing on a challenging problem in agile drone flight: flying a quadrotor through fast-moving gates. Experiments show that our controller achieves robust and real-time control performance in both simulation and the real world. The proposed framework offers a new perspective for merging learning and control.
References

Policy Search for Model Predictive Control with Application to Agile Drone Flight
IEEE Transactions on Robotics (T-RO), 2022.
Learning High-Speed Flight in the Wild

Quadrotors are agile. Unlike most other machines, they can traverse extremely complex environments at high speeds. To date, only expert human pilots have been able to fully exploit their capabilities. Autonomous operation with onboard sensing and computation has been limited to low speeds. State-of-the-art methods generally separate the navigation problem into subtasks: sensing, mapping, and planning. While this approach has proven successful at low speeds, the separation it builds upon can be problematic for high-speed navigation in cluttered environments. Indeed, the subtasks are executed sequentially, leading to increased processing latency and a compounding of errors through the pipeline. Here we propose an end-to-end approach that can autonomously fly quadrotors through complex natural and man-made environments at high speeds, with purely onboard sensing and computation. The key principle is to directly map noisy sensory observations to collision-free trajectories in a receding-horizon fashion. This direct mapping drastically reduces processing latency and increases robustness to noisy and incomplete perception. The sensorimotor mapping is performed by a convolutional network that is trained exclusively in simulation via privileged learning: imitating an expert with access to privileged information. By simulating realistic sensor noise, our approach achieves zero-shot transfer from simulation to challenging real-world environments that were never experienced during training: dense forests, snow-covered terrain, derailed trains, and collapsed buildings. Our work demonstrates that end-to-end policies trained in simulation enable high-speed autonomous flight through challenging environments, outperforming traditional obstacle avoidance pipelines. We release the code open source.
References

Learning High-Speed Flight in the Wild
Science Robotics, 2021.
Range, Endurance, and Optimal Speed Estimates for Multicopters
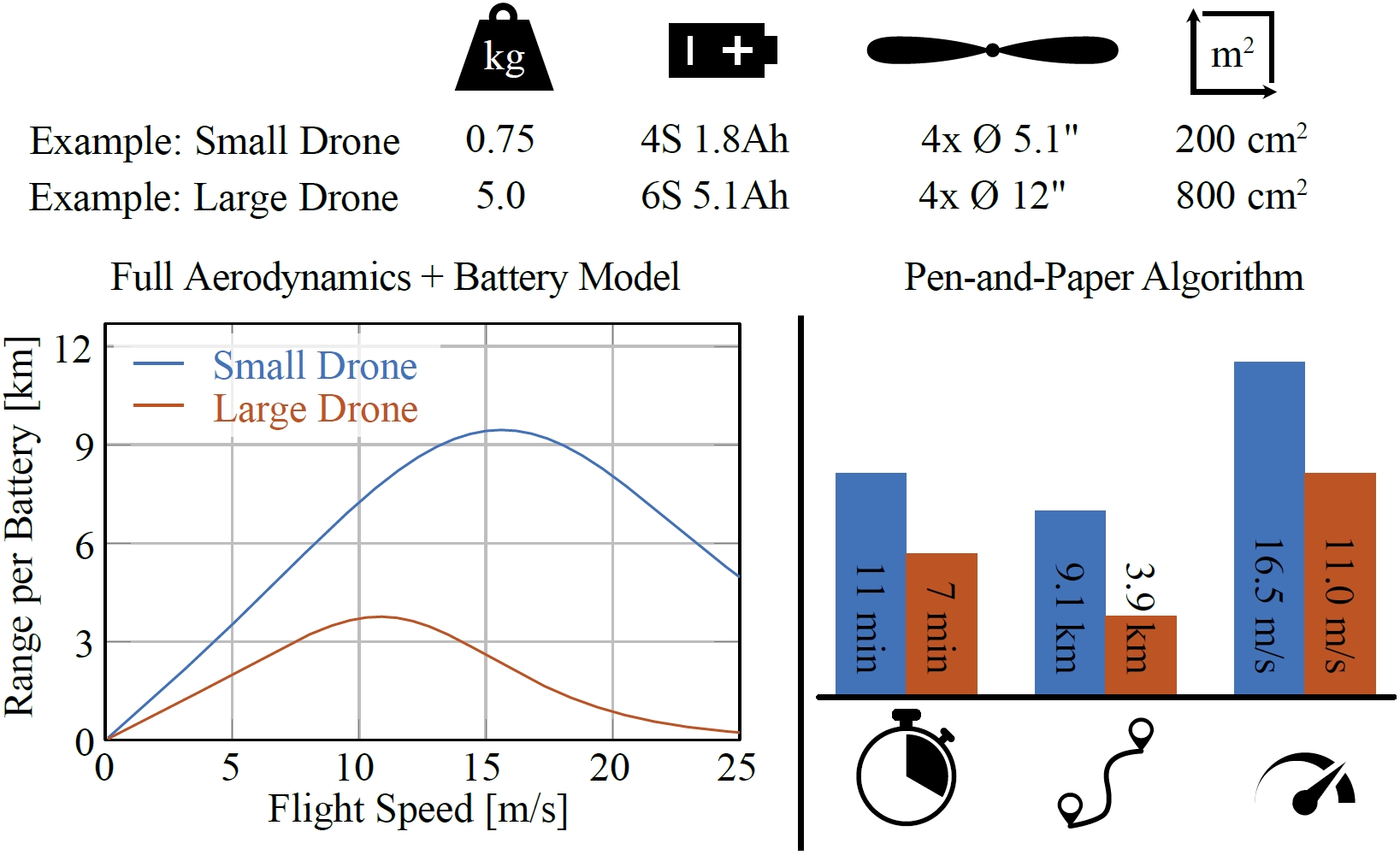
