



Drone Racing
Drone racing is a popular sport in which professional pilots fly small quadrotors through complex tracks at high speeds. Developing a fully autonomous racing drone is difficult due to challenges that span dynamics modeling, onboard perception, localization and mapping, trajectory generation, and optimal control. In this page, we summarize our research on this topic.
Dream to Fly: Model-Based Reinforcement Learning for Vision-Based Drone Flight

Can we use Model-based Reinforcement Learning (MBRL) to fly a drone from pixels to commands? In our paper, we present an approach for training quadrotor navigation policies from scratch using world models to map raw onboard camera pixels directly to control commands, much like a human pilot. While model-free methods such as PPO are sample-inefficient and struggle in this setting, we leverage MBRL to train visuomotor policies capable of agile flight through a racetrack using only raw pixel observations. Moreover, because our policies are trained end-to-end directly from pixels, we no longer require the perception-aware reward term used in previous methods. Instead, we show that this behavior naturally emerges, resulting in policies that guide the camera toward feature-rich areas of the observation space.
References
Perception-Aware Time-Optimal Planning for Quadrotor Waypoint Flight

Agile quadrotor flight pushes the limits of control, actuation, and onboard perception. While time-optimal trajectory planning has been extensively studied, existing approaches typically neglect the tight coupling between vehicle dynamics, environmental geometry, and the visual requirements of onboard state estimation. As a result, trajectories that are dynamically feasible may fail in closed-loop execution due to degraded visual quality. This paper introduces a unified time-optimal trajectory optimization framework for vision-based quadrotors that explicitly incorporates perception constraints alongside full nonlinear dynamics, rotor actuation limits, aerodynamic effects, camera field-of-view constraints, and convex geometric gate representations. The proposed formulation solves minimum-time lap trajectories for arbitrary racetracks with diverse gate shapes and orientations, while remaining numerically robust and computationally efficient. We derive an information-theoretic position uncertainty metric to quantify visual state-estimation quality and integrate it into the planner through three perception objectives: position uncertainty minimization, sequential field-of-view constraints, and look-ahead alignment. This enables systematic exploration of the trade-offs between speed and perceptual reliability. To accurately track the resulting perception-aware trajectories, we develop a model predictive contouring tracking controller that separates lateral and progress errors. Experiments demonstrate real-world flight speeds up to 9.8 m/s with 0.07 m average tracking error, and closed-loop success rates improved from 55\% to 100\% on a challenging Split-S course. The proposed system provides a scalable benchmark for studying the fundamental limits of perception-aware, time-optimal autonomous flight.
References
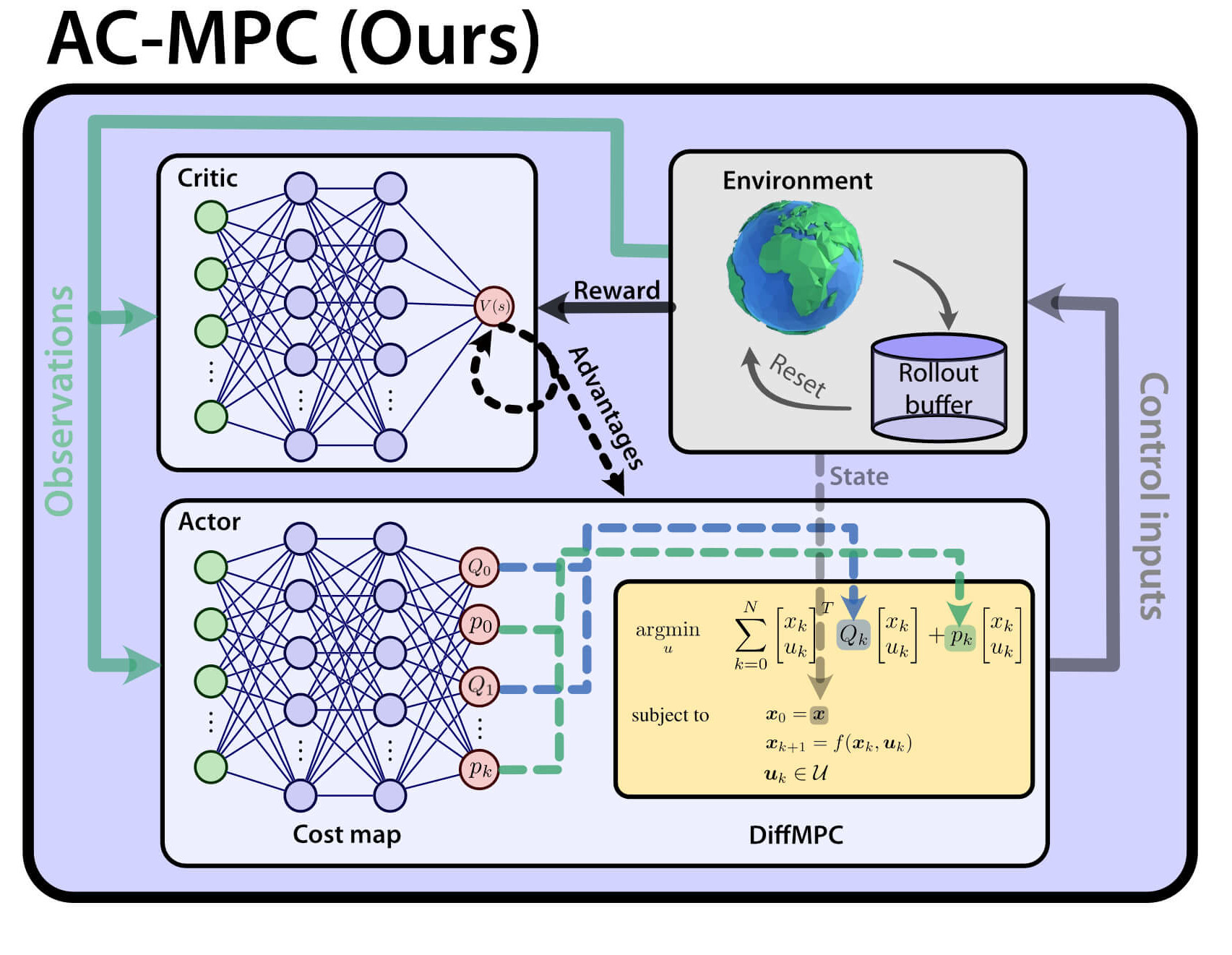
Actor-Critic Model Predictive Control: Differentiable Optimization meets Reinforcement Learning for Agile Flight
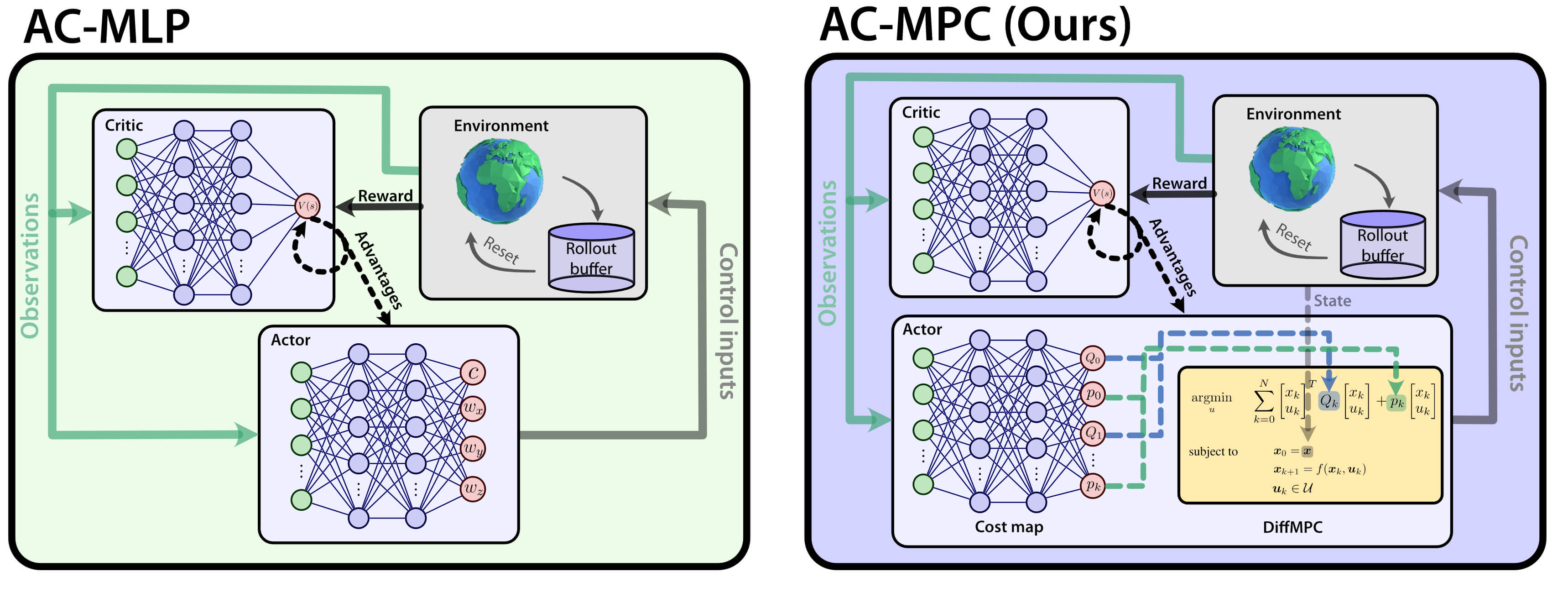
Is it possible to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC)? This extension digs deeper into the answer by studying our new framework called Actor-Critic Model Predictive Control. We conduct a deep study that exposes the benefits of the proposed approach: it achieves better out-of-distribution behaviour, better robustness to changes in the dynamics and improved sample efficiency. Additionally, we conduct an empirical analysis that reveals a relationship between the critic's learned value function and the cost function of the differentiable MPC, providing a deeper understanding of the interplay between the critic's value and the MPC cost functions. Our method achieves the same superhuman performance as state-of-the-art model-free RL, showcasing speeds of up to 21 m/s.
References
Environment as Policy: Learning to Race in Unseen Tracks

