



Visual and Inertial Odometry and SLAM
Metric 6 degree of freedom state estimation is possible with a single camera and an inertial measurement unit. Using only a monocular vision sensor, the trajectory of the camera can be recovered, up to a scale factor, using visual odometry. We investigate algorithms for visual and visual-inertial odometry, as well as methods to improve the performance of existing VO and VIO pipelines.
HDVIO2.0: Wind and Disturbance Estimation with Hybrid Dynamics VIO

Visual-inertial odometry (VIO) is widely used for state estimation in autonomous micro aerial vehicles using onboard sensors. Current methods improve VIO by incorporating a model of the translational vehicle dynamics, yet their performance degrades when faced with low-accuracy vehicle models or continuous external disturbances, like wind. Additionally, incorporating rotational dynamics in these models is computationally intractable when they are deployed in online applications, e.g., in a closed-loop control system. We present HDVIO2.0, which models full 6-DoF, translational and rotational, vehicle dynamics and tightly incorporates them into a VIO with minimal impact on the runtime. HDVIO2.0 builds upon the previous work, HDVIO, and addresses these challenges through a hybrid dynamics model combining a point-mass vehicle model with a learning-based component, with access to control commands and IMU history, to capture complex aerodynamic effects. The key idea behind modeling the rotational dynamics is to represent them with continuous-time functions. HDVIO2.0 leverages the divergence between the actual motion and the predicted motion from the hybrid dynamics model to estimate external forces as well as the robot state. Our system surpasses the performance of state-of-the-art methods in experiments using public and new drone dynamics datasets, as well as real-world flights in winds up to 25 km/h. Unlike existing approaches, we also show that accurate vehicle dynamics predictions are achievable without precise knowledge of the full vehicle state.
References
FaVoR: Features via Voxel Rendering for Camera Relocalization
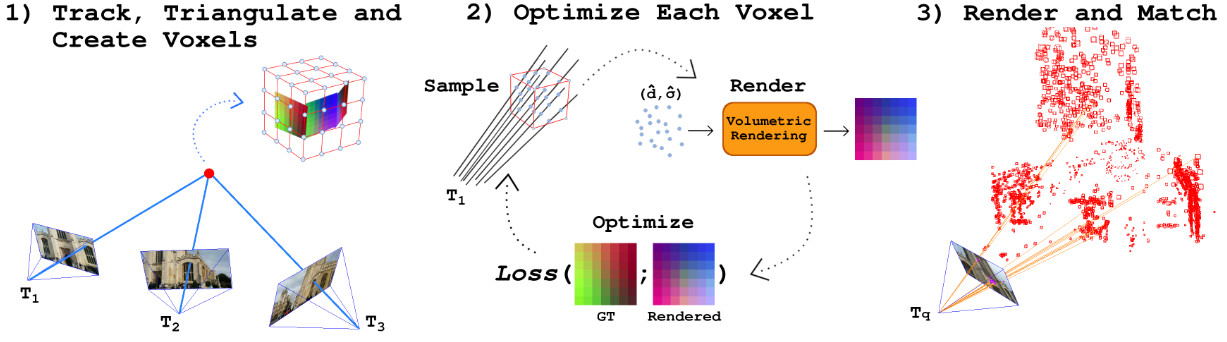
Camera relocalization methods range from dense image alignment to direct camera pose regression from a query image. Among these, sparse feature matching stands out as an efficient, versatile, and generally lightweight approach with numerous applications. However, feature-based methods often struggle with significant viewpoint and appearance changes, leading to matching failures and inaccurate pose estimates. To overcome this limitation, we propose a novel approach that leverages a globally sparse yet locally dense 3D representation of 2D features. By tracking and triangulating landmarks over a sequence of frames, we construct a sparse voxel map optimized to render image patch descriptors observed during tracking. Given an initial pose estimate, we first synthesize descriptors from the voxels using volumetric rendering and then perform feature matching to estimate the camera pose. This methodology enables the generation of descriptors for unseen views, enhancing robustness to view changes. We extensively evaluate our method on the 7-Scenes and Cambridge Landmarks datasets. Our results show that our method significantly outperforms existing state-of-the-art feature representation techniques in indoor environments, achieving up to a 39% improvement in median translation error. Additionally, our approach yields comparable results to other methods for outdoor scenarios while maintaining lower memory and computational costs.
References
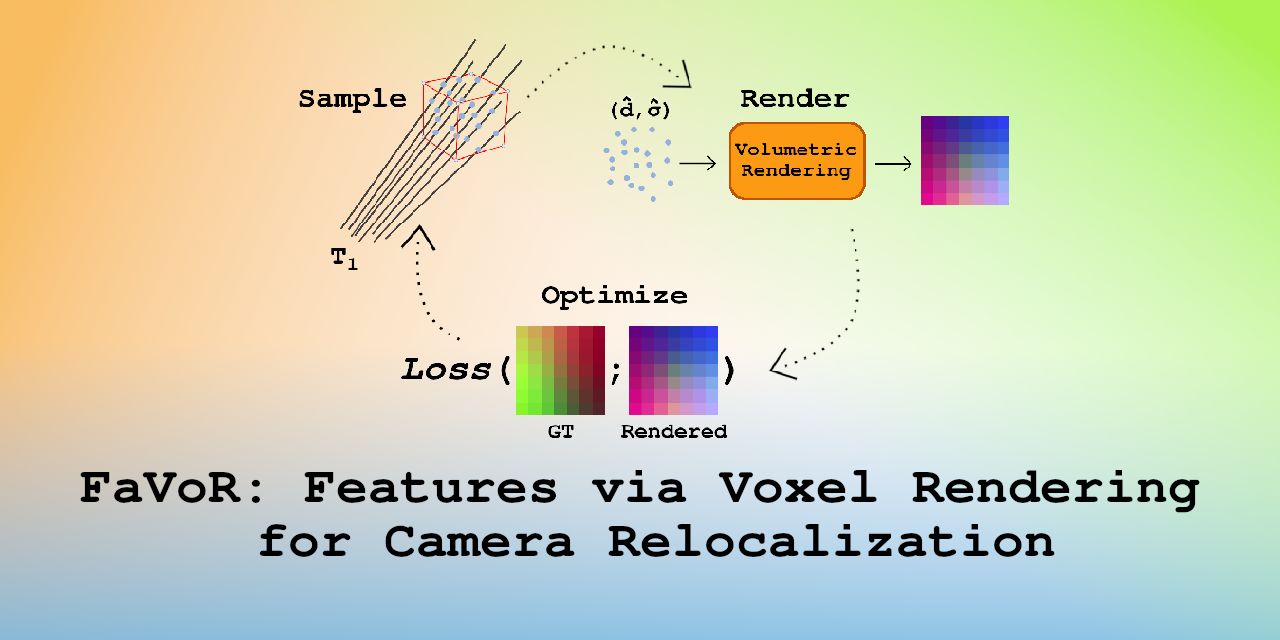
FaVoR: Features via Voxel Rendering for Camera Relocalization
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, Arizona, 2025.
Drift-free Visual SLAM using Digital Twins
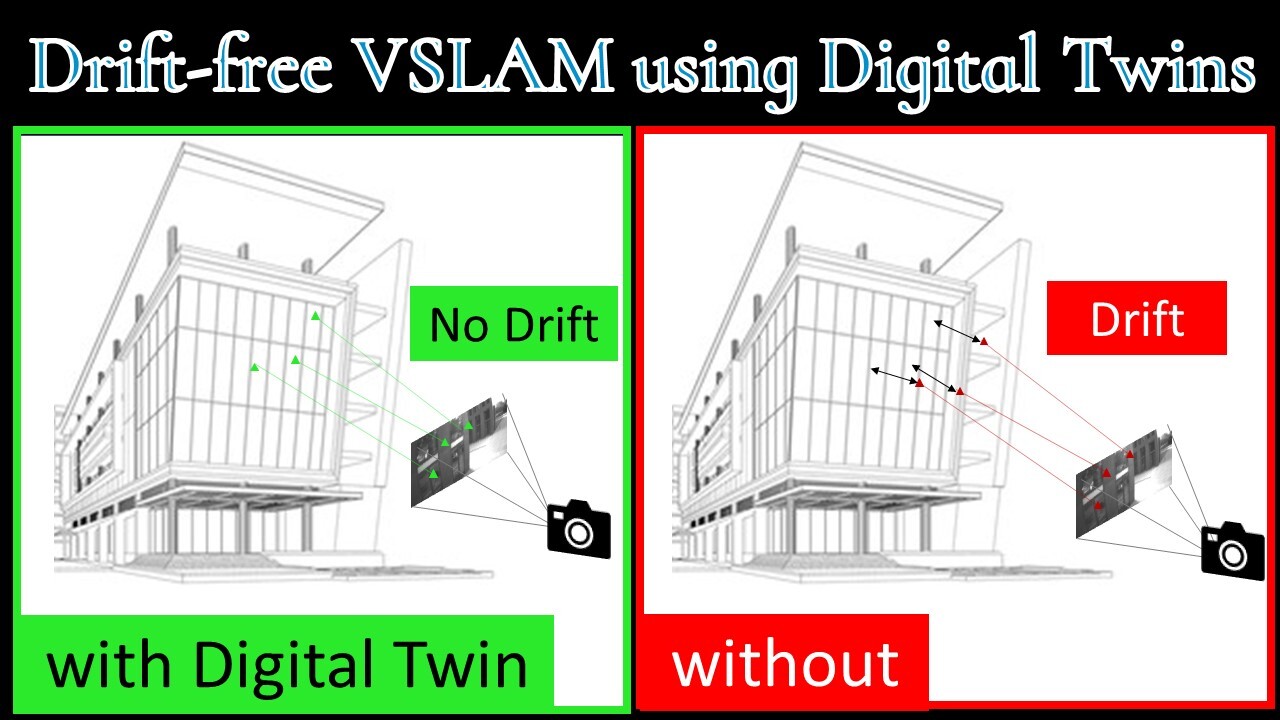
Globally-consistent localization in urban environments is crucial for autonomous systems such as self-driving vehicles and drones, as well as assistive technologies for visually impaired people. Traditional Visual-Inertial Odometry (VIO) and Visual Simultaneous Localization and Mapping (VSLAM) methods, though adequate for local pose estimation, suffer from drift in the long term due to reliance on local sensor data. While GPS counteracts this drift, it is unavailable indoors and often unreliable in urban areas. An alternative is to localize the camera to an existing 3D map using visual-feature matching. This can provide centimeter-level accurate localization but is limited by the visual similarities between the current view and the map. This paper introduces a novel approach that achieves accurate and globally-consistent localization by aligning the sparse 3D point cloud generated by the VIO/VSLAM system to a digital twin using point-to-plane matching; no visual data association is needed. The proposed method provides a 6-DoF global measurement tightly integrated into the VIO/VSLAM system. Experiments run on a high-fidelity GPS simulator and real-world data collected from a drone demonstrate that our approach outperforms state-of-the-art VIO-GPS systems and offers superior robustness against viewpoint changes compared to the state-of-the-art Visual SLAM systems.
References
Sight Guide: Vision Assistance for Blind People - Cybathlon 2024
Our team, Sight Guide, competed in the Vision Assistance Race at the CYBATHLON 2024 - the "cyber Olympics" designed to push the boundaries of assistive technology. In this race, our system guided a blind participant through everyday tasks such as walking along a sidewalk, sorting colors, ordering from a touchscreen, purchasing a box of tea, and navigating a forest—all powered by computer vision assistance! We used two RGB cameras and a depth camera for localization and 3D mapping and semantic understanding, and a belt for haptic feedback. Our system received the Jury Award for the most innovative and user-friendly solution. Check out our project page. This project is the result of the joint collaboration among the University of Zurich (UZH), ETH Zurich (ETH), and the Zurich University of Applied Sciences (ZHAW).
SLAM for Visually Impaired People: A Survey