Multicopters are among the most versatile mobile robots. Their applications range from inspection and mapping tasks to providing vital reconnaissance in disaster zones and to package delivery. The range, endurance, and speed a multirotor vehicle can achieve while performing its task is a decisive factor not only for vehicle design and mission planning, but also for policy makers deciding on the rules and regulations for aerial robots. To the best of the authors' knowledge, this work proposes the first approach to estimate the range, endurance, and optimal flight speed for a wide variety of multicopters. This advance is made possible by combining a state-of-the-art first-principles aerodynamic multicopter model based on blade-element-momentum theory with an electric-motor model and a graybox battery model. This model predicts the cell voltage with only 1.3% relative error (43.1 mV), even if the battery is subjected to non-constant discharge rates. Our approach is validated with real-world experiments on a test bench as well as with flights at speeds up to 65 km/h in one of the world's largest motion-capture systems. We also present an accurate pen-and-paper algorithm to estimate the range, endurance and optimal speed of multicopters to help future researchers build drones with maximal range and endurance, ensuring that future multirotor vehicles are even more versatile.
References
Range, Endurance, and Optimal Speed Estimates for Multicopters
Robotics and Automation Letters (RAL), 2022.
Performance, Precision, and Payloads: Adaptive Nonlinear MPC for Quadrotors
Agile quadrotor flight in challenging environments has the potential to revolutionize shipping, transportation, and search and rescue applications. Nonlinear model predictive control (NMPC) has recently shown promising results for agile quadrotor control, but relies on highly accurate models for maximum performance. Hence, model uncertainties in the form of unmodeled complex aerodynamic effects, varying payloads and parameter mismatch will degrade overall system performance. In this paper, we propose L1-NMPC, a novel hybrid adaptive NMPC to learn model uncertainties online and immediately compensate for them, drastically improving performance over the non-adaptive baseline with minimal computational overhead. Our proposed architecture generalizes to many different environments from which we evaluate wind, unknown payloads, and highly agile flight conditions. The proposed method demonstrates immense flexibility and robustness, with more than 90% tracking error reduction over non-adaptive NMPC under large unknown disturbances and without any gain tuning. In addition, the same controller with identical gains can accurately fly highly agile racing trajectories exhibiting top speeds of 70 km/h, offering tracking performance improvements of around 50% relative to the non-adaptive NMPC baseline.
References

