



Autonomous Driving
Autonomous driving has emerged as a transformative technology, but its deployment is often limited to ideal conditions. Addressing challenges like low light and high dynamic range environments, our research integrates advanced sensory systems and hybrid perception techniques to push the boundaries of perception and control. By combining event cameras with traditional frame-based sensors, we balance temporal resolution, efficiency, and accuracy, reducing latency and computational load while maintaining high performance. This work enables safer and more reliable autonomous driving in complex, real-world scenarios.
LiDAR Registration with Visual Foundation Models
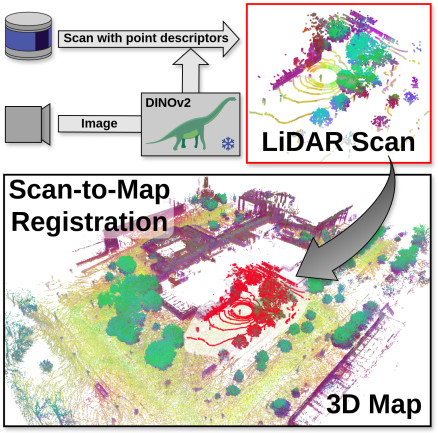
In this work, we present a robust LiDAR registration method using DINOv2 features extracted from surround-view images as point descriptors. Unlike traditional handcrafted or learned descriptors, this approach effectively handles domain shifts, seasonal changes, and structural variations in point clouds. When combined with standard registration methods like RANSAC or ICP, it achieves accurate 6DoF alignment between LiDAR scans and 3D maps, even across long time gaps. The method is simple, does not require retraining, and works with both sparse and dense data. It significantly outperforms existing techniques, with up to +24.8 and +17.3 gains in registration recall on the NCLT and Oxford Radar RobotCar datasets, respectively. For more details, check out our paper, code, and video!