In recent decades, several assistive technologies have been developed to improve the ability of blind and visually impaired (BVI) individuals to navigate independently and safely. At the same time, simultaneous localization and mapping (SLAM) techniques have become sufficiently robust and efficient to be adopted in developing these assistive technologies. We present the first systematic literature review of 54 recent studies on SLAM-based solutions for blind and visually impaired people, focusing on literature published from 2017 onward. This review explores various localization and mapping techniques employed in this context. We systematically identified and categorized diverse SLAM approaches and analyzed their localization and mapping techniques, sensor types, computing resources, and machine-learning methods. We discuss the advantages and limitations of these techniques for blind and visually impaired navigation. Moreover, we examine the major challenges described across studies, including practical challenges and considerations that affect usability and adoption. Our analysis also evaluates the effectiveness of these SLAM-based solutions in real-world scenarios and user satisfaction, providing insights into their practical impact on BVI mobility. The insights derived from this review identify critical gaps and opportunities for future research activities, particularly in addressing the challenges presented by dynamic and complex environments. We explain how SLAM technology offers the potential to improve the ability of visually impaired individuals to navigate effectively. Finally, we present future opportunities and challenges in this domain.
References
Hilti SLAM Challenge 2023: Benchmarking Single + Multi-session SLAM across Sensor Constellations in Construction

Simultaneous Localization and Mapping systems are a key enabler for positioning in both handheld and robotic applications. The Hilti SLAM Challenges organized over the past years have been successful at benchmarking some of the world's best SLAM Systems with high accuracy. However, more capabilities of these systems are yet to be explored, such as platform agnosticism across varying sensor suites and multi-session SLAM. These factors indirectly serve as an indicator of robustness and ease of deployment in real-world applications. There exists no dataset plus benchmark combination publicly available, which considers these factors combined. The Hilti SLAM Challenge 2023 Dataset and Benchmark addresses this issue. Additionally, we propose a novel fiducial marker design for a pre- surveyed point on the ground to be observable from an off-the-shelf LiDAR mounted on a robot, and an algorithm to estimate its position at mm-level accuracy. Results from the challenge show an increase in overall participation, single-session SLAM systems getting increasingly accurate, successfully operating across varying sensor suites, but relatively few participants performing multi-session SLAM.
References
Deep Visual Odometry with Events and Frames
Visual Odometry (VO) is crucial for autonomous robotic navigation, especially in GPS-denied environments like planetary terrains. To improve robustness, recent model-based VO systems have begun combining standard and event-based cameras. While event cameras excel in low-light and high-speed motion, standard cameras provide dense and easier-to-track features. However, the field of image- and event-based VO still predominantly relies on model-based methods and is yet to fully integrate recent image-only advancements leveraging end-to-end learning-based architectures. Seamlessly integrating the two modalities remains challenging due to their different nature, one asynchronous, the other not, limiting the potential for a more effective image- and event-based VO. We introduce RAMP-VO, the first end-to-end learned image- and event-based VO system. It leverages novel Recurrent, Asynchronous, and Massively Parallel (RAMP) encoders capable of fusing asynchronous events with image data, providing 8x faster inference and 33% more accurate predictions than existing solutions. Despite being trained only in simulation, RAMP-VO outperforms previous methods on the newly introduced Apollo and Malapert datasets, and on existing benchmarks, where it improves image- and event-based methods by 58.8% and 30.6%, paving the way for robust and asynchronous VO in space.
References
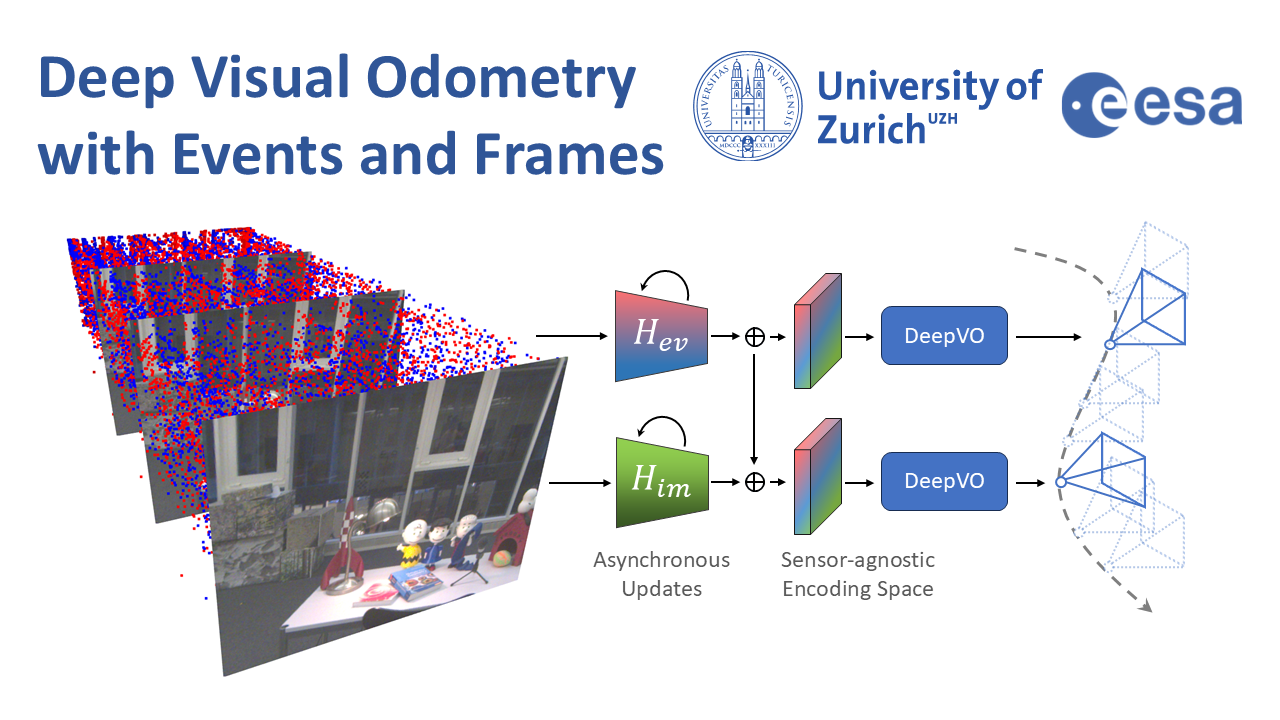
Deep Visual Odometry with Events and Frames
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024.
Structure-Invariant Range-Visual-Inertial Odometry
The Mars Science Helicopter (MSH) mission aims to deploy the next generation of unmanned helicopters on Mars, targeting landing sites in highly irregular terrain such as Valles Marineris, the largest canyons in the Solar system with elevation variances of up to 8000 meters. Unlike its predecessor, the Mars 2020 mission, which relied on a state estimation system assuming planar terrain, MSH requires a novel approach due to the complex topography of the landing site. This paper introduces a novel range-visual-inertial odometry system tailored for the unique challenges of the MSH mission. Our system extends the state-of-the-art xVIO framework by fusing consistent range information with visual and inertial measurements, preventing metric scale drift in the absence of visual-inertial excitation (mono camera and constant velocity descent), and enabling landing on any terrain structure, without requiring any planar terrain assumption. Through extensive testing in image-based simulations using actual terrain structure and textures collected in Mars orbit, we demonstrate that our range-VIO approach estimates terrain-relative velocity meeting the stringent mission requirements, and outperforming existing methods.
References
Reinforcement Learning Meets Visual Odometry
Visual Odometry (VO) is essential to downstream mobile robotics and augmented/virtual reality tasks. Despite recent advances, existing VO methods still rely on heuristic design choices that require several weeks of hyperparameter tuning by human experts, hindering generalizability and robustness. We address these challenges by reframing VO as a sequential decision-making task and applying Reinforcement Learning (RL) to adapt the VO process dynamically. Our approach introduces a neural network, operating as an agent within the VO pipeline, to make decisions such as keyframe and grid-size selection based on real-time conditions. Our method minimizes reliance on heuristic choices using a reward function based on pose error, runtime, and other metrics to guide the system. Our RL framework treats the VO system and the image sequence as an environment, with the agent receiving observations from keypoints, map statistics, and prior poses. Experimental results using classical VO methods and public benchmarks demonstrate improvements in accuracy and robustness, validating the generalizability of our RL-enhanced VO approach to different scenarios. We believe this paradigm shift advances VO technology by eliminating the need for time-intensive parameter tuning of heuristics.
References