Time-Optimal Planning for Quadrotor Waypoint Flight
Quadrotors are among the most agile flying robots. However, planning time-optimal trajectories at the actuation limit through multiple waypoints remains an open problem. This is crucial for applications such as inspection, delivery, search and rescue, and drone racing. Early works used polynomial trajectory formulations, which do not exploit the full actuator potential because of their inherent smoothness. Recent works resorted to numerical optimization but require waypoints to be allocated as costs or constraints at specific discrete times. However, this time allocation is a priori unknown and renders previous works incapable of producing truly time-optimal trajectories. To generate truly time-optimal trajectories, we propose a solution to the time allocation problem while exploiting the full quadrotor’s actuator potential. We achieve this by introducing a formulation of progress along the trajectory, which enables the simultaneous optimization of the time allocation and the trajectory itself. We compare our method against related approaches and validate it in real-world flights in one of the world’s largest motion-capture systems, where we outperform human expert drone pilots in a drone-racing task.
References

NeuroBEM: Hybrid Aerodynamic Quadrotor Model
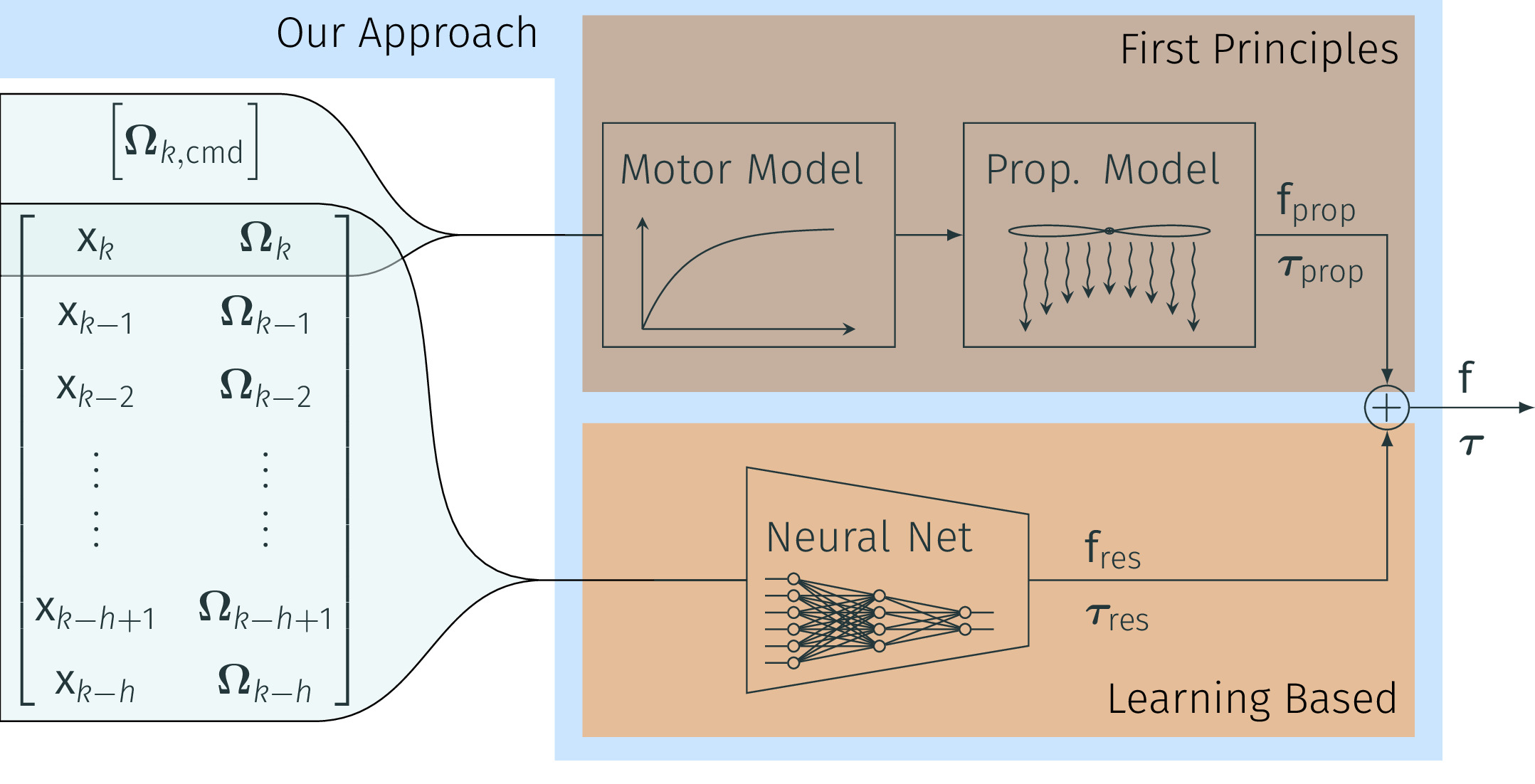
Quadrotors are extremely agile, so much in fact, that classic first-principle-models come to their limits. Aerodynamic effects, while insignificant at low speeds, become the dominant model defect during high speeds or agile maneuvers. Accurate modeling is needed to design robust high-performance control systems and enable flying close to the platform's physical limits. We propose a hybrid approach fusing first principles and learning to model quadrotors and their aerodynamic effects with unprecedented accuracy. First principles fail to capture such aerodynamic effects, rendering traditional approaches inaccurate when used for simulation or controller tuning. Data-driven approaches try to capture aerodynamic effects with blackbox modeling, such as neural networks; however, they struggle to robustly generalize to arbitrary flight conditions. Our hybrid approach unifies and outperforms both first-principles blade-element theory and learned residual dynamics. It is evaluated in one of the world's largest motion-capture systems, using autonomous-quadrotor-flight data at speeds up to 65km/h. The resulting model captures the aerodynamic thrust, torques, and parasitic effects with astonishing accuracy, outperforming existing models with 50% reduced prediction errors, and shows strong generalization capabilities beyond the training set.
References