References
Maximizing Asynchronicity in Event-based Neural Networks
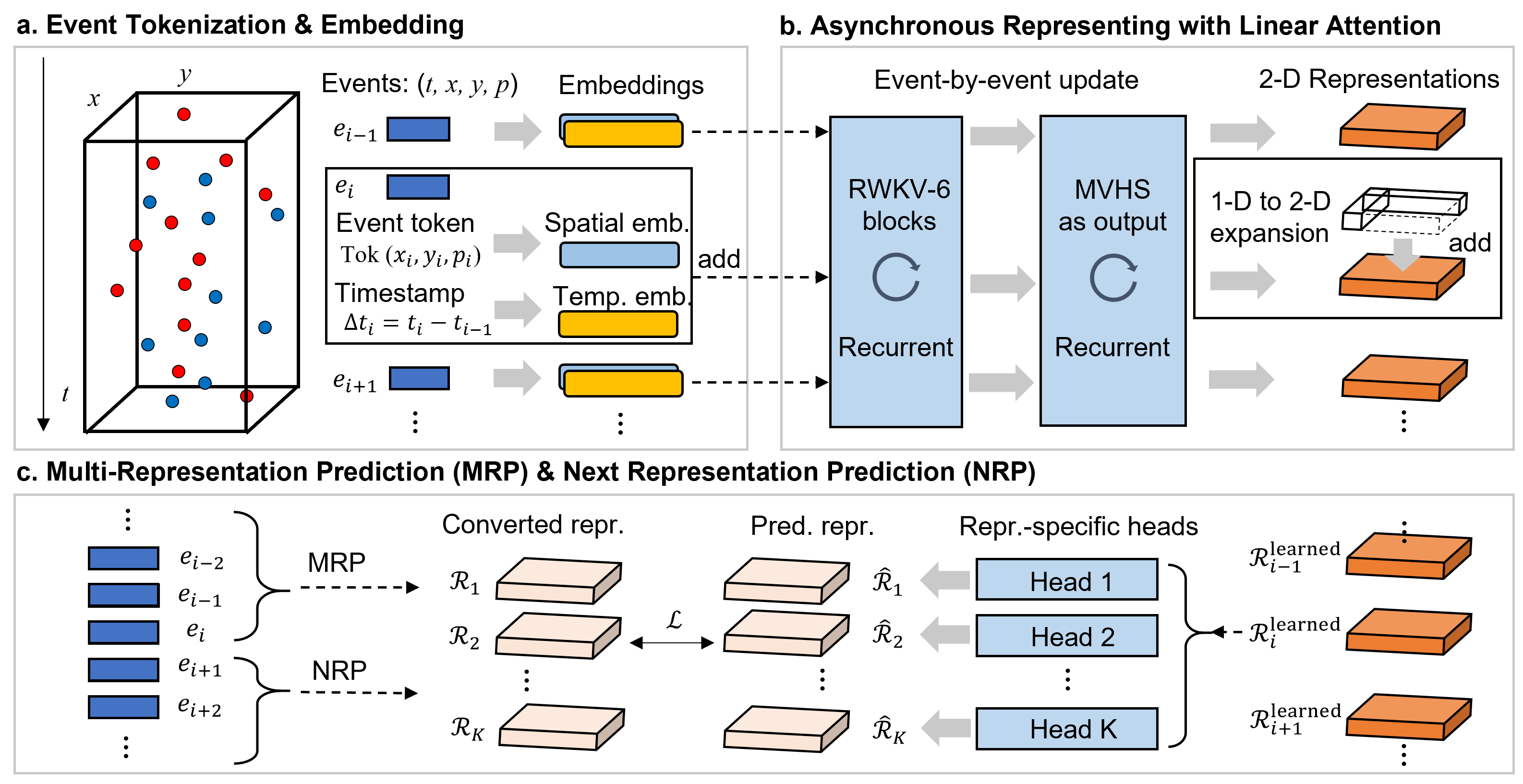
Event cameras deliver visual data with high temporal resolution, low latency, and minimal redundancy, yet their asynchronous, sparse sequential nature challenges standard tensor-based machine learning (ML). While the recent asynchronous-to-synchronous (A2S) paradigm aims to bridge this gap by asynchronously encoding events into learned representations for ML pipelines, existing A2S approaches often sacrifice representation expressivity and generalizability compared to dense, synchronous methods. This paper introduces EVA (EVent Asynchronous representation learning), a novel A2S framework to generate highly expressive and generalizable event-by-event representations. Inspired by the analogy between events and language, EVA uniquely adapts advances from language modeling in linear attention and self-supervised learning for its construction. In demonstration, EVA outperforms prior A2S methods on recognition tasks (DVS128-Gesture and N-Cars), and represents the first A2S framework to successfully master demanding detection tasks, achieving a remarkable 47.7 mAP on the Gen1 dataset. These results underscore EVA's transformative potential for advancing real-time event-based vision applications.