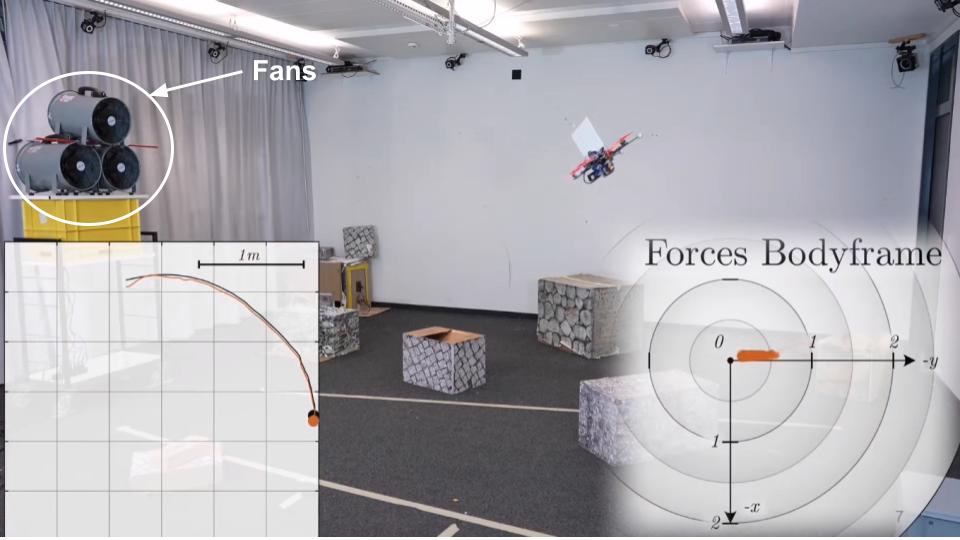
HDVIO: Improving Localization and Disturbance Estimation with Hybrid Dynamics VIO
Visual-inertial odometry (VIO) is the most common approach for estimating the state of autonomous micro aerial vehicles using only onboard sensors. Existing methods improve VIO performance by including a dynamics model in the estimation pipeline. However, such methods degrade in the presence of low-fidelity vehicle models and continuous external disturbances, such as wind. Our proposed method, HDVIO, overcomes these limitations by using a hybrid dynamics model that combines a point-mass vehicle model with a learning-based component that captures complex aerodynamic effects. HDVIO estimates the external force and the full robot state by leveraging the discrepancy between the actual motion and the predicted motion of the hybrid dynamics model. Our hybrid dynamics model uses a history of thrust and IMU measurements to predict the vehicle dynamics. To demonstrate the performance of our method, we present results on both public and novel drone dynamics datasets and show real-world experiments of a quadrotor flying in strong winds up to 25 km/h. The results show that our approach improves the motion and external force estimation compared to the state-of-the-art by up to 33% and 40%, respectively. Furthermore, differently from existing methods, we show that it is possible to predict the vehicle dynamics accurately while having no explicit knowledge of its full state.
References
E-NeRF: Neural Radiance Fields from a Moving Event Camera
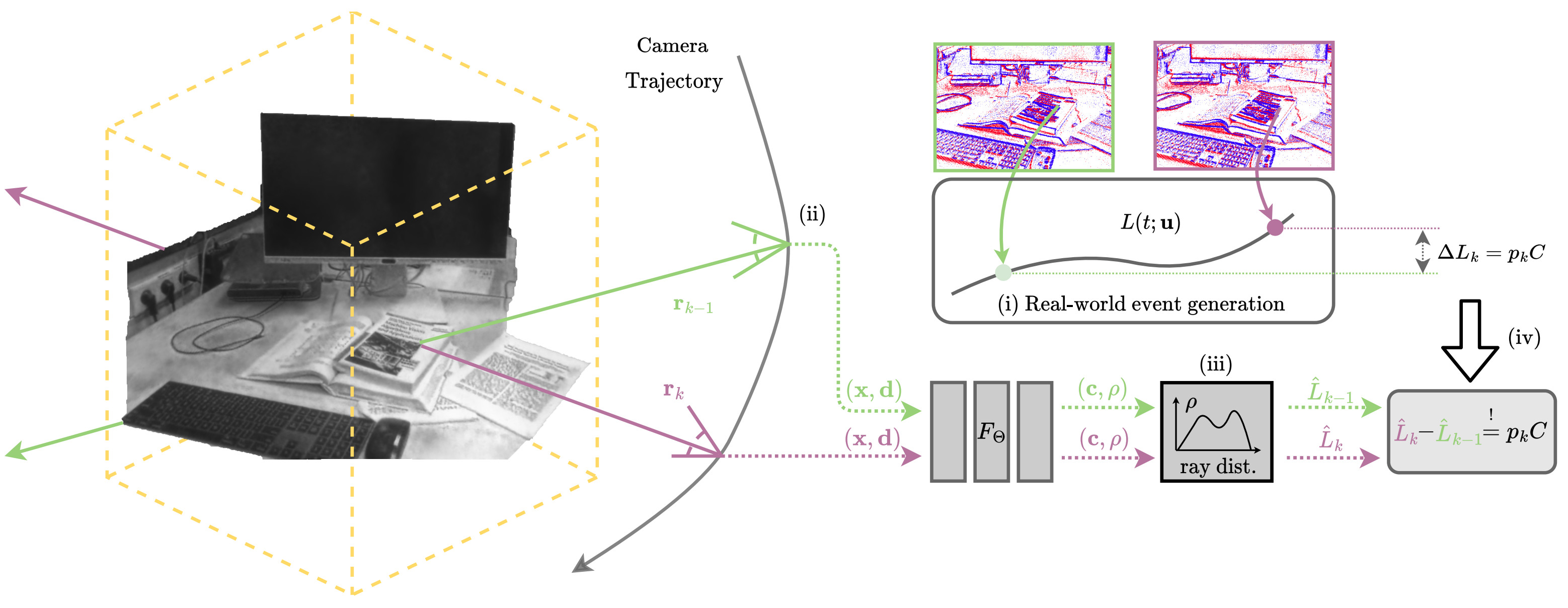
Estimating neural radiance fields (NeRFs) from "ideal" images has been extensively studied in the computer vision community. Most approaches assume optimal illumination and slow camera motion. These assumptions are often violated in robotic applications, where images may contain motion blur, and the scene may not have suitable illumination. This can cause significant problems for downstream tasks such as navigation, inspection, or visualization of the scene. To alleviate these problems, we present E-NeRF, the first method which estimates a volumetric scene representation in the form of a NeRF from a fast-moving event camera. Our method can recover NeRFs during very fast motion and in high-dynamic-range conditions where frame-based approaches fail. We show that rendering high-quality frames is possible by only providing an event stream as input. Furthermore, by combining events and frames, we can estimate NeRFs of higher quality than state-of-the-art approaches under severe motion blur. We also show that combining events and frames can overcome failure cases of NeRF estimation in scenarios where only a few input views are available without requiring additional regularization.
References
Data-Efficient Collaborative Decentralized Thermal-Inertial Odometry
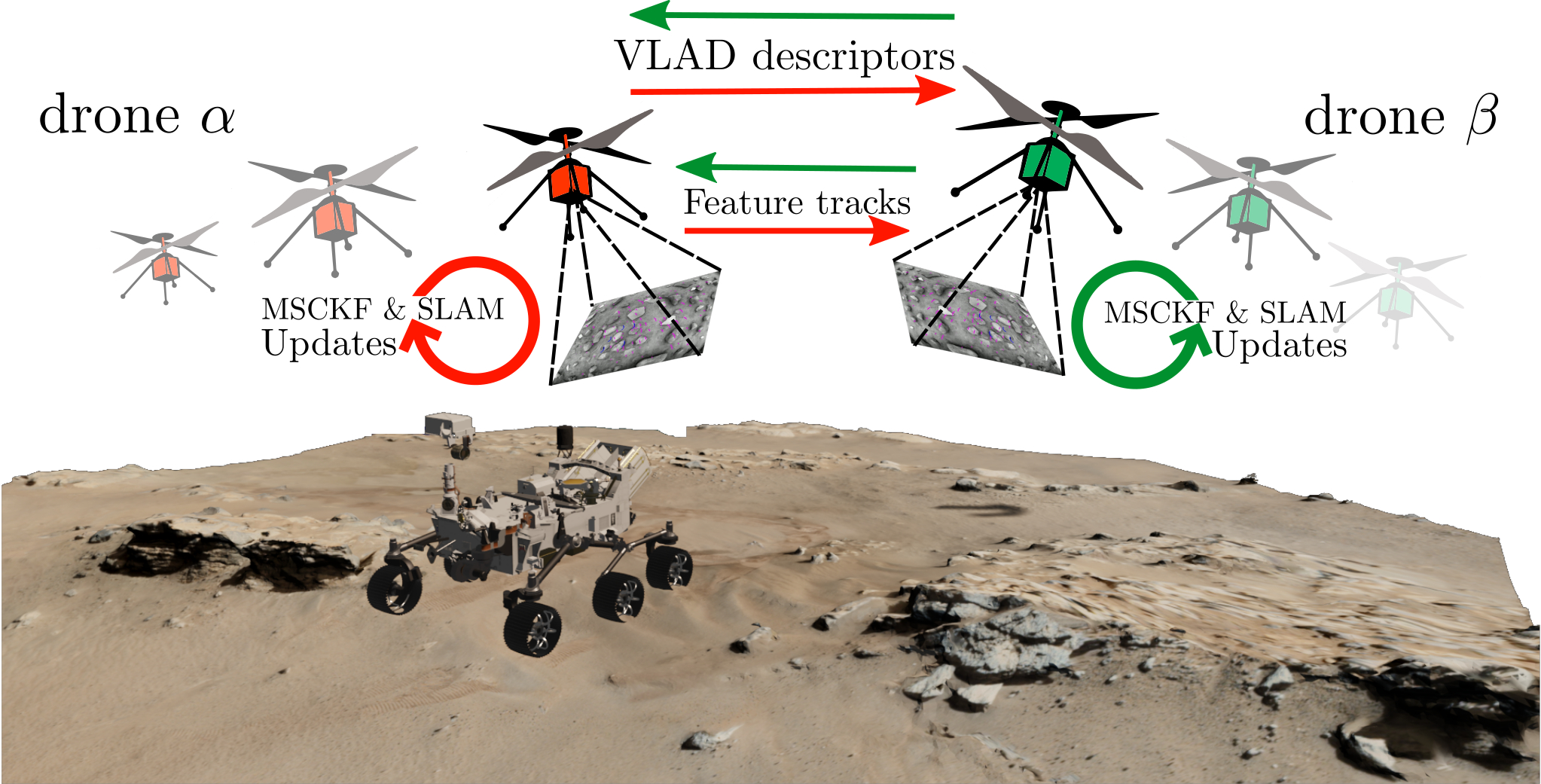
We propose a system solution to achieve data-efficient, decentralized state estimation for a team of flying robots using thermal images and inertial measurements. Each robot can fly independently, and exchange data when possible to refine its state estimate. Our system front-end applies an online photometric calibration to refine the thermal images so as to enhance feature tracking and place recognition. Our system back-end uses a covariance intersection fusion strategy to neglect the cross-correlation between agents so as to lower memory usage and computational cost. The communication pipeline uses Vector of Locally Aggregated Descriptors (VLAD) to construct a request-response policy that requires low bandwidth usage. We test our collaborative method on both synthetic and real-world data. Our results show that the proposed method improves by up to 46% trajectory estimation with respect to an individual-agent approach, while reducing up to 89% the communication exchange. Datasets and code are released to the public, extending the already-public JPL xVIO library.
References