Reinforcement learning (RL) has achieved outstanding success in complex robot control tasks, such as drone racing, where the RL agents have outperformed human champions in a known racing track. However, these agents fail in unseen track configurations, always requiring complete retraining when presented with new track layouts. This work aims to develop RL agents that generalize effectively to novel track configurations without retraining. The na¨ıve solution of training directly on a diverse set of track layouts can overburden the agent, resulting in suboptimal policy learning as the increased complexity of the environment impairs the agent’s ability to learn to fly. To enhance the generalizability of the RL agent, we propose an adaptive environment-shaping framework that dynamically adjusts the training environment based on the agent’s performance. We achieve this by leveraging a secondary RL policy to design environments that strike a balance between being challenging and achievable, allowing the agent to adapt and improve progressively. Using our adaptive environment shaping, one single racing policy efficiently learns to race in diverse challenging tracks. Experimental results validated in both simulation and the real world show that our method enables drones to successfully fly complex and unseen race tracks, outperforming existing environment-shaping techniques.
References

Environment as Policy: Learning to Race in Unseen Tracks
IEEE International Conference on Robotics and Automation (ICRA), 2025.
Bootstrapping Reinforcement Learning with Imitation for Vision-Based Agile Flight

We combine the effectiveness of Reinforcement Learning (RL) and the efficiency of Imitation Learning (IL) in the context of vision-based, autonomous drone racing. We focus on directly processing visual input without explicit state estimation. While RL offers a general framework for learning complex controllers through trial and error, it faces challenges regarding sample efficiency and computational demands due to the high dimensionality of visual inputs. Conversely, IL demonstrates efficiency in learning from visual demonstrations but is limited by the quality of those demonstrations and faces issues like covariate shift. To overcome these limitations, we propose a novel training framework combining RL and IL advantages. Our framework involves three stages: (i) initial training of a teacher policy using privileged state information, (ii) distilling this policy into a student policy using IL, (iii) performance-constrained adaptive RL fine-tuning. Our experiments in both simulated and real-world environments demonstrate that our approach achieves superior performance and robustness than IL or RL alone in navigating a quadrotor through a racing course using only visual information without explicit state estimation.
References
Learning Agile, Vision-Based Drone Flight: From Simulation to Reality

We present our latest research in learning deep sensorimotor policies for agile, vision-based quadrotor flight. We show methodologies for the successful transfer of such policies from simulation to the real world. In addition, we discuss the open research questions that still need to be answered to improve the agility and robustness of autonomous drones toward human-pilot performance.
References
Demonstrating Agile Flight from Pixels without State Estimation
We present the first vision-based quadrotor system that autonomously navigates through a sequence of gates at high speeds while directly mapping pixels to control commands. Like professional drone-racing pilots, our system does not use explicit state estimation and leverages the same control commands humans use (collective thrust and body rates). We demonstrate agile flight at speeds up to 40km/h with accelerations up to 2g. This is achieved by training vision-based policies with reinforcement learning (RL). The training is facilitated using an asymmetric actor-critic with access to privileged information. To overcome the computational complexity during image-based RL training, we use the inner edges of the gates as a sensor abstraction. Our approach enables autonomous agile flight with standard, off-the-shelf hardware.
References

MPCC++: Model Predictive Contouring Control for Time-Optimal Flight with Safety Constraints
This paper introduces three key components that enhance the MPCC approach for drone racing. First, we provide safety guarantees in the form of a constraint and tunnel-shaped terminal set, which prevents gate collisions. Second, we augment the dynamics with a residual term that captures complex aerodynamic effects and thrust forces learned directly from real world data. Third, we use Trust Region Bayesian Optimization (TuRBO) to tune the hyperparameters of the MPC controller given a sparse reward based on lap time minimization. The proposed approach achieves similar lap times to the best state-of-the-art RL while satisfying constraints, achieving 100% success rate in simulation and real-world.
References

Autonomous Drone Racing: A Survey

Over the last decade, the use of autonomous drone systems for surveying, search and rescue, or last-mile delivery has increased exponentially. With the rise of these applications comes the need for highly robust, safety-critical algorithms which can operate drones in complex and uncertain environments. Additionally, flying fast enables drones to cover more ground which in turn increases productivity and further strengthens their use case. One proxy for developing algorithms used in high-speed navigation is the task of autonomous drone racing, where researchers program drones to fly through a sequence of gates and avoid obstacles as quickly as possible using onboard sensors and limited computational power. Speeds and accelerations exceed over 80 kph and 4 g respectively, raising significant challenges across perception, planning, control, and state estimation. To achieve maximum performance, systems require real-time algorithms that are robust to motion blur, high dynamic range, model uncertainties, aerodynamic disturbances, and often unpredictable opponents. This survey covers the progression of autonomous drone racing across model-based and learning-based approaches. We provide an overview of the field, its evolution over the years, and conclude with the biggest challenges and open questions to be faced in the future.
References
Bootstrapping Reinforcement Learning with Imitation for Vision-Based Agile Flight

We combine the effectiveness of Reinforcement Learning (RL) and the efficiency of Imitation Learning (IL) in the context of vision-based, autonomous drone racing. We focus on directly processing visual input without explicit state estimation. While RL offers a general framework for learning complex controllers through trial and error, it faces challenges regarding sample efficiency and computational demands due to the high dimensionality of visual inputs. Conversely, IL demonstrates efficiency in learning from visual demonstrations but is limited by the quality of those demonstrations and faces issues like covariate shift. To overcome these limitations, we propose a novel training framework combining RL and IL advantages. Our framework involves three stages: (i) initial training of a teacher policy using privileged state information, (ii) distilling this policy into a student policy using IL, (iii) performance-constrained adaptive RL fine-tuning. Our experiments in both simulated and real-world environments demonstrate that our approach achieves superior performance and robustness than IL or RL alone in navigating a quadrotor through a racing course using only visual information without explicit state estimation.
References
Actor-Critic Model Predictive Control
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the robustness inherent to MPC.
References

Actor-Critic Model Predictive Control
IEEE International Conference on Robotics and Automation (ICRA), Yokohama, 2024.
Contrastive Initial State Buffer for Reinforcement Learning
In Reinforcement Learning, the trade-off between exploration and exploitation poses a complex challenge for achieving efficient learning from limited samples. While recent works have been effective in leveraging past experiences for policy updates, they often overlook the potential of reusing past experiences for data collection. Independent of the underlying RL algorithm, we introduce the concept of a Contrastive Initial State Buffer, which strategically selects states from past experiences and uses them to initialize the agent in the environment in order to guide it toward more informative states. We validate our approach on two complex robotic tasks without relying on any prior information about the environment: (i) locomotion of a quadruped robot traversing challenging terrains and (ii) a quadcopter drone racing through a track. The experimental results show that our initial state buffer achieves higher task performance than the nominal baseline while also speeding up training convergence.
References