References
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control

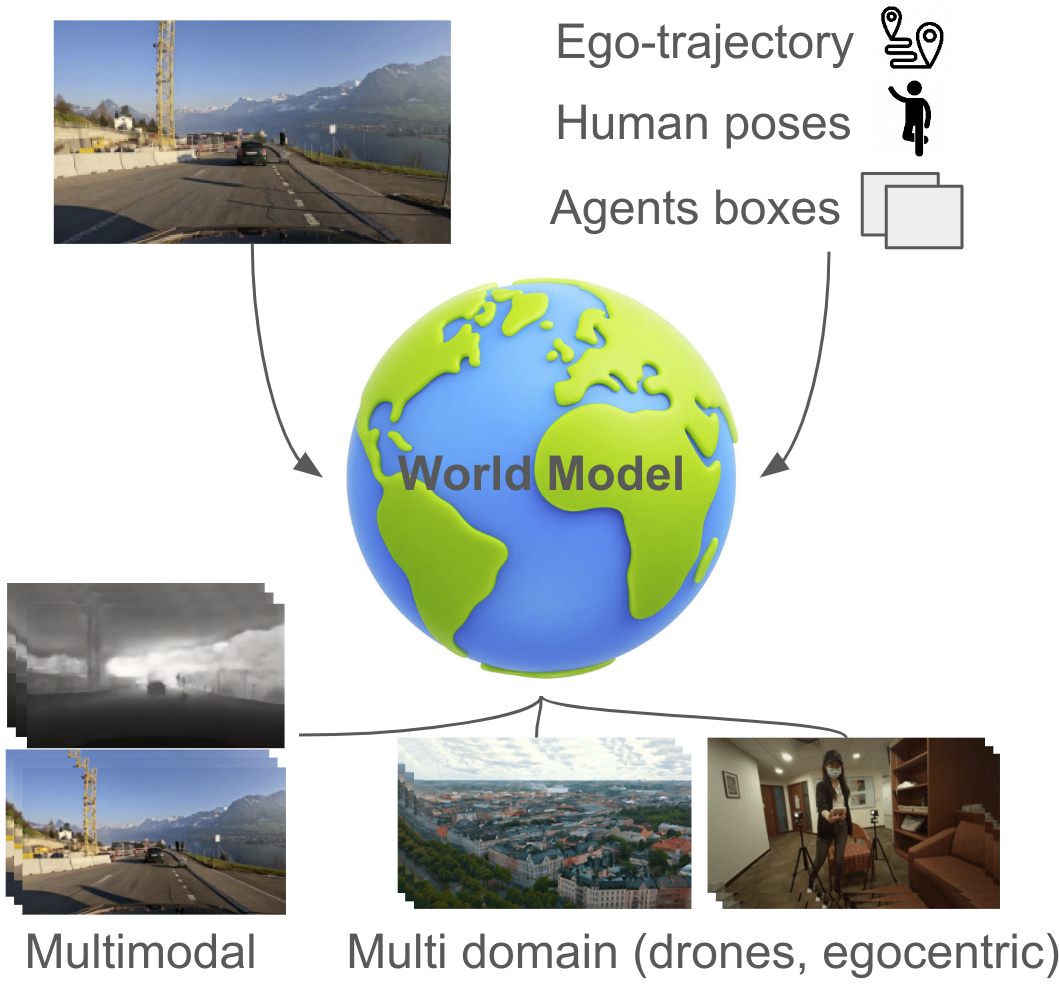
We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego- trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, egotrajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations.
References
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
ArXiv, 2024.
Low Latency Automotive Vision with Event Cameras

The computer vision algorithms used in today's advanced driver assistance systems rely on image-based RGB cameras, leading to a critical bandwidth-latency trade-off for delivering safe driving experiences. To address this, event cameras have emerged as alternative vision sensors. Event cameras measure changes in intensity asynchronously, offering high temporal resolution and sparsity, drastically reducing bandwidth and latency requirements. Despite these advantages, event camera-based algorithms are either highly efficient but lag behind image-based ones in terms of accuracy or sacrifice the sparsity and efficiency of events to achieve comparable results. To overcome this, we propose a novel hybrid event- and frame-based object detector that preserves the advantages of each modality and thus does not suffer from this tradeoff. Our method exploits the high temporal resolution and sparsity of events and the rich but low temporal resolution information in standard images to generate efficient, high-rate object detections, reducing perceptual and computational latency. We show that the use of a 20 Hz RGB camera plus an event camera can achieve the same latency as a 5,000 Hz camera with the bandwidth of a 45 Hz camera without compromising accuracy. Our approach paves the way for efficient and robust perception in edge-case scenarios by uncovering the potential of event cameras.
References

Low Latency Automotive Vision with Event Cameras
Nature, 2024.