Exploring Event Camera-based Odometry for Planetary Robots
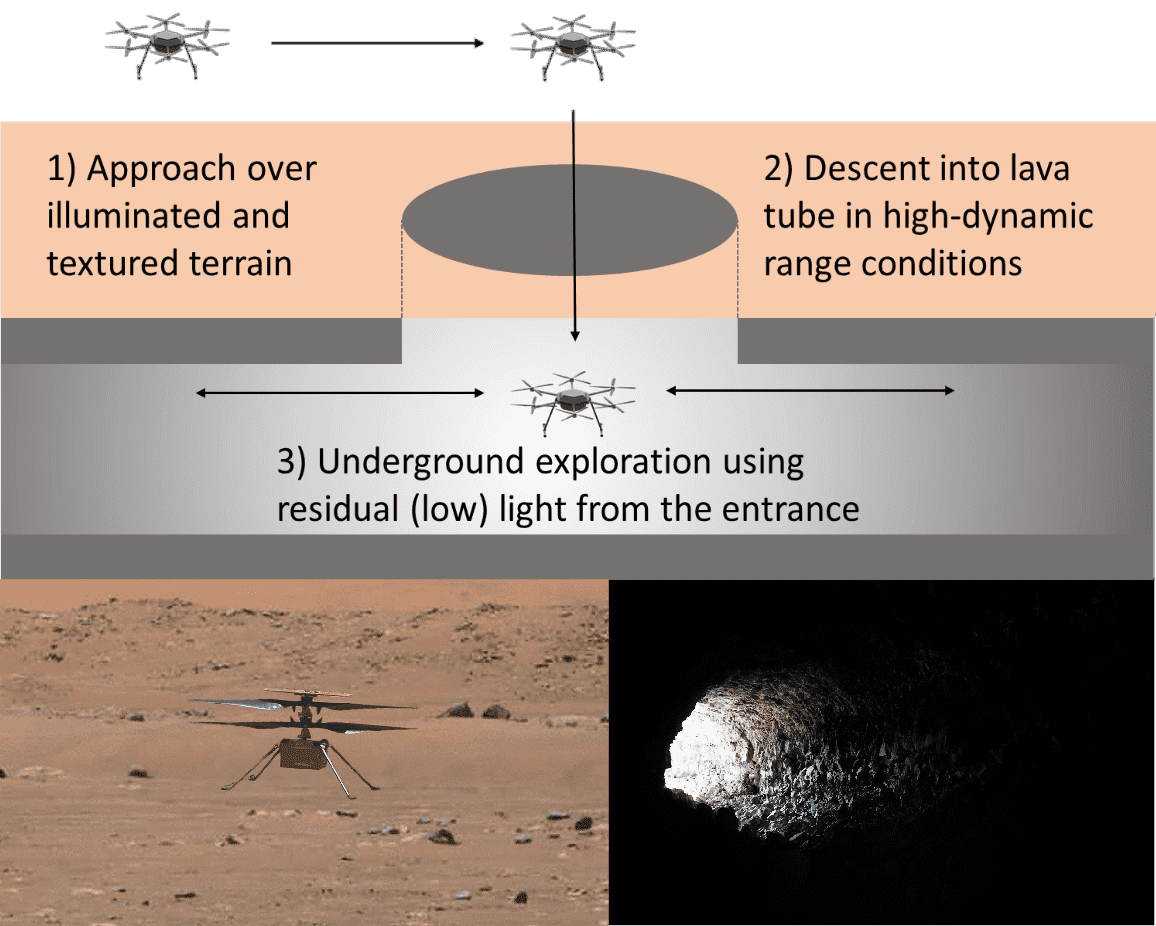
References
Exploring Event Camera-based Odometry for Planetary Robots
Robotics and Automation Letters (RAL), 2022
Hilti-Oxford Dataset: A Millimetre-Accurate Benchmark for Simultaneous Localization and Mapping

References
The Hilti SLAM Challenge Dataset

In this work, we propose a new dataset, the Hilti SLAM Challenge Dataset. The sensor platform used to collect this dataset contains a number of visual, lidar and inertial sensors which have all been rigorously calibrated. All data is temporally aligned to support precise multi-sensor fusion. Each dataset includes accurate ground truth to allow direct testing of SLAM results. Raw data as well as intrinsic and extrinsic sensor calibration data from twelve datasets in various environments is provided. Each environment represents common scenarios found in building construction sites in various stages of completion.
References
Ultimate SLAM? Combining Events, Images, and IMU for Robust Visual SLAM in HDR and High Speed Scenarios
In this paper, we present the first state estimation pipeline that leverages the complementary advantages of a standard camera with an event camera by fusing in a tightly-coupled manner events, standard frames, and inertial measurements. We show on the Event Camera Dataset that our hybrid pipeline leads to an accuracy improvement of 130% over event-only pipelines, and 85% over standard-frames only visual-inertial systems, while still being computationally tractable.
Furthermore, we use our pipeline to demonstrate - to the best of our knowledge - the first autonomous quadrotor flight using an event camera for state estimation, unlocking flight scenarios that were not reachable with traditional visual inertial odometry, such as low-light environments and high dynamic range scenes.
References