Contrastive Learning for Enhancing Robust Scene Transfer in Vision-based Agile Flight
Scene transfer for vision-based mobile robotics applications is a highly relevant and challenging problem. The utility of a robot greatly depends on its ability to perform a task in the real world, outside of a well-controlled lab environment. Existing scene transfer end-to-end policy learning approaches often suffer from poor sample efficiency or limited generalization capabilities, making them unsuitable for mobile robotics applications. This work proposes an adaptive multi- pair contrastive learning strategy for visual representation learning that enables zero-shot scene transfer and real-world deployment. Control policies relying on the embedding are able to operate in unseen environments without the need for finetuning in the deployment environment. We demonstrate the performance of our approach on the task of agile, vision-based quadrotor flight. Extensive simulation and real-world experi- ments demonstrate that our approach successfully generalizes beyond the training domain and outperforms all baselines.
References

Reaching the Limit in Autonomous Racing: Optimal Control vs. Reinforcement Learning
Why can ReinforcementLearning (RL) achieve results beyond OptimalControl (OC) in many real-world robotics control tasks? We investigate this question in our paper published today in Science Robotics. We argue that this question can be investigated along two axes: the optimization method and the optimization objective. Our results indicate that RL does not outperform OC because RL optimizes its objective better. Rather, RL outperforms OC because it optimizes a better objective. RL can directly optimize a task-level objective and can leverage domain randomization to cope with model uncertainty, allowing the discovery of more robust control responses. Beyond the fundamental study, our work contributes an RL-based controller that delivers the highest performance ever demonstrated on an autonomous racing drone. Our drone achieved remarkable performance: peak acceleration greater than 12 g and peak velocity ~108 km/h, all within minutes of training with a standard workstation.
References

Champion-level Drone Racing using Deep Reinforcement Learning
First-person view (FPV) drone racing is a televised sport in which professional competitors pilot high-speed aircraft through a three-dimensional circuit. Each pilot sees the environment from their drone's perspective via video streamed from an onboard camera. Reaching the level of professional pilots with an autonomous drone is challenging since the robot needs to fly at its physical limits while estimating its speed and location in the circuit exclusively from onboard sensors. Here we introduce Swift, an autonomous system that can race physical vehicles at the level of the human world champions. The system combines deep reinforcement learning in simulation with data collected in the physical world. Swift competed against three human champions, including the world champions of two international leagues, in real-world head-to-head races. Swift won multiple races against each of the human champions and demonstrated the fastest recorded race time. This work represents a milestone for mobile robotics and machine intelligence, which may inspire the deployment of hybrid learning-based solutions in other physical systems.
References

Champion-level Drone Racing using Deep Reinforcement Learning
Nature, 2023
Learning Deep Sensorimotor Policies for Vision-based Autonomous Drone Racing
Autonomous drones can operate in remote and unstructured environments, enabling various real-world applications. However, the lack of effective vision-based algorithms has been a stumbling block to achieving this goal. Existing systems often require hand-engineered components for state estimation, planning, and control. Such a sequential design involves laborious tuning, human heuristics, and compounding delays and errors. This paper tackles the vision-based autonomous-drone racing problem by learning deep sensorimotor policies. We use contrastive learning to extract robust feature representations from the input images and leverage a two-stage learning-by-cheating framework for training a neural network policy. The resulting policy directly infers control commands with feature representations learned from raw images, forgoing the need for globally-consistent state estimation, trajectory planning, and handcrafted control design. Our experimental results indicate that our vision-based policy can achieve the same level of racing performance as the state-based policy while being robust against different visual disturbances and distractors. This work serves as a stepping-stone toward developing intelligent vision-based autonomous systems that control the drone purely from image inputs, like human pilots.
References

Learned Inertial Odometry for Autonomous Drone Racing
Inertial odometry is an attractive solution to the problem of state estimation for agile quadrotor flight. It is inexpensive, lightweight, and it is not affected by perceptual degradation. However, only relying on the integration of the inertial measurements for state estimation is infeasible. The errors and time-varying biases present in such measurements cause the accumulation of large drift in the pose estimates. Recently, inertial odometry has made significant progress in estimating the motion of pedestrians. State-of-the-art algorithms rely on learning a motion prior that is typical of humans but cannot be transferred to drones. In this work, we propose a learning-based odometry algorithm that uses an inertial measurement unit (IMU) as the only sensor modality for autonomous drone racing tasks. The core idea of our system is to couple a model-based filter, driven by the inertial measurements, with a learning-based module that has access to the thrust measurements. We show that our inertial odometry algorithm is superior to the state-of-the-art filter-based and optimization-based visual-inertial odometry as well as the state-of-the-art learned-inertial odometry in estimating the pose of an autonomous racing drone. Additionally, we show that our system is comparable to a visual-inertial odometry solution that uses a camera and exploits the known gate location and appearance. We believe that the application in autonomous drone racing paves the way for novel research in inertial odometry for agile quadrotor flight.
References
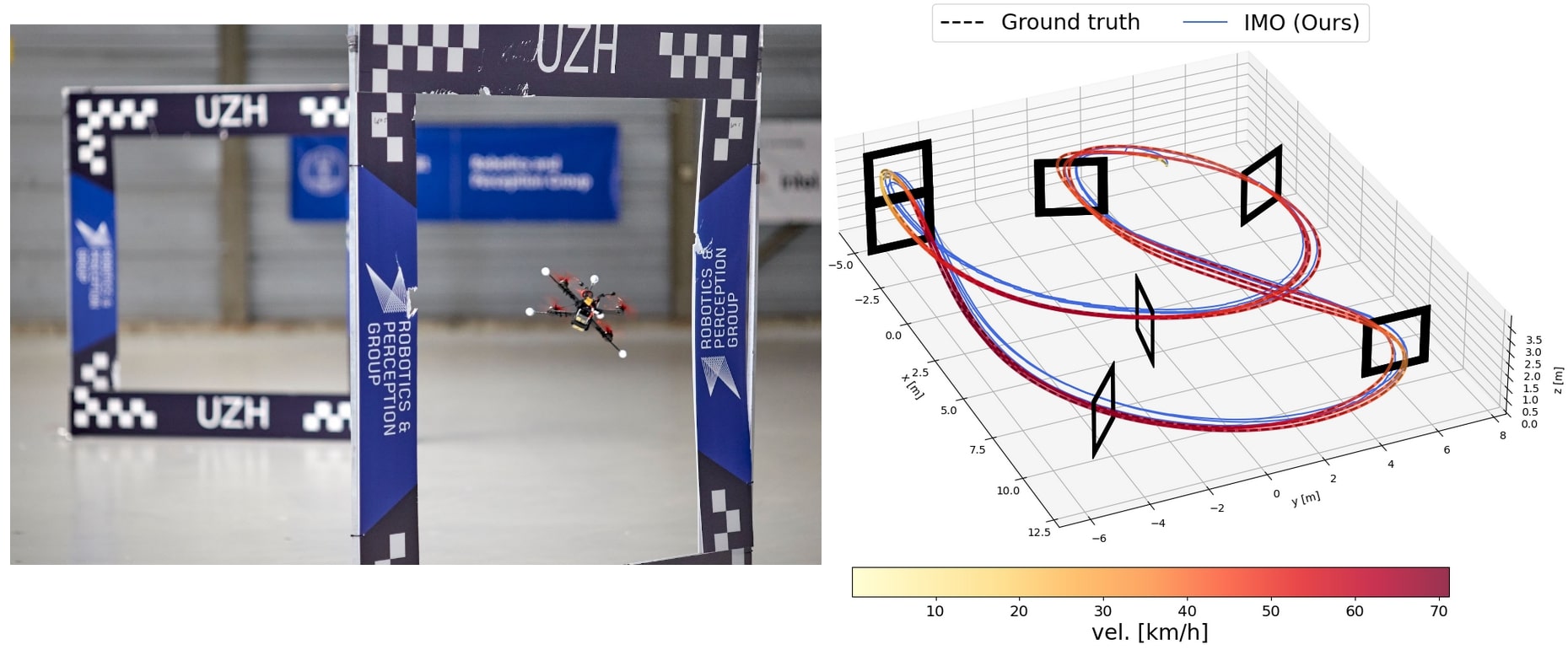
Learned Inertial Odometry for Autonomous Drone Racing
IEEE Robotics and Automation Letters (RA-L), 2023.
Agilicious: Open-Source and Open-Hardware Agile Quadrotor for Vision-Based Flight
We are excited to present Agilicious, a co-designed hardware and software framework tailored to autonomous, agile quadrotor flight. It is completely open-source and open-hardware and supports both model-based and neural-network-based controllers. Also, it provides high thrust-to-weight and torque-to-inertia ratios for agility, onboard vision sensors, GPU-accelerated compute hardware for real-time perception and neural-network inference, a real-time flight controller, and a versatile software stack. In contrast to existing frameworks, Agilicious offers a unique combination of flexible software stack and high-performance hardware. We compare Agilicious with prior works and demonstrate it on different agile tasks, using both modelbased and neural-network-based controllers. Our demonstrators include trajectory tracking at up to 5 g and 70 km/h in a motion-capture system, and vision-based acrobatic flight and obstacle avoidance in both structured and unstructured environments using solely onboard perception. Finally, we demonstrate its use for hardware-in-the-loop simulation in virtual-reality environments. Thanks to its versatility, we believe that Agilicious supports the next generation of scientific and industrial quadrotor research. For more details check our paper, video and Webpage.
References