PDF Open Access Code Training code Dataset Dataset Helper Tools YouTube
State Space Models for Event Cameras
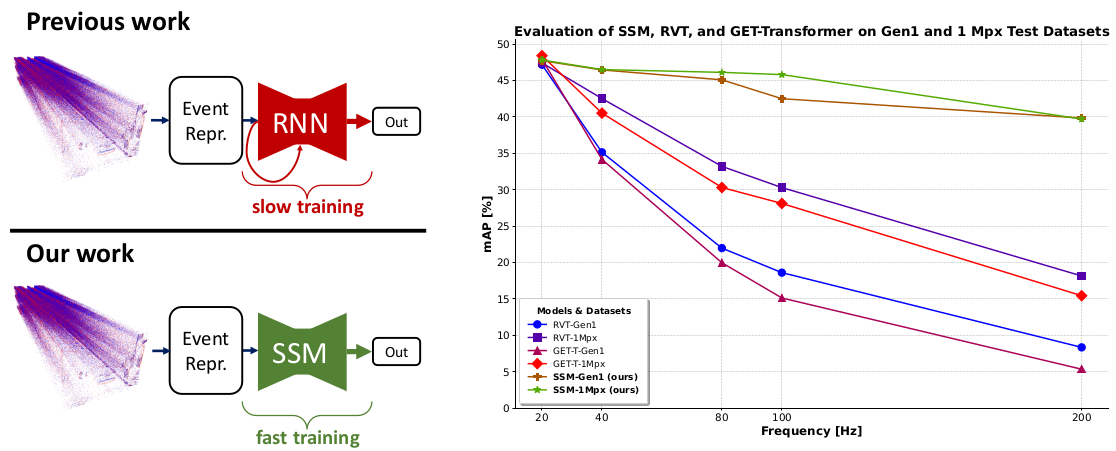
Today, state-of-the-art deep neural networks that process event-camera data first convert a temporal window of events into dense, grid-like input representations. As such, they exhibit poor generalizability when deployed at higher inference frequencies (i.e., smaller temporal windows) than the ones they were trained on. We address this challenge by introducing state-space models (SSMs) with learnable timescale parameters to event-based vision. This design adapts to varying frequencies without the need to retrain the network at different frequencies. Additionally, we investigate two strategies to counteract aliasing effects when deploying the model at higher frequencies. We comprehensively evaluate our approach against existing methods based on RNN and Transformer architectures across various benchmarks, including Gen1 and 1 Mpx event camera datasets. Our results demonstrate that SSM-based models train 33% faster and also exhibit minimal performance degradation when tested at higher frequencies than the training input. Traditional RNN and Transformer models exhibit performance drops of more than 20 mAP, with SSMs having a drop of 3.76 mAP, highlighting the effectiveness of SSMs in event-based vision tasks.
References
Seeing Behind Dynamic Occlusions with Event Cameras

Unwanted camera occlusions, such as debris, dust, rain-drops, and snow, can severely degrade the performance of computer-vision systems. Dynamic occlusions are particularly challenging because of the continuously changing pattern. Existing occlusion-removal methods currently use synthetic aperture imaging or image inpainting. However, they face issues with dynamic occlusions as these require multiple viewpoints or user-generated masks to hallucinate the background intensity. We propose a novel approach to reconstruct the background from a single viewpoint in the presence of dynamic occlusions. Our solution relies for the first time on the combination of a traditional camera with an event camera. When an occlusion moves across a background image, it causes intensity changes that trigger events. These events provide additional information on the relative intensity changes between foreground and background at a high temporal resolution, enabling a truer reconstruction of the background content. We show that our method outperforms image inpainting methods by 3dB in terms of PSNR on our dataset.