NeuroBEM: Hybrid Aerodynamic Quadrotor Model
Robotics: Science and Systems (RSS), 2021.
Autonomous Drone Racing with Deep Reinforcement Learning
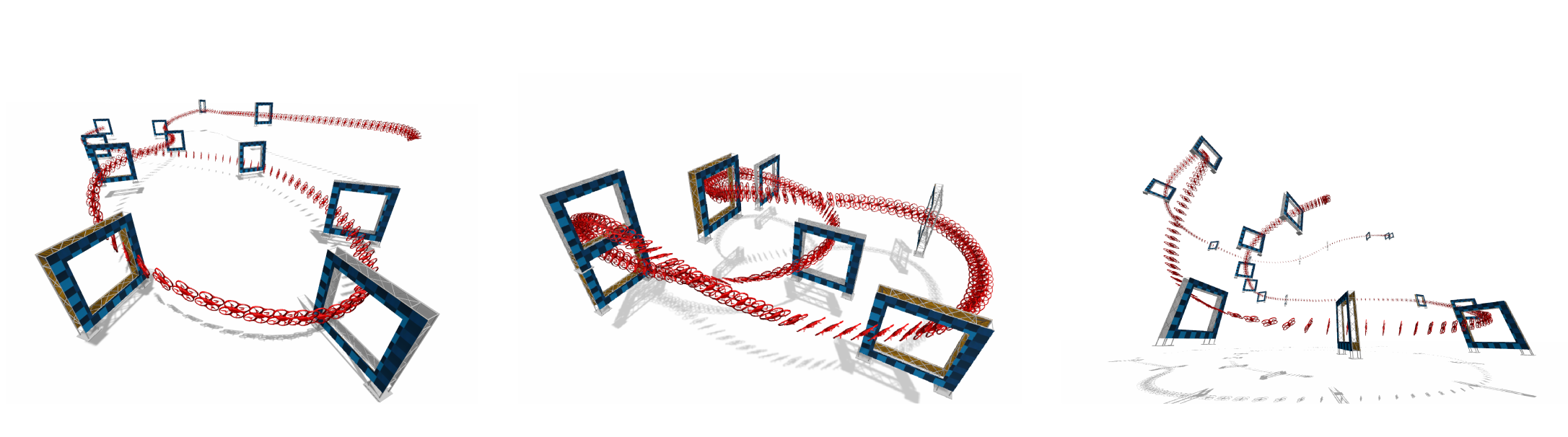
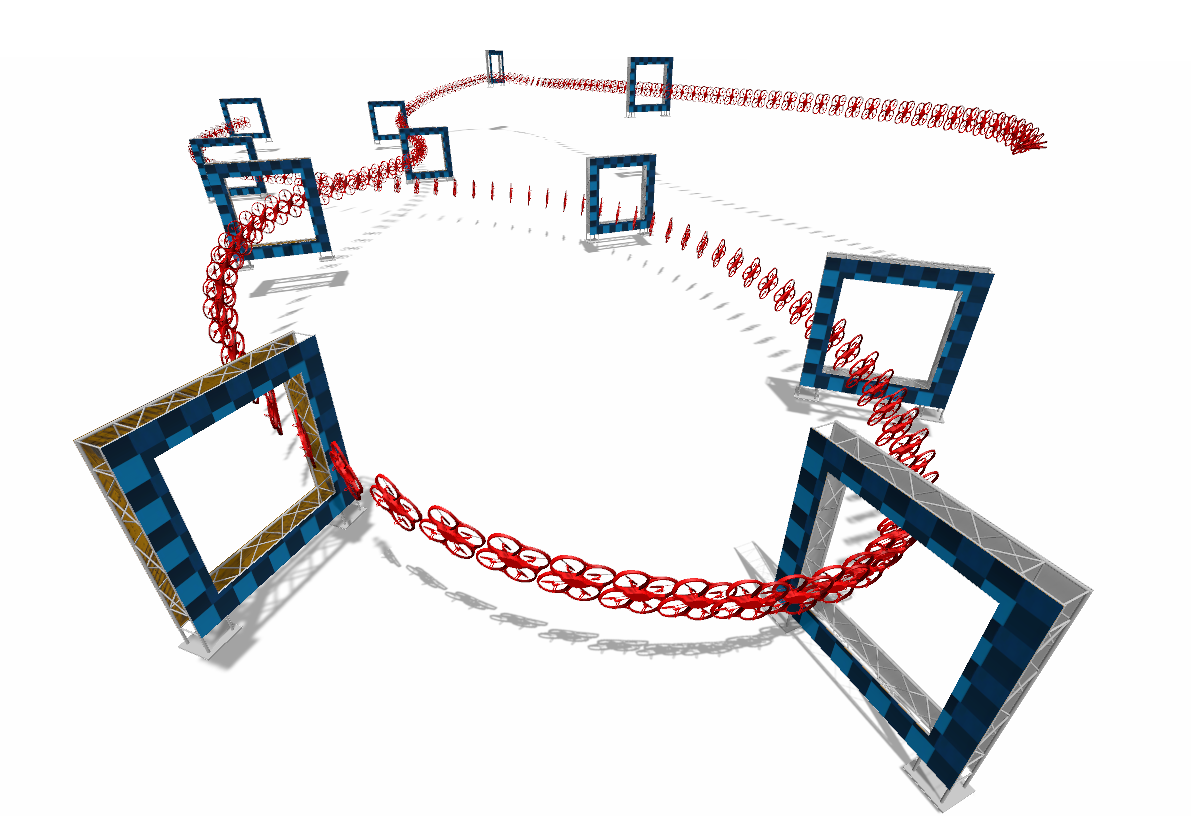
In many robotic tasks, such as drone racing, the goal is to travel through a set of waypoints as fast as possible. A key challenge for this task is planning the minimum-time trajectory, which is typically solved by assuming perfect knowledge of the waypoints to pass in advance. The resulting solutions are either highly specialized for a single-track layout, or suboptimal due to simplifying assumptions about the platform dynamics. In this work, a new approach to minimum-time trajectory generation for quadrotors is presented. Leveraging deep reinforcement learning and relative gate observations, this approach can adaptively compute near-time-optimal trajectories for random track layouts. Our method exhibits a significant computational advantage over approaches based on trajectory optimization for non-trivial track configurations. The proposed approach is evaluated on a set of race tracks in simulation and the real world, achieving speeds of up to 17 m/s with a physical quadrotor.
References
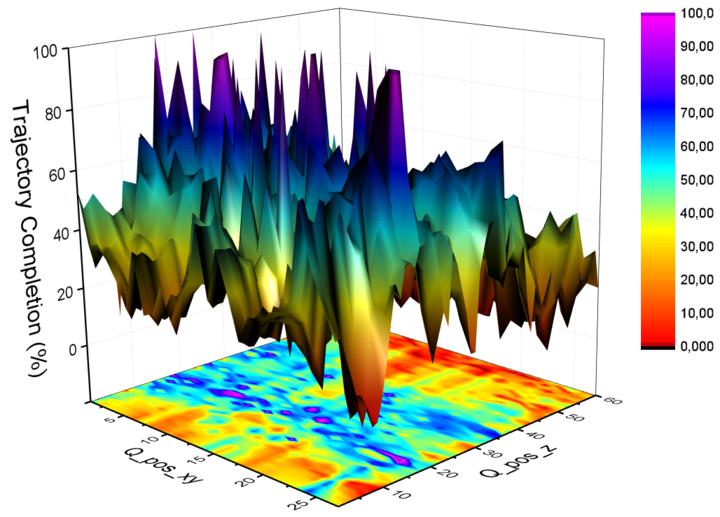
AutoTune: Controller Tuning for High-Speed Flight