User-Conditioned Neural Control Policies for Mobile Robotics
Recently, learning-based controllers have been shown to push mobile robotic systems to their limits and provide the robustness needed for many real-world applications. However, only classical optimization-based control frameworks offer the inherent flexibility to be dynamically adjusted during execution by, for example, setting target speeds or actuator limits. We present a framework to overcome this shortcoming of neural controllers by conditioning them on an auxiliary input. This advance is enabled by including a feature-wise linear modulation layer (FiLM). We use model-free reinforcement-learning to train quadrotor control policies for the task of navigating through a sequence of waypoints in minimum time. By conditioning the policy on the maximum available thrust or the viewing direction relative to the next waypoint, a user can regulate the aggressiveness of the quadrotor’s flight during deployment. We demonstrate in simulation and in real-world experiments that a single control policy can achieve close to time-optimal flight performance across the entire performance envelope of the robot, reaching up to 60 km/h and 4.5 g in acceleration. The ability to guide a learned controller during task execution has implications beyond agile quadrotor flight, as conditioning the control policy on human intent helps safely bringing learning based systems out of the well-defined laboratory environment into the wild.
References
Weighted Maximum Likelihood for Controller Tuning
Recently, Model Predictive Contouring Control (MPCC) has arisen as the state-of-the-art approach for modelbased agile flight. MPCC benefits from great flexibility in trading-off between progress maximization and path following at runtime without relying on globally optimized trajectories. However, finding the optimal set of tuning parameters for MPCC is challenging because (i) the full quadrotor dynamics are non-linear, (ii) the cost function is highly non-convex, and (iii) of the high dimensionality of the hyperparameter space. This paper leverages a probabilistic Policy Search method, Weighted Maximum Likelihood (WML), to automatically learn the optimal objective for MPCC. WML is sampleefficient due to its closed-form solution for updating the learning parameters. Additionally, the data efficiency provided by the use of a model-based approach allows us to directly train in a high-fidelity simulator, which in turn makes our approach able to transfer zero-shot to the real world. We validate our approach in the real world, where we show that our method outperforms both the previous manually tuned controller and the state-of-the-art auto-tuning baseline reaching speeds of 75 km/h.
References

Time-optimal Online Replanning for Agile Quadrotor Flight
In this paper, we tackle the problem of flying a quadrotor using time-optimal control policies that can be replanned online when the environment changes or when encountering unknown disturbances. This problem is challenging as the time-optimal trajectories that consider the full quadrotor dynamics are computationally expensive to generate (order of minutes or even hours). We introduce a sampling-based method for efficient generation of time-optimal paths of a point-mass model. These paths are then tracked using a Model Predictive Contouring Control approach that considers the full quadrotor dynamics and the single rotor thrust limits. Our combined approach is able to run in real-time, being the first time-optimal method that is able to adapt to changes on-the-fly. We showcase our approach's adaption capabilities by flying a quadrotor at more than 60 km/h in a racing track where gates are moving. Additionally, we show that our online replanning approach can cope with strong disturbances caused by winds of up to 68 km/h.
References

Learning Minimum-Time Flight in Cluttered Environments

Planning minimum-time trajectories in cluttered environments with obstacles is a challenging problem. It is even more challenging to track such a trajectory without collisions when flying on the edge of actuation limits using traditional control methods. To this end, we leverage deep reinforcement learning and classical topological path planning to train robust neural-network controllers for minimum-time quadrotor flight in cluttered environments. The learned policy solves the planning and control problem simultaneously online to account for disturbances, thus achieving much higher robustness. The presented method achieves 100% success rate of flying minimum-time policies without collision, while traditional planning and control approaches achieve only 40%. We show the approach in real-world flight with speeds reaching 42 km/h and accelerates up to 3.6g.
References
A Comparative Study of Nonlinear MPC and Differential-Flatness-Based Control for Quadrotor Agile Flight
Accurate trajectory tracking control for quadrotors is essential for safe navigation in cluttered environments. However, this is challenging in agile flights due to nonlinear dynamics, complex aerodynamic effects, and actuation constraints. Our work empirically compares two state-of-the-art control frameworks: the nonlinear-model-predictive controller (NMPC) and the differential-flatness-based controller (DFBC), by tracking a wide variety of agile trajectories at speeds up to 72km/h. The comparisons are performed in both simulation and real-world environments to systematically evaluate both methods from the aspect of tracking accuracy, robustness, and computational efficiency. We show the superiority of NMPC in tracking dynamically infeasible trajectories, at the cost of higher computation time and risk of numerical convergence issues. For both methods, we also quantitatively study the effect of adding an inner-loop controller using the incremental nonlinear dynamic inversion (INDI) method, and the effect of adding an aerodynamic drag model. Our real-world experiments, performed in one of the world's largest motion capture systems, demonstrate more than 78% tracking error reduction of both NMPC and DFBC, indicating the necessity of using an inner-loop controller and aerodynamic drag model for agile trajectory tracking.
References

Model Predictive Contouring Control for Time-Optimal Quadrotor Flight
We tackle the problem of flying time-optimal trajectories through multiple waypoints with quadrotors. State-of-the-art solutions split the problem into a planning task - where a global, time-optimal trajectory is generated - and a control task - where this trajectory is accurately tracked. However, at the current state, generating a time-optimal trajectory that takes the full quadrotor model into account is computationally demanding (in the order of minutes or even hours). This is detrimental for replanning in presence of disturbances. We overcome this issue by solving the time-optimal planning and control problems concurrently via Model Predictive Contouring Control (MPCC). Our MPCC optimally selects the future states of the platform at runtime, while maximizing the progress along the reference path and minimizing the distance to it. We show that, even when tracking simplified trajectories, the proposed MPCC results in a path that approaches the true time-optimal one, and which can be generated in real-time. We validate our approach in the real-world, where we show that our method outperforms both the current state-of-the-art and a world-class human pilot in terms of lap time achieving speeds of up to 60 km/h.
References

Visual Attention Prediction Improves Performance of Autonomous Drone Racing Agents