References
From Chaos Comes Order: Ordering Event Representations for Object Recognition and Detection
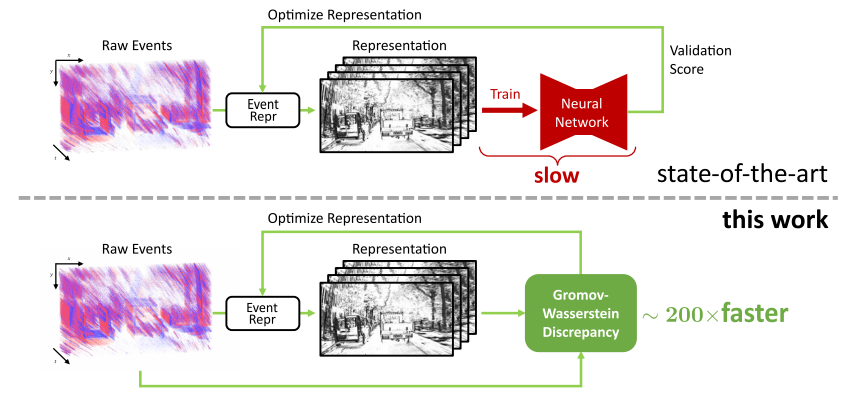
Selecting dense event representations for deep neural networks is exceedingly slow since it involves training a neural network for each representation and selecting the best one based on the validation score. In this work, we eliminate this bottleneck by selecting the representation based on the Gromov-Wasserstein Discrepancy (GWD) on the validation set. This metric is 200 times faster to compute and preserves the task performance ranking of event representations across multiple representations, network backbones, datasets and tasks. We use it to, for the first time, perform a hyperparameter search on a large family of event representations, revealing new and powerful event representations that exceed the state-of-the-art. Our optimized representations outperform existing representations by 1.7 mAP on the 1 Mpx dataset and 0.3 mAP on the Gen1 dataset, two established object detection benchmarks, and reach a 3.8% higher classification score on the mini N-ImageNet benchmark. Moreover, we outperform state-of-the-art