Due to noisy actuation and external disturbances, tuning controllers for high-speed flight is very challenging. In this paper, we ask the following questions: How sensitive are controllers to tuning when tracking high-speed maneuvers? What algorithms can we use to automatically tune them? To answer the first question, we study the relationship between parameters and performance and find out that the faster the maneuver, the more sensitive a controller becomes to its parameters. To answer the second question, we review existing methods for controller tuning and discover that prior works often perform poorly on the task of high-speed flight. Therefore, we propose AutoTune, a sampling-based tuning algorithm specifically tailored to high-speed flight. In contrast to previous work, our algorithm does not assume any prior knowledge of the drone or its optimization function and can deal with the multi-modal characteristics of the parameters' optimization space. We thoroughly evaluate AutoTune both in simulation and in the physical world. In our experiments, we outperform existing tuning algorithms by up to 90\% in trajectory completion. The resulting controllers are tested in the AirSim Game of Drones competition, where we outperform the winner by up to 25\% in lap-time. Finally, we show that AutoTune improves tracking error when flying a physical platform with respect to parameters tuned by a human expert.
References
Data-Driven MPC for Quadrotors
Aerodynamic forces render accurate high-speed trajectory tracking with quadrotors extremely challenging. These complex aerodynamic effects become a significant disturbance at high speeds, introducing large positional tracking errors, and are extremely difficult to model. To fly at high speeds, feedback control must be able to account for these aerodynamic effects in real-time. This necessitates a modelling procedure that is both accurate and efficient to evaluate. Therefore, we present an approach to model aerodynamic effects using Gaussian Processes, which we incorporate into a Model Predictive Controller to achieve efficient and precise real-time feedback control, leading to up to 70% reduction in trajectory tracking error at high speeds. We verify our method by extensive comparison to a state-of-the-art linear drag model in synthetic and real-world experiments at speeds of up to 14m/s and accelerations beyond 4g.
References

Flightmare: A Flexible Quadrotor Simulator
Currently available quadrotor simulators have a rigid and highly-specialized structure: either are they really fast, physically accurate, or photo-realistic. In this work, we propose a paradigm-shift in the development of simulators: moving the trade-off between accuracy and speed from the developers to the end-users. We release a new modular quadrotor simulator: Flightmare. Flightmare is composed of two main components: a configurable rendering engine built on Unity and a flexible physics engine for dynamics simulation. Those two components are totally decoupled and can run independently from each other. Flightmare comes with several desirable features: (i) a large multi-modal sensor suite, including an interface to extract the 3D point-cloud of the scene; (ii) an API for reinforcement learning which can simulate hundreds of quadrotors in parallel; and (iii) an integration with a virtual-reality headset for interaction with the simulated environment. Flightmare can be used for various applications, including path-planning, reinforcement learning, visual-inertial odometry, deep learning, human-robot interaction, etc.
References