Ultimate SLAM? Combining Events, Images, and IMU for Robust Visual SLAM in HDR and High Speed Scenarios
IEEE Robotics and Automation Letters (RA-L), 2018.
PDF YouTube ICRA18 Video Pitch Poster Results (raw trajectories) Project Webpage Source Code
Event-aided Direct Sparse Odometry

We introduce EDS, a direct monocular visual odometry using events and frames. Our algorithm leverages the event generation model to track the camera motion in the blind time between frames. The method formulates a direct probabilistic approach of observed brightness increments. Per-pixel brightness increments are predicted using a sparse number of selected 3D points and are compared to the events via the brightness increment error to estimate camera motion. The method recovers a semi-dense 3D map using photometric bundle adjustment. EDS is the first method to perform 6-DOF VO using events and frames with a direct approach. By design it overcomes the problem of changing appearance in indirect methods. We also show that, for a target error performance, EDS can work at lower frame rates than state-of-the-art frame-based VO solutions. This opens the door to low-power motion-tracking applications where frames are sparingly triggered "on demand'' and our method tracks the motion in between. We release code and datasets to the public.
References
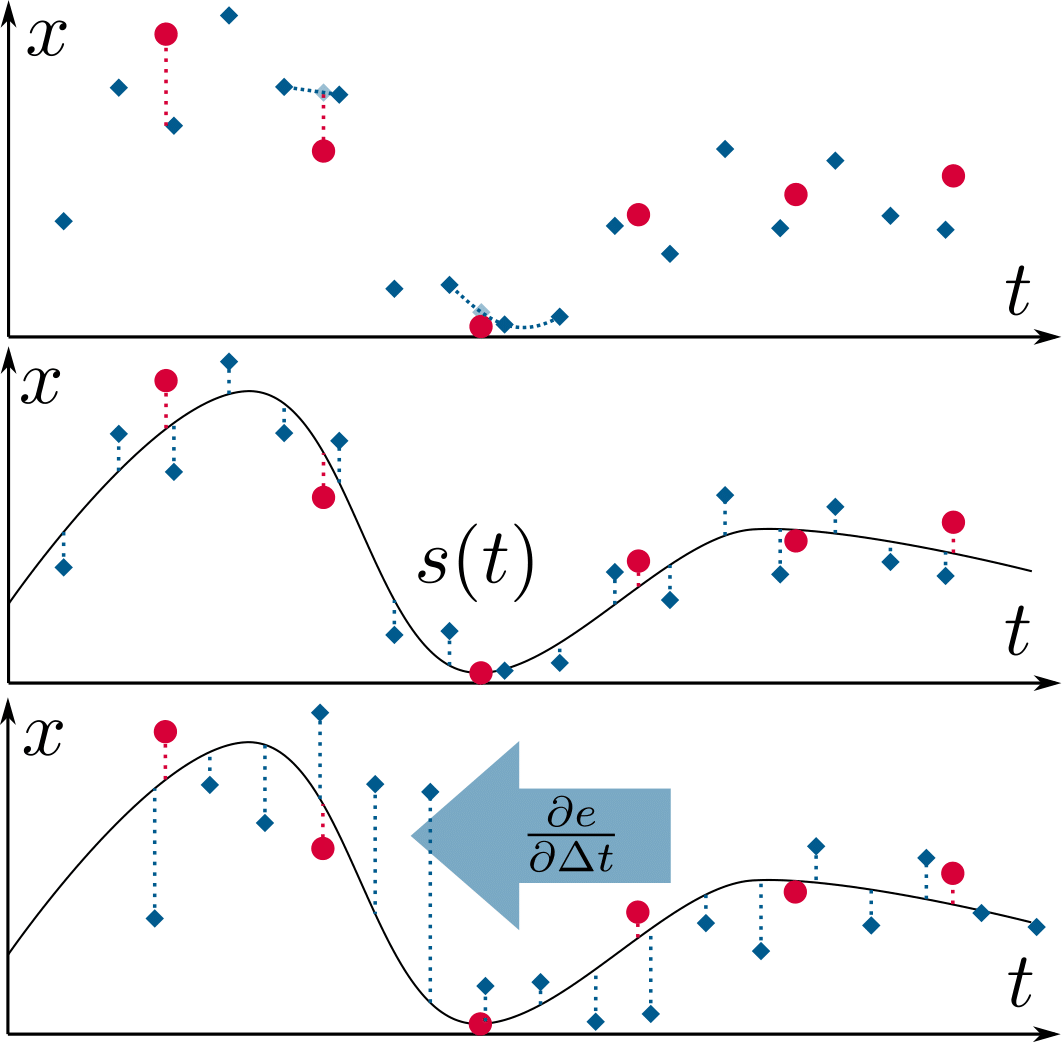
Continuous-Time vs. Discrete-Time Vision-based SLAM: A Comparative Study
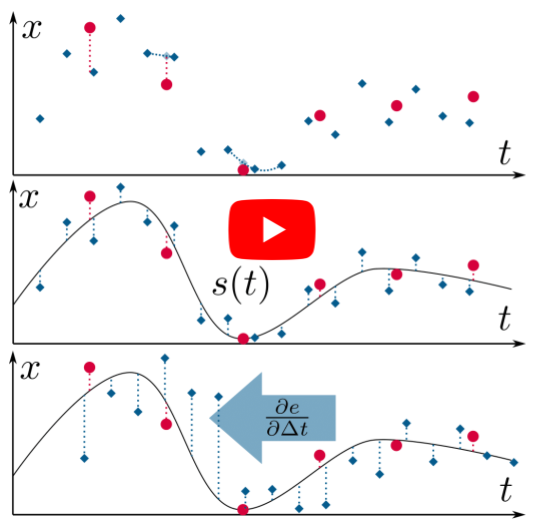
Robotic practitioners generally approach the vision-based SLAM problem through discrete-time formulations. This has the advantage of a consolidated theory and very good understanding of success and failure cases. However, discrete-time SLAM needs tailored algorithms and simplifying assumptions when high-rate and/or asynchronous measurements, coming from different sensors, are present in the estimation process. Conversely, continuous-time SLAM, often overlooked by practitioners, does not suffer from these limitations. Indeed, it allows integrating new sensor data asynchronously without adding a new optimization variable for each new measurement. In this way, the integration of asynchronous or continuous high-rate streams of sensor data does not require tailored and highly-engineered algorithms, enabling the fusion of multiple sensor modalities in an intuitive fashion. On the down side, continuous time introduces a prior that could worsen the trajectory estimates in some unfavorable situations. In this work, we aim at systematically comparing the advantages and limitations of the two formulations in vision-based SLAM. To do so, we perform an extensive experimental analysis, varying robot type, speed of motion, and sensor modalities. Our experimental analysis suggests that, independently of the trajectory type, continuous-time SLAM is superior to its discrete counterpart whenever the sensors are not time-synchronized. In the context of this work, we developed, and open source, a modular and efficient software architecture containing state-of-the-art algorithms to solve the SLAM problem in discrete and continuous time.
References
Augmenting Visual Place Recognition with Structural Cues
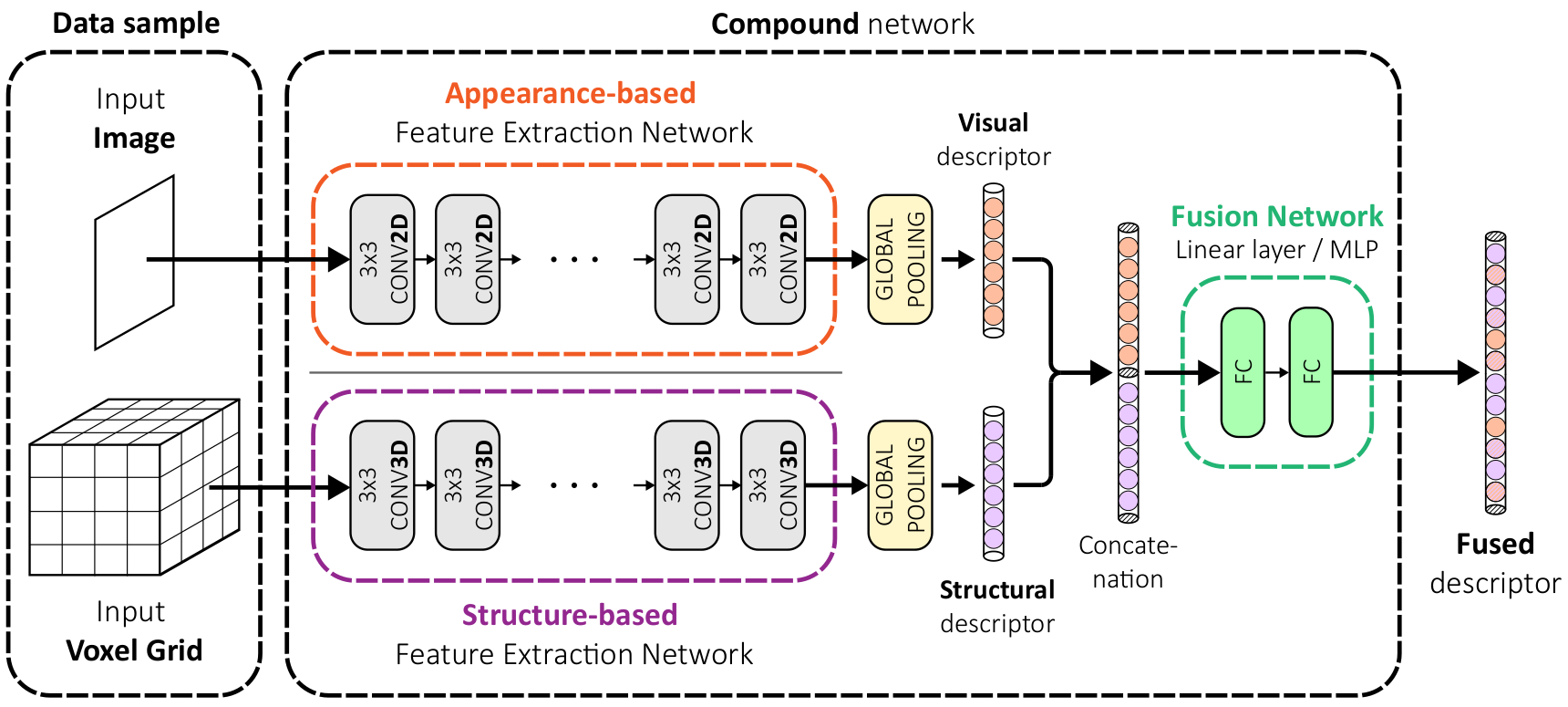
In this work, we propose to augment image-based place recognition with structural cues. Specifically, these structural cues are obtained using structure-from-motion, such that no additional sensors are needed for place recognition. This is achieved by augmenting the 2D convolutional neural network (CNN) typically used for image-based place recognition with a 3D CNN that takes as input a voxel grid derived from the structure-from-motion point cloud. We evaluate different methods for fusing the 2D and 3D features and obtain best performance with global average pooling and simple concatenation. The resulting descriptor exhibits superior recognition performance compared to descriptors extracted from only one of the input modalities, including state-of-the-art image-based descriptors. Especially at low descriptor dimensionalities, we outperform state-of-the-art descriptors by up to 90%.
References