Humans race drones faster than neural networks trained for end-to-end autonomous flight. This may be related to the ability of human pilots to select task-relevant visual information effectively. This work investigates whether neural networks capable of imitating human eye gaze behavior and attention can improve neural network performance for the challenging task of vision-based autonomous drone racing. We hypothesize that gaze-based attention prediction can be an efficient mechanism for visual information selection and decision making in a simulator-based drone racing task. We test this hypothesis using eye gaze and flight trajectory data from 18 human drone pilots to train a visual attention prediction model. We then use this visual attention prediction model to train an end-to-end controller for vision-based autonomous drone racing using imitation learning. We compare the drone racing performance of the attention-prediction controller to those using raw image inputs and image-based abstractions (i.e., feature tracks). Comparing success rates for completing a challenging race track by autonomous flight, our results show that the attention-prediction based controller (88% success rate) outperforms the RGB-image (61% success rate) and feature-tracks (55% success rate) controller baselines. Furthermore, visual attention-prediction and feature-track based models showed better generalization performance than image-based models when evaluated on hold-out reference trajectories. Our results demonstrate that human visual attention prediction improves the performance of autonomous vision-based drone racing agents and provides an essential step towards vision-based, fast, and agile autonomous flight that eventually can reach and even exceed human performances.
References
Minimum-Time Quadrotor Waypoint Flight in Cluttered Environments
Planning minimum-time trajectories in cluttered environments with obstacles is a challenging problem. The quadrotor has to fly on the edge of its capabilities and, at the same time, avoid obstacles. However, planning such trajectories is vital for applications like search and rescue, where after disasters, it is essential to search for survivors as quickly as possible. Nevertheless, planning minimum-time trajectories in cluttered environments has not been addressed before in its entirety, using the full quadrotor model that can leverage the full actuation of the platform. We address this problem by using a hierarchical, sampling-based method with an incrementally more complex quadrotor model. The proposed method outperforms all related baselines in cluttered environments and is further validated in real-world flights at over 60km/h.
References

A Benchmark Comparison of Learned Control Policies for Agile Quadrotor Flight
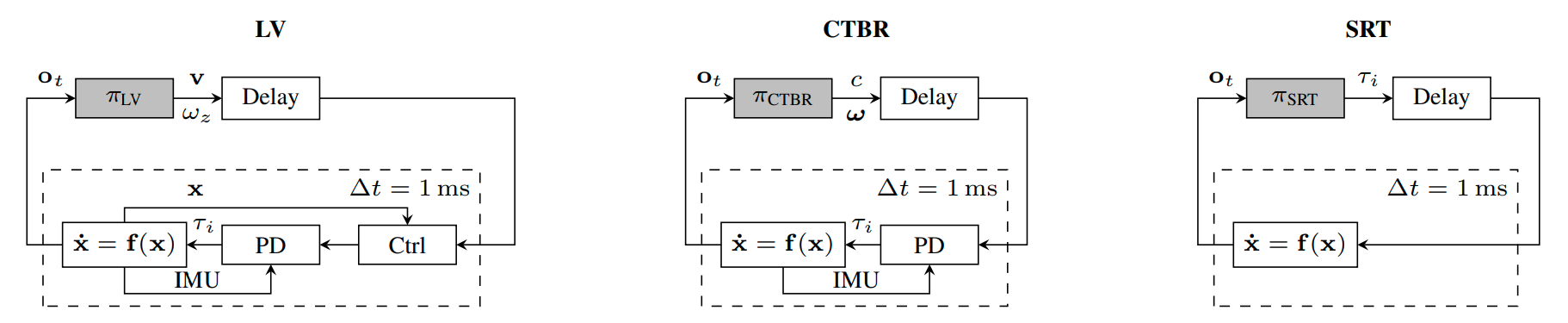
Quadrotors are highly nonlinear dynamical systems that require carefully tuned controllers to be pushed to their physical limits. Recently, learning-based control policies have been proposed for quadrotors, as they would potentially allow learning direct mappings from high-dimensional raw sensory observations to actions. Due to sample inefficiency, training such learned controllers on the real platform is impractical or even impossible. Training in simulation is attractive but requires to transfer policies between domains, which demands trained policies to be robust to such domain gap. In this work, we make two contributions: (i) we perform the first benchmark comparison of existing learned control policies for agile quadrotor flight and show that training a control policy that commands body-rates and thrust results in more robust sim-to-real transfer compared to a policy that directly specifies individual rotor thrusts, (ii) we demonstrate for the first time that such a control policy trained via deep reinforcement learning can control a quadrotor in real-world experiments at speeds over 45km/h.
References
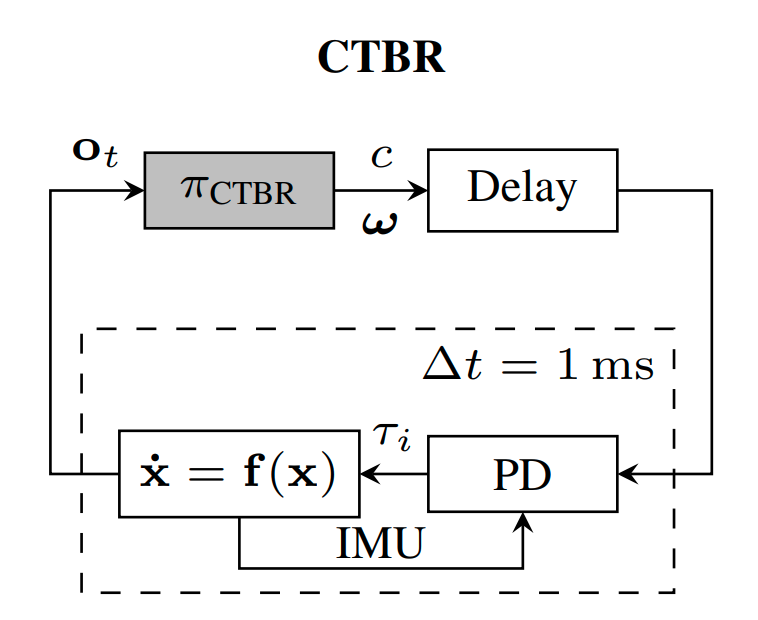
Policy Search for Model Predictive Control with Application to Agile Drone Flight
Policy Search and Model Predictive Control (MPC) are two different paradigms for robot control: policy search has the strength of automatically learning complex policies using experienced data, while MPC can offer optimal control performance using models and trajectory optimization. An open research question is how to leverage and combine the advantages of both approaches. In this work, we provide an answer by using policy search for automatically choosing high-level decision variables for MPC, which leads to a novel policy-search-for-model-predictive-control framework. Specifically, we formulate the MPC as a parameterized controller, where the hard-to-optimize decision variables are represented as high-level policies. Such a formulation allows optimizing policies in a self-supervised fashion. We validate this framework by focusing on a challenging problem in agile drone flight: flying a quadrotor through fast-moving gates. Experiments show that our controller achieves robust and real-time control performance in both simulation and the real world. The proposed framework offers a new perspective for merging learning and control.
References

Policy Search for Model Predictive Control with Application to Agile Drone Flight
IEEE Transactions on Robotics (T-RO), 2022.
Expertise Affects Drone Racing Performance

First-person view drone racing has become a popular televised sport. However, very little is known about the perceptual and motor skills of professional drone racing pilots. A better understanding of these skills may inform path planning and control algorithms for autonomous multirotor flight. By using a real-world drone racing track and a large-scale position tracking system, we compare the drone racing performance of five professional and five beginner pilots. Results show that professional pilots consistently outperform beginner pilots by achieving faster lap times, higher velocity, and more efficiently executing the challenging maneuvers. Trajectory analysis shows that experienced pilots choose more optimal racing lines than beginner pilots. Our results provide strong evidence for a contribution of expertise to performances in real-world human-piloted drone racing. We discuss the implications of these results for future work on autonomous fast and agile flight.
References
Performance, Precision, and Payloads: Adaptive Nonlinear MPC for Quadrotors
Agile quadrotor flight in challenging environments has the potential to revolutionize shipping, transportation, and search and rescue applications. Nonlinear model predictive control (NMPC) has recently shown promising results for agile quadrotor control, but relies on highly accurate models for maximum performance. Hence, model uncertainties in the form of unmodeled complex aerodynamic effects, varying payloads and parameter mismatch will degrade overall system performance. In this paper, we propose L1-NMPC, a novel hybrid adaptive NMPC to learn model uncertainties online and immediately compensate for them, drastically improving performance over the non-adaptive baseline with minimal computational overhead. Our proposed architecture generalizes to many different environments from which we evaluate wind, unknown payloads, and highly agile flight conditions. The proposed method demonstrates immense flexibility and robustness, with more than 90% tracking error reduction over non-adaptive NMPC under large unknown disturbances and without any gain tuning. In addition, the same controller with identical gains can accurately fly highly agile racing trajectories exhibiting top speeds of 70 km/h, offering tracking performance improvements of around 50% relative to the non-adaptive NMPC baseline.
References