Flightmare: A Flexible Quadrotor Simulator
Conference on Robot Learning (CoRL), 2020
Deep Drone Acrobatics
Performing acrobatic maneuvers with quadrotors is extremely challenging. Acrobatic flight requires high thrust and extreme angular accelerations that push the platform to its physical limits. Professional drone pilots often measure their level of mastery by flying such maneuvers in competitions. In this paper, we propose to learn a sensorimotor policy that enables an autonomous quadrotor to fly extreme acrobatic maneuvers with only onboard sensing and computation. We train the policy entirely in simulation by leveraging demonstrations from an optimal controller that has access to privileged information. We use appropriate abstractions of the visual input to enable transfer to a real quadrotor. We show that the resulting policy can be directly deployed in the physical world without any fine-tuning on real data. Our methodology has several favorable properties: it does not require a human expert to provide demonstrations, it cannot harm the physical system during training, and it can be used to learn maneuvers that are challenging even for the best human pilots. Our approach enables a physical quadrotor to fly maneuvers such as the Power Loop, the Barrel Roll, and the Matty Flip, during which it incurs accelerations of up to 3g.
References

Deep Drone Acrobatics
Robotics: Science and Systems (RSS), 2020.
AlphaPilot: Autonomous Drone Racing
We present a novel system for autonomous, vision-based drone racing combining learned data abstraction, nonlinear filtering, and time-optimal trajectory planning. The system has successfully been deployed at the first autonomous drone racing world championship: the 2019 AlphaPilot Challenge. Contrary to traditional drone racing systems, that only detect the next gate, our approach makes use of any visible gate and takes advantage of multiple, simultaneous gate detections to compensate for drift in the state estimate and build a global map of the gates. The global map and drift-compensated state estimate allow the drone to navigate through the race course even when the gates are not immediately visible and further enable to plan a near time-optimal path through the race course in real time based on approximate drone dynamics. The proposed system has been demonstrated to successfully guide the drone through tight race courses reaching speeds up to 8m/s and has led to rank second at the 2019 AlphaPilot Challenge.
References

AlphaPilot: Autonomous Drone Racing
Robotics: Science and Systems (RSS), 2020
Best Systems Paper Award!
Towards Low-Latency High-Bandwidth Control of Quadrotors using Event Cameras
Event cameras are a promising candidate to enable high speed vision-based control due to their low sensor latency and high temporal resolution. However, purely event-based feedback has yet to be used in the control of drones. In this work, a first step towards implementing low-latency high-bandwidth control of quadrotors using event cameras is taken. In particular, this paper addresses the problem of one-dimensional attitude tracking using a dualcopter platform equipped with an event camera. The event-based state estimation consists of a modified Hough transform algorithm combined with a Kalman filter that outputs the roll angle and angular velocity of the dualcopter relative to a horizon marked by a black-and-white disk. The estimated state is processed by a proportional-derivative attitude control law that computes the rotor thrusts required to track the desired attitude. The proposed attitude tracking scheme shows promising results of event-camera-driven closed loop control: the state estimator performs with an update rate of 1 kHz and a latency determined to be 12 ms, enabling attitude tracking at speeds of over 1600 degrees per second.
References

Towards Low-Latency High-Bandwidth Control of Quadrotors using Event Cameras
IEEE International Conference on Robotics and Automation (ICRA), 2020
Dynamic Obstacle Avoidance for Quadrotors with Event Cameras
Today's autonomous drones have reaction times of tens of milliseconds, which is not enough for navigating fast in complex dynamic environments. To safely avoid fast moving objects, drones need low-latency sensors and algorithms. We departed from state-of-the-art approaches by using event cameras, which are bioinspired sensors with reaction times of microseconds. Our approach exploits the temporal information contained in the event stream to distinguish between static and dynamic objects and leverages a fast strategy to generate the motor commands necessary to avoid the approaching obstacles. Standard vision algorithms cannot be applied to event cameras because the output of these sensors is not images but a stream of asynchronous events that encode per-pixel intensity changes. Our resulting algorithm has an overall latency of only 3.5 milliseconds, which is sufficient for reliable detection and avoidance of fast-moving obstacles. We demonstrate the effectiveness of our approach on an autonomous quadrotor using only onboard sensing and computation. Our drone was capable of avoiding multiple obstacles of different sizes and shapes, at relative speeds up to 10 meters/second, both indoors and outdoors.
References