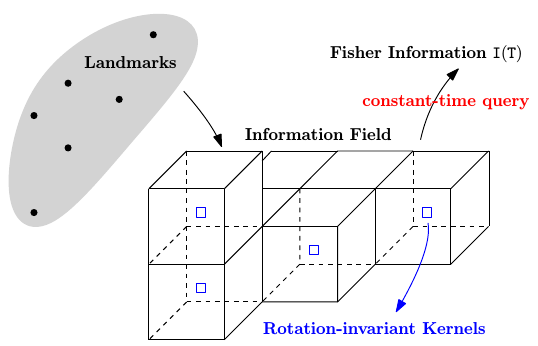
Fisher Information Field: an Efficient and Differentiable Map for Perception-aware Planning
References
Fisher Information Field: an Efficient and Differentiable Map for Perception-aware Planning
arXiv preprint, 2020.
Tightly-coupled Fusion of Global Positional Measurements in Optimization-based Visual-Inertial Odometry
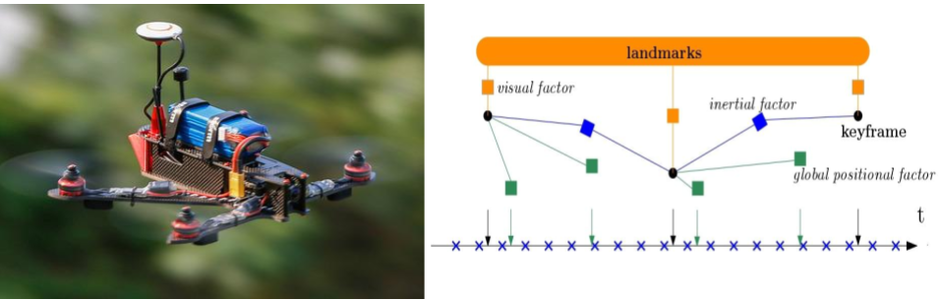
Motivated by the goal of achieving robust, drift-free pose estimation in long-term autonomous navigation, in this work we propose a methodology to fuse global positional information with visual and inertial measurements in a tightly-coupled nonlinear-optimization based estimator. Differently from previous works, which are loosely-coupled, the use of a tightly-coupled approach allows exploiting the correlations amongst all the measurements. A sliding window of the most recent system states is estimated by minimizing a cost function that includes visual re-projection errors, relative inertial errors, and global positional residuals. We use IMU preintegration to formulate the inertial residuals and leverage the outcome of such algorithm to efficiently compute the global position residuals. The experimental results show that the proposed method achieves accurate and globally consistent estimates, with negligible increase of the optimization computational cost. Our method consistently outperforms the loosely-coupled fusion approach. The mean position error is reduced up to 50% with respect to the loosely-coupled approach in outdoor Unmanned Aerial Vehicle (UAV) flights, where the global position information is given by noisy GPS measurements. To the best of our knowledge, this is the first work where global positional measurements are tightly fused in an optimization-based visual-inertial odometry algorithm, leveraging the IMU preintegration method to define the global positional factors.
References

Reference Pose Generation for Visual Localization via Learned Features and View Synthesis
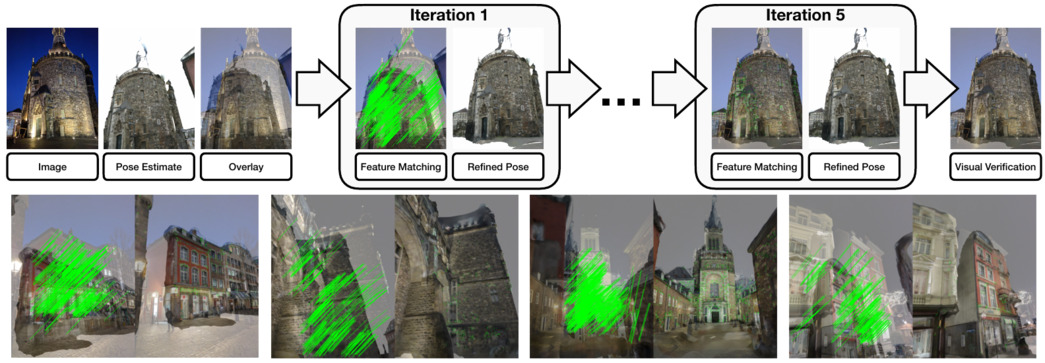
Visual Localization is one of the key enabling technologies for autonomous driving and augmented reality. High quality datasets with accurate 6 Degree-of-Freedom (DoF) reference poses are the foundation for benchmarking and improving existing methods. Traditionally, reference poses have been obtained via Structure-from-Motion (SfM). However, SfM itself relies on local features which are prone to fail when images were taken under different conditions, e.g., day/night changes. At the same time, manually annotating feature correspondences is not scalable and potentially inaccurate. In this work, we propose a semi-automated approach to generate reference poses based on feature matching between renderings of a 3D model and real images via learned features. Given an initial pose estimate, our approach iteratively refines the pose based on feature matches against a rendering of the model from the current pose estimate. We significantly improve the nighttime reference poses of the popular Aachen Day-Night dataset, showing that state-of-the-art visual localization methods perform better (up to 47%) than predicted by the original reference poses. We extend the dataset with new nighttime test images, provide uncertainty estimates for our new reference poses, and introduce a new evaluation criterion. We will make our reference poses and our framework publicly available upon publication.
References

Reference Pose Generation for Long-term Visual Localization via Learned Features
and View Synthesis
International Journal of Computer Vision (IJCV), 2020.
GPU-Accelerated Frontend for High-Speed VIO
The recent introduction of powerful embedded graphics processing units (GPUs) has allowed for unforeseen improvements in real-time computer vision applications. It has enabled algorithms to run onboard, well above the standard video rates, yielding not only higher information processing capability, but also reduced latency. This work focuses on the applicability of efficient low-level, GPU hardware-specific instructions to improve on existing computer vision algorithms in the field of visual-inertial odometry (VIO). While most steps of a VIO pipeline work on visual features, they rely on image data for detection and tracking, of which both steps are well suited for parallelization. Especially non-maxima suppression and the subsequent feature selection are prominent contributors to the overall image processing latency. Our work first revisits the problem of non-maxima suppression for feature detection specifically on GPUs, and proposes a solution that selects local response maxima, imposes spatial feature distribution, and extracts features simultaneously. Our second contribution introduces an enhanced FAST feature detector that applies the aforementioned non-maxima suppression method. Finally, we compare our method to other state-of-the-art CPU and GPU implementations, where we always outperform all of them in feature tracking and detection, resulting in over 1000fps throughput on an embedded Jetson TX2 platform. Additionally, we demonstrate our work integrated in a VIO pipeline achieving a metric state estimation at ~200fps.
References