Time-Optimal Planning for Quadrotor Waypoint Flight
Quadrotors are among the most agile flying robots. However, planning time-optimal trajectories at the actuation limit through multiple waypoints remains an open problem. This is crucial for applications such as inspection, delivery, search and rescue, and drone racing. Early works used polynomial trajectory formulations, which do not exploit the full actuator potential because of their inherent smoothness. Recent works resorted to numerical optimization but require waypoints to be allocated as costs or constraints at specific discrete times. However, this time allocation is a priori unknown and renders previous works incapable of producing truly time-optimal trajectories. To generate truly time-optimal trajectories, we propose a solution to the time allocation problem while exploiting the full quadrotorâs actuator potential. We achieve this by introducing a formulation of progress along the trajectory, which enables the simultaneous optimization of the time allocation and the trajectory itself. We compare our method against related approaches and validate it in real-world flights in one of the worldâs largest motion-capture systems, where we outperform human expert drone pilots in a drone-racing task.
References

NeuroBEM: Hybrid Aerodynamic Quadrotor Model
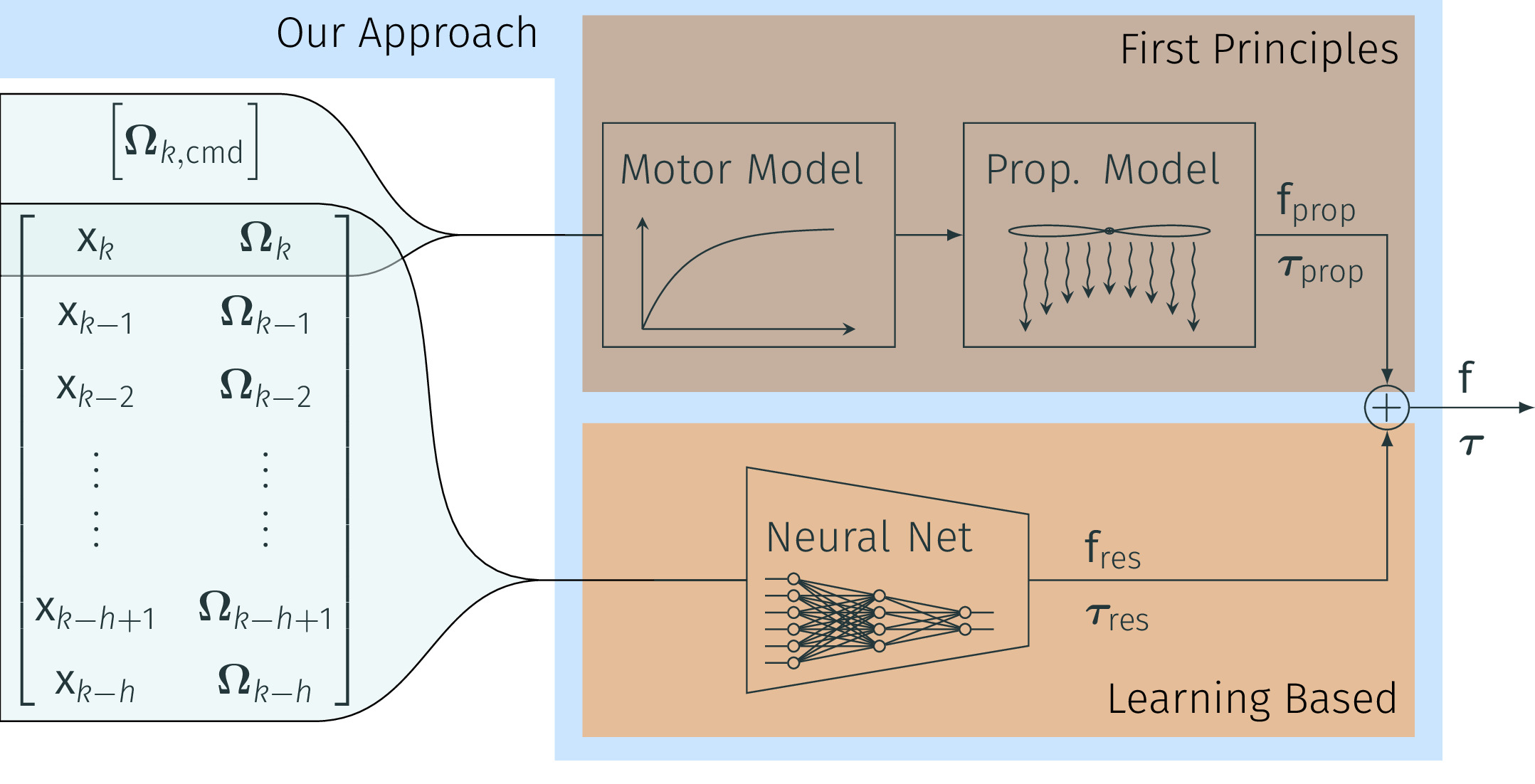
Quadrotors are extremely agile, so much in fact, that classic first-principle-models come to their limits. Aerodynamic effects, while insignificant at low speeds, become the dominant model defect during high speeds or agile maneuvers. Accurate modeling is needed to design robust high-performance control systems and enable flying close to the platform's physical limits. We propose a hybrid approach fusing first principles and learning to model quadrotors and their aerodynamic effects with unprecedented accuracy. First principles fail to capture such aerodynamic effects, rendering traditional approaches inaccurate when used for simulation or controller tuning. Data-driven approaches try to capture aerodynamic effects with blackbox modeling, such as neural networks; however, they struggle to robustly generalize to arbitrary flight conditions. Our hybrid approach unifies and outperforms both first-principles blade-element theory and learned residual dynamics. It is evaluated in one of the world's largest motion-capture systems, using autonomous-quadrotor-flight data at speeds up to 65km/h. The resulting model captures the aerodynamic thrust, torques, and parasitic effects with astonishing accuracy, outperforming existing models with 50% reduced prediction errors, and shows strong generalization capabilities beyond the training set.
References