Dynamic Obstacle Avoidance for Quadrotors with Event Cameras
Science Robotics, March 18, 2020.
The Role of Latency in High-Speed Sense and Avoid
In this work, we study the effects that perception latency has on the maximum speed a robot can reach to safely navigate through an unknown cluttered environment. We provide a general analysis that can serve as a baseline for future quantitative reasoning for design trade-offs in autonomous robot navigation. We consider the case where the robot is modeled as a linear second-order system with bounded input and navigates through static obstacles. Also, we focus on a scenario where the robot wants to reach a target destination in as little time as possible, and therefore cannot change its longitudinal velocity to avoid obstacles. We show how the maximum latency that the robot can tolerate to guarantee safety is related to the desired speed, the range of its sensing pipeline, and the actuation limitations of the platform (i.e., the maximum acceleration it can produce). As a particular case study, we compare monocular and stereo frame-based cameras against novel, low-latency sensors, such as event cameras, in the case of quadrotor flight. To validate our analysis, we conduct experiments on a quadrotor platform equipped with an event camera to detect and avoid obstacles thrown towards the robot. To the best of our knowledge, this is the first theoretical work in which perception and actuation limitations are jointly considered to study the performance of a robotic platform in high-speed navigation.
References

The UZH-FPV Drone Racing Dataset
Despite impressive results in visual-inertial state estimation in recent years, high speed trajectories with six degree of freedom motion remain challenging for existing estimation algorithms. Aggressive trajectories feature large accelerations and rapid rotational motions, and when they pass close to objects in the environment, this induces large apparent motions in the vision sensors, all of which increase the difficulty in estimation. Existing benchmark datasets do not address these types of trajectories, instead focusing on slow speed or constrained trajectories, targeting other tasks such as inspection or driving.
We introduce the UZH-FPV Drone Racing dataset, consisting of over 27 sequences, with more than 10 km of flight distance, captured on a first-person-view (FPV) racing quadrotor flown by an expert pilot. The dataset features camera images, inertial measurements, event-camera data, and precise ground truth poses. These sequences are faster and more challenging, in terms of apparent scene motion, than any existing dataset. Our goal is to enable advancement of the state of the art in aggressive motion estimation by providing a dataset that is beyond the capabilities of existing state estimation algorithms.

Are We Ready for Autonomous Drone Racing? The UZH-FPV Drone Racing Dataset
IEEE International Conference on Robotics and Automation (ICRA), 2019.
Accurate Tracking of High-Speed Trajectories
In this work, we prove that the dynamical model of a quadrotor subject to linear rotor drag effects is differentially flat in its position and heading. We use this property to compute feed-forward control terms directly from a reference trajectory to be tracked. The obtained feed-forward terms are then used in a cascaded, nonlinear feedback control law that enables accurate agile flight with quadrotors. Compared to state-of-the-art control methods, which treat the rotor drag as an unknown disturbance, our method reduces the trajectory tracking error significantly. Finally, we present a method based on a gradient-free optimization to identify the rotor drag coefficients, which are required to compute the feed-forward control terms. The new theoretical results are thoroughly validated trough extensive comparative experiments.
Quadrotors are well suited for executing fast maneuvers with high accelerations but they are still unable to follow a fast trajectory with centimeter accuracy without iteratively learning it beforehand. In this work, we present a novel body-rate controller and an iterative thrust-mixing scheme, which improve the trajectory-tracking performance without requiring learning and reduce the yaw control error of a quadrotor, respectively. Furthermore, to the best of our knowledge, we present the first algorithm to cope with motor saturations smartly by prioritizing control inputs which are relevant for stabilization and trajectory tracking. The presented body-rate controller uses LQR-control methods to consider both the body rate and the single motor dynamics, which reduces the overall trajectory-tracking error while still rejecting external disturbances well. Our iterative thrust-mixing scheme computes the four rotor thrusts given the inputs from a position-control pipeline. Through the iterative computation, we are able to consider a varying ratio of thrust and drag torque of a single propeller over its input range, which allows applying the desired yaw torque more precisely and hence reduces the yaw-control error. Our prioritizing motor-saturation scheme improves stability and robustness of a quadrotor's flight and may prevent unstable behavior in case of motor saturations. We demonstrate the improved trajectory tracking, yaw-control, and robustness in case of motor saturations in real-world experiments with a quadrotor.

Differential Flatness of Quadrotor Dynamics Subject to Rotor Drag for Accurate Tracking of High-Speed Trajectories
IEEE Robotics and Automation Letters (RA-L), 2018.

Optimal and Perception Aware Control

Optimal control and model-based predictive control are extremely powerful methods to control systems or vehicles. However, most control approaches for MAVs use simple PID control in a cascaded structure and strictly split estimation, planning, and control into separate problems. With optimal control methods one could not only simplify the control architecture, task description, interfacing, and usability, but also take into account dynamic perception objectives and solve planning and control in one single step. Our control architectures abstract the underlying model and provide optimal control and receding horizon predictions at real-time with computation on low-power ARM processors. We also investigate the advantages of perception-aware control, where the robot's perception restrictions are taken into account in the control and planning stage and are used to improve perception performance. While such control pipelines are great for systems with known and simple dynamics, recent advances in machine learning (especially deep neural networks) have shown superior performance in very difficult high-level tasks and high-dimensional data processing. We strongly belief that both model-based and learning-based approaches should work as a union to fully exploit the advantages of both worlds. We intend to provide strong controllers as the foundation for neural-network-based high-level control and sensor data abstraction.