Voxel Map for Visual SLAM
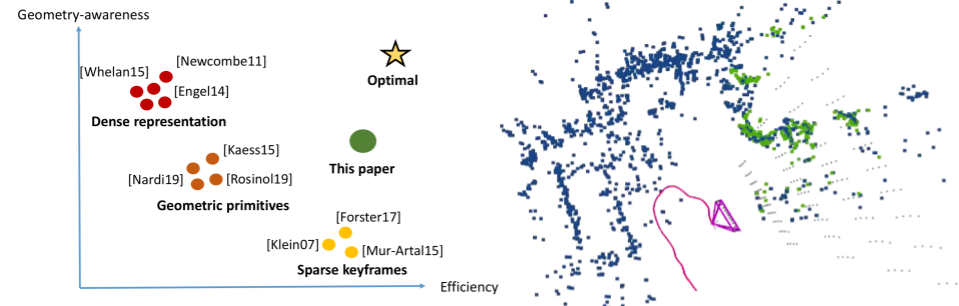
References

Voxel Map for Visual SLAM
IEEE International Conference on Robotics and Automation, 2020.
Redesigning SLAM for Arbitrary Multi-Camera Systems
References

Redesigning SLAM for Arbitrary Multi-Camera Systems
IEEE International Conference on Robotics and Automation, 2020.
Smart Interest Points
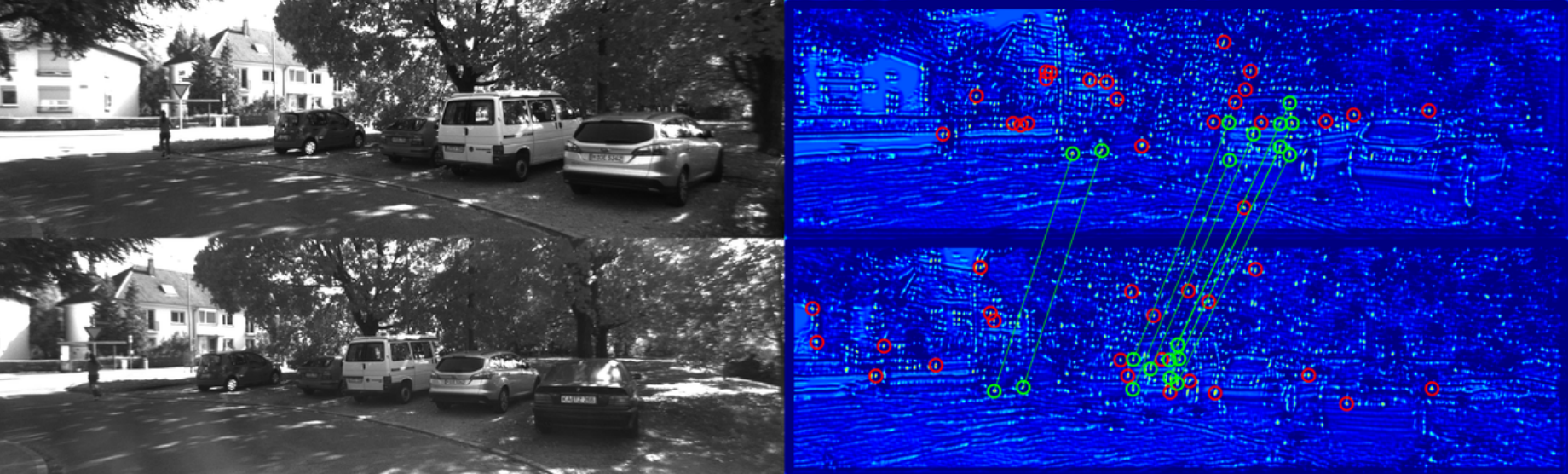
Detecting interest points is a key component of vision-based estimation algorithms, such as visual odometry or visual SLAM. In the context of distributed visual SLAM, we have encountered the need to minimize the amount of data that is sent between robots, which, for relative pose estimation, translates into the need to find a minimum set of interest points that is sufficiently reliably detected between viewpoints to ensure relative pose estimation. We have decided to solve this problem at a fundamental level, that is, at the point detector, using machine learning.
In SIPS, we introduce the succinctness metric, which allows to quantify performance of interest point detectors with respect to this goal. At the same time, we propose an unsupervised training method for CNN interest point detectors which requires no labels - only uncalibrated image sequences. The proposed method is able to establish relative poses with a minimum of extracted interest points. However, descriptors still need to be extracted and transmitted to establish these poses.
This problem is addressed in IMIPs, where we propose the first feature matching pipeline that works by implicit matching, without the need of descriptors. In IMIPs, the detector CNN has multiple output channels, and each channel generates a single interest point. Between viewpoints, interest points obtained from the same channel are considered implicitly matched. This allows matching points with as little as 3 bytes per point - the point coordinates in an up to 4096 x 4096 image.
References

Matching Features without Descriptors:
Implicitly Matched Interest
Points
British Machine Vision Conference (BMVC), Cardiff, 2019.

SIPs: Succinct Interest Points from Unsupervised Inlierness Probability Learning
IEEE International Conference on 3D Vision (3DV), 2019.
Visual-Inertial Odometry of Aerial Robotics
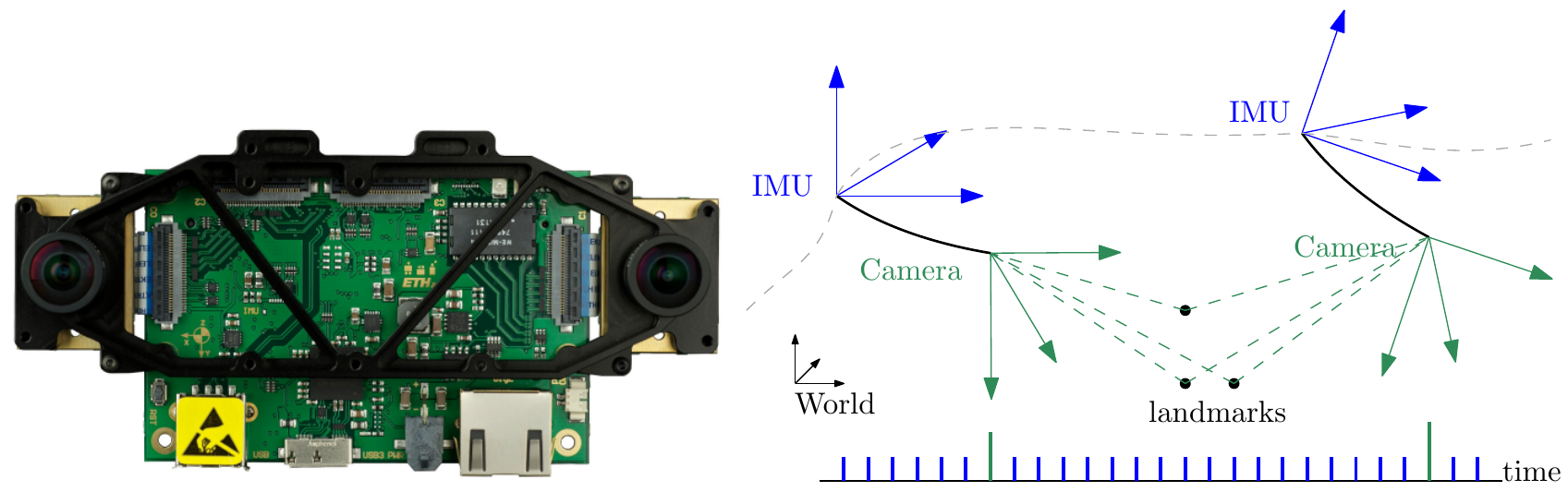
References