NeuroBEM: Hybrid Aerodynamic Quadrotor Model
Robotics: Science and Systems (RSS), 2021.
Autonomous Drone Racing with Deep Reinforcement Learning
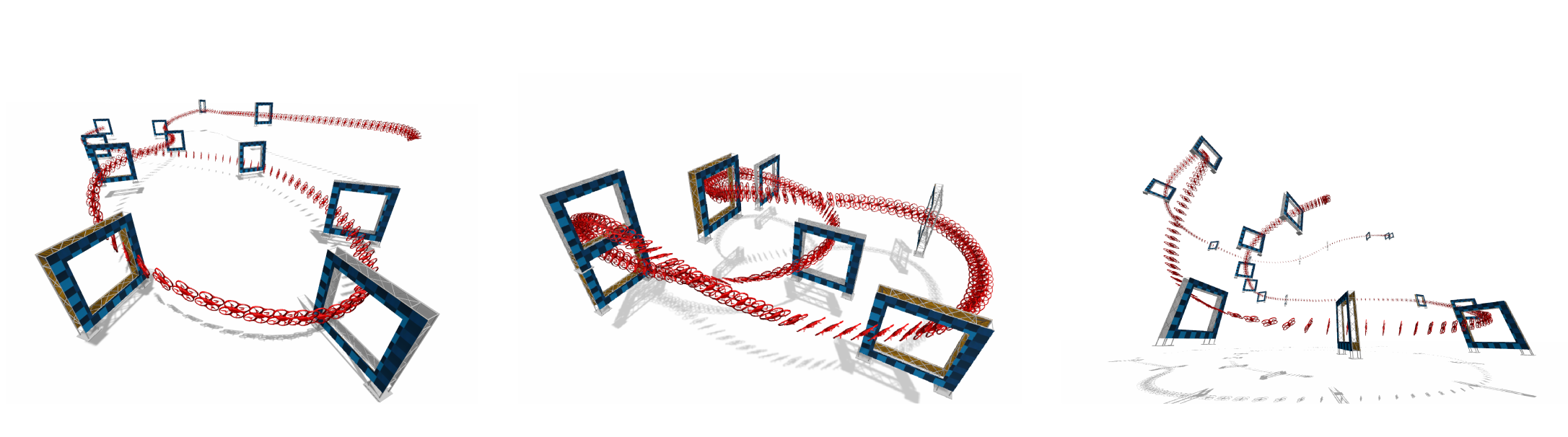
In many robotic tasks, such as drone racing, the goal is to travel through a set of waypoints as fast as possible. A key challenge for this task is planning the minimum-time trajectory, which is typically solved by assuming perfect knowledge of the waypoints to pass in advance. The resulting solutions are either highly specialized for a single-track layout, or suboptimal due to simplifying assumptions about the platform dynamics. In this work, a new approach to minimum-time trajectory generation for quadrotors is presented. Leveraging deep reinforcement learning and relative gate observations, this approach can adaptively compute near-time-optimal trajectories for random track layouts. Our method exhibits a significant computational advantage over approaches based on trajectory optimization for non-trivial track configurations. The proposed approach is evaluated on a set of race tracks in simulation and the real world, achieving speeds of up to 17 m/s with a physical quadrotor.
References
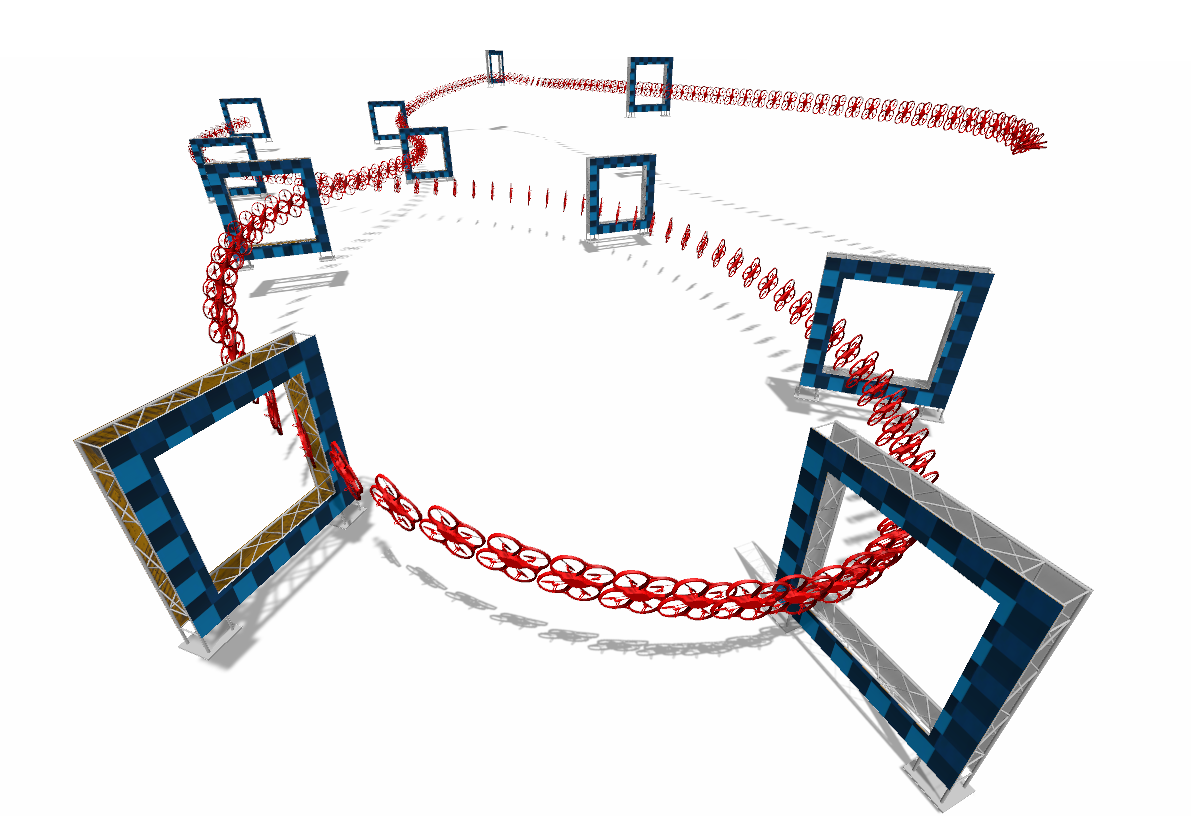
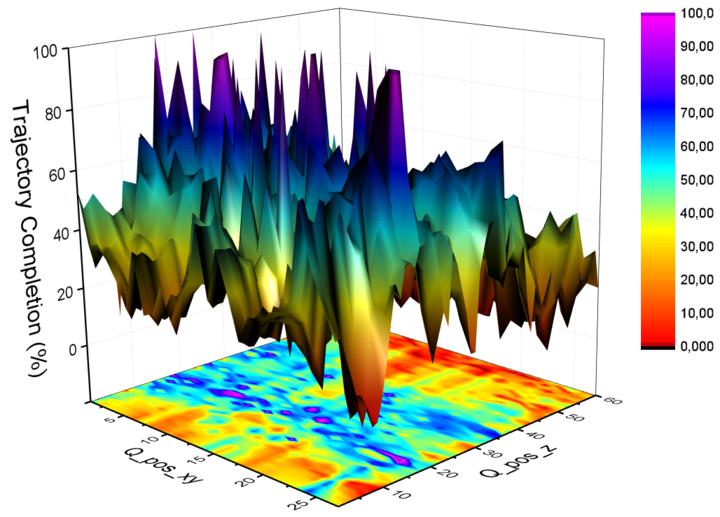
AutoTune: Controller Tuning for High-Speed Flight

Due to noisy actuation and external disturbances, tuning controllers for high-speed flight is very challenging. In this paper, we ask the following questions: How sensitive are controllers to tuning when tracking high-speed maneuvers? What algorithms can we use to automatically tune them? To answer the first question, we study the relationship between parameters and performance and find out that the faster the maneuver, the more sensitive a controller becomes to its parameters. To answer the second question, we review existing methods for controller tuning and discover that prior works often perform poorly on the task of high-speed flight. Therefore, we propose AutoTune, a sampling-based tuning algorithm specifically tailored to high-speed flight. In contrast to previous work, our algorithm does not assume any prior knowledge of the drone or its optimization function and can deal with the multi-modal characteristics of the parameters' optimization space. We thoroughly evaluate AutoTune both in simulation and in the physical world. In our experiments, we outperform existing tuning algorithms by up to 90\% in trajectory completion. The resulting controllers are tested in the AirSim Game of Drones competition, where we outperform the winner by up to 25\% in lap-time. Finally, we show that AutoTune improves tracking error when flying a physical platform with respect to parameters tuned by a human expert.
References
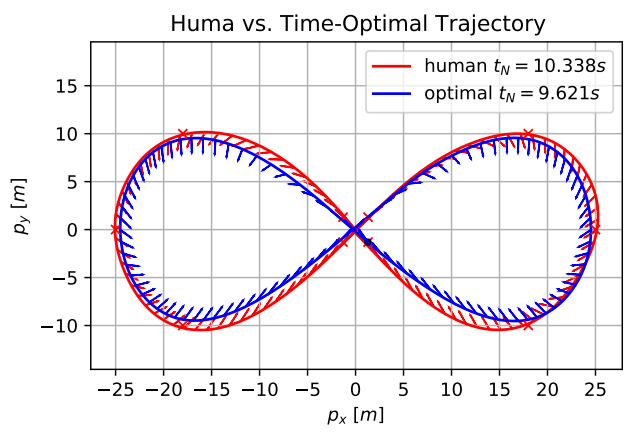
Human-Piloted Drone Racing: Visual Processing and Control

Humans race drones faster than algorithms, despite being limited to a fixed camera angle, body rate control, and response latencies in the order of hundreds of milliseconds. A better understanding of the ability of human pilots of selecting appropriate motor commands from highly dynamic visual information may provide key insights for solving current challenges in vision-based autonomous navigation. This paper investigates the relationship between human eye movements, control behavior, and flight performance in a drone racing task. We collected a multimodal dataset from 21 experienced drone pilots using a highly realistic drone racing simulator, also used to recruit professional pilots. Our results show task-specific improvements in drone racing performance over time. In particular, we found that eye gaze tracks future waypoints (i.e., gates), with first fixations occurring on average 1.5 seconds and 16 meters before reaching the gate. Moreover, human pilots consistently looked at the inside of the future flight path for lateral (i.e., left and right turns) and vertical maneuvers (i.e., ascending and descending). Finally, we found a strong correlation between pilots eye movements and the commanded direction of quadrotor flight, with an average visual-motor response latency of 220 ms. These results highlight the importance of coordinated eye movements in human-piloted drone racing. We make our dataset publicly available.
References
Data-Driven MPC for Quadrotors
Aerodynamic forces render accurate high-speed trajectory tracking with quadrotors extremely challenging. These complex aerodynamic effects become a significant disturbance at high speeds, introducing large positional tracking errors, and are extremely difficult to model. To fly at high speeds, feedback control must be able to account for these aerodynamic effects in real-time. This necessitates a modelling procedure that is both accurate and efficient to evaluate. Therefore, we present an approach to model aerodynamic effects using Gaussian Processes, which we incorporate into a Model Predictive Controller to achieve efficient and precise real-time feedback control, leading to up to 70% reduction in trajectory tracking error at high speeds. We verify our method by extensive comparison to a state-of-the-art linear drag model in synthetic and real-world experiments at speeds of up to 14m/s and accelerations beyond 4g.
References