PAMPC: Perception-Aware Model Predictive Control for Quadrotors
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, 2018.

Onboard State Dependent LQR for Agile Quadrotors
IEEE International Conference on Robotics and Automation (ICRA), 2018

Agile Drone Flight through Narrow Gaps with Onboard Sensing and Computing
References

In this work, we address one of the main challenges towards autonomous drone flight in complex environments, which is flight through narrow gaps. Indeed, one day micro drones will be used to search and rescue people in the aftermath of an earthquake. In these situations, collapsed buildings cannot be accessed through conventional windows, so that small gaps may be the only way to get inside. What makes this problem challenging is that a gap can be very small, such that precise trajectory-following is required, and can have arbitrary orientations, such that the quadrotor cannot fly through it in near-hover conditions. This makes it necessary to execute an agile trajectory (i.e., with high velocity and angular accelerations) in order to align the vehicle to the gap orientation. Previous works on aggressive flight through narrow gaps have focused solely on the control and planning problem and therefore used motion-capture systems for state estimation and external computing. Conversely, we focus on using only onboard sensors and computing. More specifically, we address the case where state estimation is done via gap detection through a single, forward-facing camera and show that this raises an interesting problem of coupled perception and planning: for the robot to localize with respect to the gap, a trajectory should be selected, which guarantees that the quadrotor always faces the gap (perception constraint) and should be replanned multiple times during its execution to cope with the varying uncertainty of the state estimate. Furthermore, during the traverse, the quadrotor should maximize the distance from the edges of the gap (geometric constraint) to avoid collisions and, at the same time, it should be able to do so without relying on any visual feedback (when the robot is very close to the gap, this exits from the camera field of view). Finally, the trajectory should be feasible with respect to the dynamic constraints of the vehicle. Our proposed trajectory generation approach is independent of the gap-detection algorithm being used; thus, to simplify the perception task, we used a gap with a simple black-and-white rectangular pattern. We successfully evaluated our approach with gap orientations of up to 45 degrees vertically and up to 30 horizontally. Our vehicle weighs 830 grams and has a thrust-to-weight ratio of 2.5. Our trajectory generation formulation handles trajectories up to 90-degree gap orientations although the quadrotor used in these experiments is too heavy and the motors saturate for more than 45-degree gap orientations. The vehicle reaches speeds of up to 3 meters per second and angular velocities of up to 400 degrees per second, with accelerations of up to 1.5 g. We can pass through gaps 1.5 times the size of the quadrotor, with only 10 centimeters of tolerance. Our method does not require any prior knowledge about the position and the orientation of the gap. No external infrastructure, such as a motion-capture system, is needed. This is the first time that such an aggressive maneuver through narrow gaps has been done by fusing gap detection from a single onboard camera and IMU.
We challenged two Swiss drone-racing pilots to demonstrate FPV flight through narrow gaps. It turned out not to be that easy.. but after some a few attempts they managed quite well!
Automatic Re-Initialization and Failure Recovery
High-resolution photos can be found here.
With drones becoming more and more popular, safety is a big concern. A critical situation occurs when a drone temporarily loses its GPS position information, which might lead it to crash. This can happen, for instance, when flying close to buildings where GPS signal is lost. In such situations, it is desirable that the drone can rely on fall-back systems and regain stable flight as soon as possible. We developped a new technology to automatically recover and stabilize a quadrotor from any initial condition. On the one hand, this new technology can allow a quadrotor to be launched by simply tossing it in the air, like a "baseball". On the other hand, it allows a quadrotor to recover back into stable flight after a system failure. Since this technology does not rely on any external infrastructure, such as GPS, it enables the safe use of drones in both indoors and outdoors environments. Thus, our new technology can become relevant for commercial use of drones, such as parcel delivery. Our quadrotor is equipped with a single camera, an inertial measurement unit, and a distance sensor (Teraranger One). The stabilization system of the quadrotor emulates the visual system and the sense of balance within humans. As soon as a toss or a failure situation is detected, our computer-vision software analyses the images looking for distinctive landmarks in the environment, which it uses to restore balance. All the image processing and control runs on a smartphone processor onboard the drone. The onboard sensing and computation renders the drone safe and able to fly unaided. This allows the drone to fulfil its mission without any communication or interaction with the operator. The recovery procedure consists of multiple stages, in which the quadrotor, first, stabilizes its attitude and altitude, then, re-initializes its visual state-estimation pipeline before stabilizing fully autonomously. To experimentally demonstrate the performance of our system, in the video we aggressively throw the quadrotor in the air by hand and have it recover and stabilize all by itself. We chose this example as it simulates conditions similar to failure recovery during aggressive flight. Our system was able to recover successfully in several hundred throws in both indoor and outdoor environments.
References

Automatic Re-Initialization and Failure Recovery for Aggressive Flight with a Monocular Vision-Based Quadrotor
IEEE International Conference on Robotics and Automation (ICRA), Seattle, 2015.