Probabilistic, Continuous-Time Trajectory Evaluation for SLAM
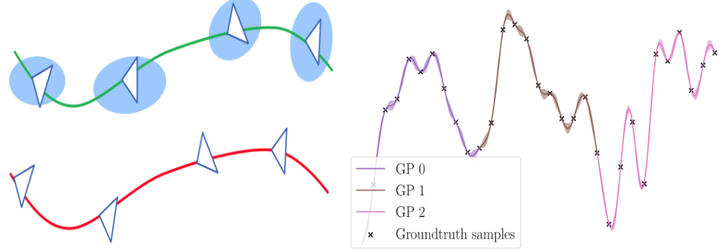
References
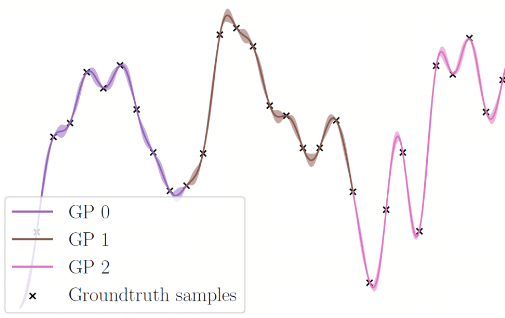
Rethinking Trajectory Evaluation for SLAM: a Probabilistic, Continuous-Time Approach
ICRA19 Workshop on Dataset Generation and Benchmarking of SLAM Algorithms for Robotics and VR/AR
Best Paper Award!
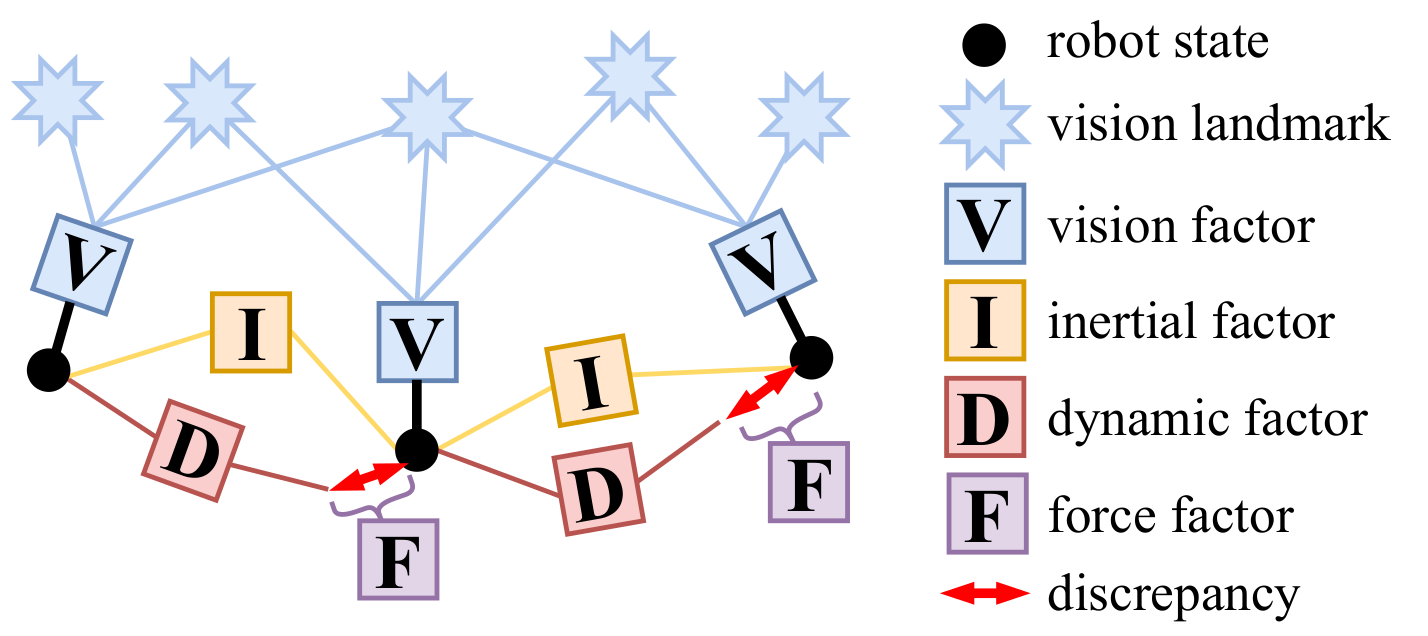
Visual Inertial Model-based Odometry and Force Estimation
References
Fisher Information Field for Active Visual Localization
References
A Tutorial on Quantitative Trajectory Evaluation for Visual(-Inertial) Odometry
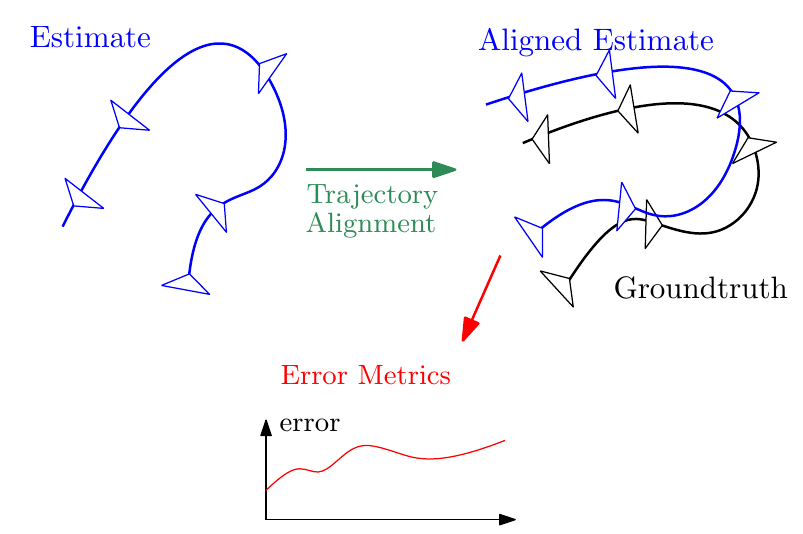
References
A Tutorial on Quantitative Trajectory Evaluation for Visual(-Inertial) Odometry
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, 2018.
On the Comparison of Gauge Freedom Handling in Optimization-based Visual-Inertial State Estimation
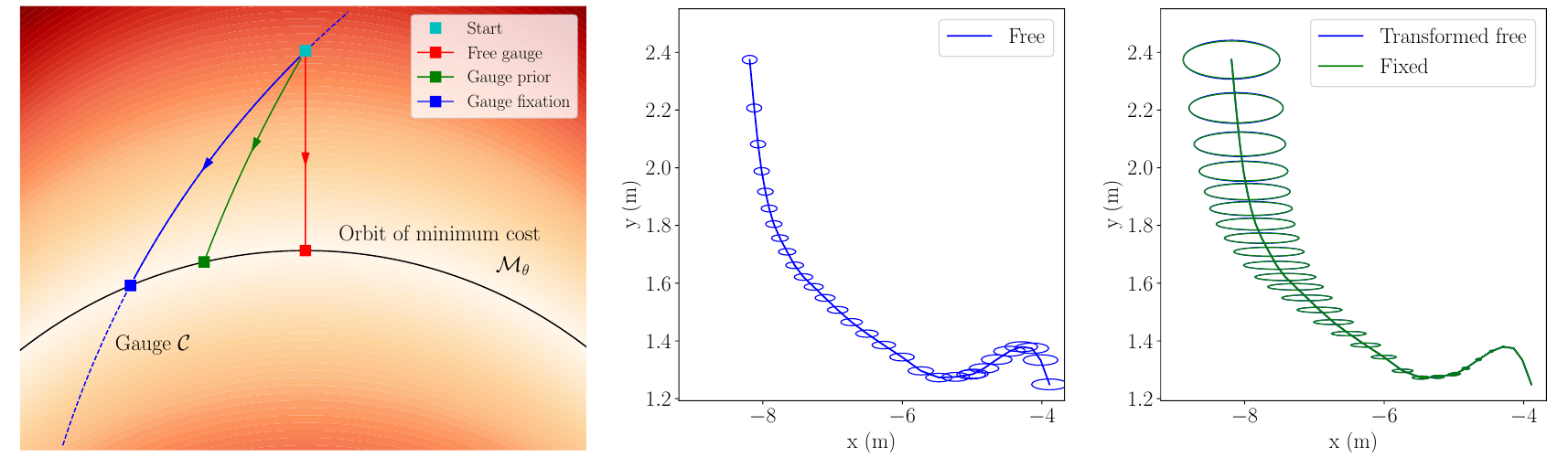
References
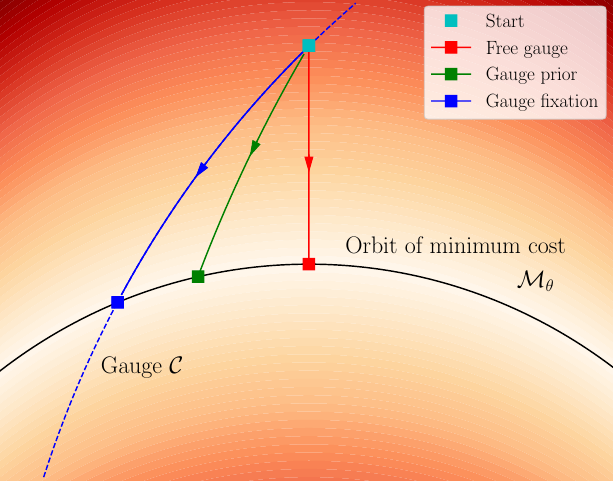
Visual-Inertial Odometry Benchmarking
References

Active Exposure Control for Robust Visual Odometry in High Dynamic Range (HDR) Environments
References

IMU Preintegration on Manifold for Efficient Visual-Inertial Maximum-a-Posteriori Estimation
References
On-Manifold Preintegration for Real-Time Visual-Inertial Odometry
IEEE Transactions on Robotics, in press, 2016.
IMU Preintegration on Manifold for Efficient Visual-Inertial Maximum-a-Posteriori Estimation
Robotics: Science and Systems (RSS), Rome, 2015.
Best Paper Award Finalist! Oral Presentation: Acceptance Rate 4%
SVO: Fast Semi-Direct Monocular Visual Odometry
References
SVO: Semi-Direct Visual Odometry for Monocular and Multi-Camera Systems
IEEE Transactions on Robotics, Vol. 33, Issue 2, pages 249-265, Apr. 2017.
Includes comparison against ORB-SLAM, LSD-SLAM, and DSO and comparison among Dense, Semi-dense, and Sparse Direct Image Alignment.

SVO: Fast Semi-Direct Monocular Visual Odometry
IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, 2014.

1-point RANSAC
Given a car equipped with an omnidirectional camera, the motion of the vehicle can be purely recovered from salient features tracked over time. We propose the 1-Point RANSAC algorithm which runs at 800 Hz on a normal laptop. To our knowledge, this is the most efficient visual odometry algorithm.