Flightmare: A Flexible Quadrotor Simulator
Currently available quadrotor simulators have a rigid and highly-specialized structure: either are they really fast, physically accurate, or photo-realistic. In this work, we propose a paradigm-shift in the development of simulators: moving the trade-off between accuracy and speed from the developers to the end-users. We release a new modular quadrotor simulator: Flightmare. Flightmare is composed of two main components: a configurable rendering engine built on Unity and a flexible physics engine for dynamics simulation. Those two components are totally decoupled and can run independently from each other. Flightmare comes with several desirable features: (i) a large multi-modal sensor suite, including an interface to extract the 3D point-cloud of the scene; (ii) an API for reinforcement learning which can simulate hundreds of quadrotors in parallel; and (iii) an integration with a virtual-reality headset for interaction with the simulated environment. Flightmare can be used for various applications, including path-planning, reinforcement learning, visual-inertial odometry, deep learning, human-robot interaction, etc.
References

Flightmare: A Flexible Quadrotor Simulator
Conference on Robot Learning (CoRL), 2020
Time-Optimal Quadrotor Trajectories
In many mobile robotics scenarios, such as drone racing, the goal is to generate a trajectory that passes through multiple waypoints in minimal time. This problem is referred to as time-optimal planning. State-of-the-art approaches either use polynomial trajectory formulations, which are suboptimal due to their smoothness, or numerical optimization, which requires waypoints to be allocated as costs or constraints to specific discrete-time nodes. For time-optimal planning, this time-allocation is a priori unknown and renders traditional approaches incapable of producing truly time-optimal trajectories. We introduce a novel formulation of progress bound to waypoints by a complementarity constraint. While the progress variables indicate the completion of a waypoint, change of this progress is only allowed in local proximity to the waypoint via complementary constraints. This enables the simultaneous optimization of the trajectory and the time-allocation of the waypoints. To the best of our knowledge, this is the first approach allowing for truly time-optimal trajectory planning for quadrotors and other systems. We perform and discuss evaluations on optimality and convexity, compare to other related approaches, and qualitatively to an expert-human baseline.
References
AlphaPilot: Autonomous Drone Racing
We present a novel system for autonomous, vision-based drone racing combining learned data abstraction, nonlinear filtering, and time-optimal trajectory planning. The system has successfully been deployed at the first autonomous drone racing world championship: the 2019 AlphaPilot Challenge. Contrary to traditional drone racing systems, that only detect the next gate, our approach makes use of any visible gate and takes advantage of multiple, simultaneous gate detections to compensate for drift in the state estimate and build a global map of the gates. The global map and drift-compensated state estimate allow the drone to navigate through the race course even when the gates are not immediately visible and further enable to plan a near time-optimal path through the race course in real time based on approximate drone dynamics. The proposed system has been demonstrated to successfully guide the drone through tight race courses reaching speeds up to 8m/s and has led to rank second at the 2019 AlphaPilot Challenge.
References

AlphaPilot: Autonomous Drone Racing
Robotics: Science and Systems (RSS), 2020
Best Systems Paper Award!
Towards Low-Latency High-Bandwidth Control of Quadrotors using Event Cameras
Event cameras are a promising candidate to enable high speed vision-based control due to their low sensor latency and high temporal resolution. However, purely event-based feedback has yet to be used in the control of drones. In this work, a first step towards implementing low-latency high-bandwidth control of quadrotors using event cameras is taken. In particular, this paper addresses the problem of one-dimensional attitude tracking using a dualcopter platform equipped with an event camera. The event-based state estimation consists of a modified Hough transform algorithm combined with a Kalman filter that outputs the roll angle and angular velocity of the dualcopter relative to a horizon marked by a black-and-white disk. The estimated state is processed by a proportional-derivative attitude control law that computes the rotor thrusts required to track the desired attitude. The proposed attitude tracking scheme shows promising results of event-camera-driven closed loop control: the state estimator performs with an update rate of 1 kHz and a latency determined to be 12 ms, enabling attitude tracking at speeds of over 1600 degrees per second.
References

Towards Low-Latency High-Bandwidth Control of Quadrotors using Event Cameras
IEEE International Conference on Robotics and Automation (ICRA), 2020
Deep Drone Racing: From Simulation to Reality with Domain Randomization
Dynamically changing environments, unreliable state estimation, and operation under severe resource constraints are fundamental challenges for robotics, which still limit the deployment of small autonomous drones. We address these challenges in the context of autonomous, vision-based drone racing in dynamic environments. A racing drone must traverse a track with possibly moving gates at high speed. We enable this functionality by combining the performance of a state-of-the-art path-planning and control system with the perceptual awareness of a convolutional neural network (CNN). The CNN directly maps raw images to a desired waypoint and speed. Given the CNN output, the planner generates a short minimum-jerk trajectory segment that is tracked by a model-based controller to actuate the drone towards the waypoint. The resulting modular system has several desirable features: (i) it can run fully on-board, (ii) it does not require globally consistent state estimation, and (iii) it is both platform and domain independent. We extensively test the precision and robustness of our system, both in simulation and on a physical platform. In both domains, our method significantly outperforms the prior state of the art. In order to understand the limits of our approach, we additionally compare against professional human drone pilots with different skill levels.
References


Beauty and the Beast: Optimal Methods Meet Learning for Drone Racing
Autonomous micro aerial vehicles still struggle with fast and agile maneuvers, dynamic environments, imperfect sensing, and state estimation drift. Autonomous drone racing brings these challenges to the fore. Human pilots can fly a previously unseen track after a handful of practice runs. In contrast, state-of-the-art autonomous navigation algorithms require either a precise metric map of the environment or a large amount of training data collected in the track of interest. To bridge this gap, we propose an approach that can fly a new track in a previously unseen environment without a precise map or expensive data collection. Our approach represents the global track layout with coarse gate locations, which can be easily estimated from a single demonstration flight. At test time, a convolutional network predicts the poses of the closest gates along with their uncertainty. These predictions are incorporated by an extended Kalman filter to maintain optimal maximum-a-posteriori estimates of gate locations. This allows the framework to cope with misleading high-variance estimates that could stem from poor observability or lack of visible gates. Given the estimated gate poses, we use model predictive control to quickly and accurately navigate through the track. We conduct extensive experiments in the physical world, demonstrating agile and robust flight through complex and diverse previously-unseen race tracks. The presented approach was used to win the IROS 2018 Autonomous Drone Race Competition, outracing the second-placing team by a factor of two.
References

The UZH-FPV Drone Racing Dataset
Despite impressive results in visual-inertial state estimation in recent years, high speed trajectories with six degree of freedom motion remain challenging for existing estimation algorithms. Aggressive trajectories feature large accelerations and rapid rotational motions, and when they pass close to objects in the environment, this induces large apparent motions in the vision sensors, all of which increase the difficulty in estimation. Existing benchmark datasets do not address these types of trajectories, instead focusing on slow speed or constrained trajectories, targeting other tasks such as inspection or driving.
We introduce the UZH-FPV Drone Racing dataset, consisting of over 27 sequences, with more than 10 km of flight distance, captured on a first-person-view (FPV) racing quadrotor flown by an expert pilot. The dataset features camera images, inertial measurements, event-camera data, and precise ground truth poses. These sequences are faster and more challenging, in terms of apparent scene motion, than any existing dataset. Our goal is to enable advancement of the state of the art in aggressive motion estimation by providing a dataset that is beyond the capabilities of existing state estimation algorithms.
References

Are We Ready for Autonomous Drone Racing? The UZH-FPV Drone Racing Dataset
IEEE International Conference on Robotics and Automation (ICRA), 2019.