by 2.1 mAP on Gen1 and state-of-the-art feed-forward methods by 6.0 mAP on the 1 Mpx datasets. This work opens a new unexplored field of explicit representation optimization for event-based learning.
References
Recurrent Vision Transformers for Object Detection with Event Cameras
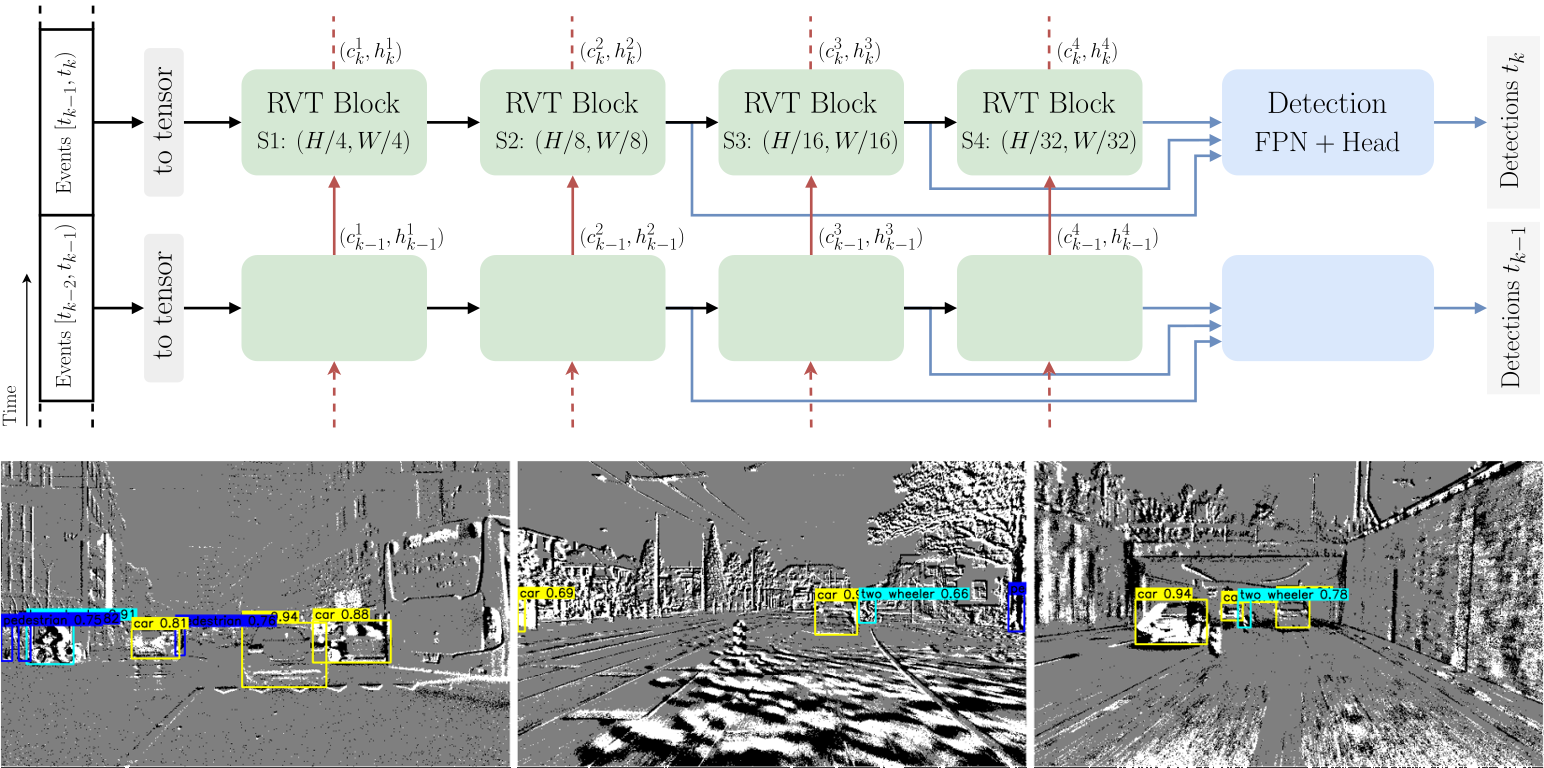
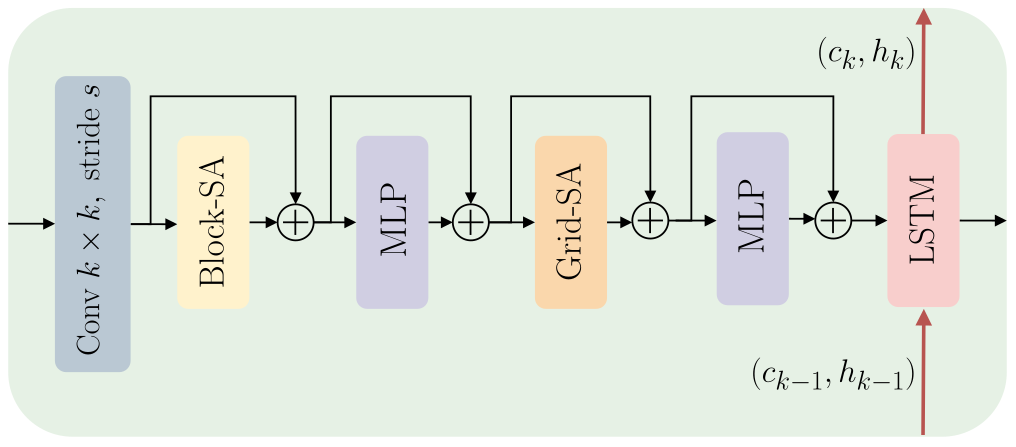
We present Recurrent Vision Transformers (RVTs), a novel backbone for object detection with event cameras. Event cameras provide visual information with sub-millisecond latency at a high-dynamic range and with strong robustness against motion blur. These unique properties offer great potential for low-latency object detection and tracking in time-critical scenarios. Prior work in event-based vision has achieved outstanding detection performance but at the cost of substantial inference time, typically beyond 40 milliseconds. By revisiting the high-level design of recurrent vision backbones, we reduce inference time by a factor of 5 while retaining similar performance. To achieve this, we explore a multi-stage design that utilizes three key concepts in each stage: First, a convolutional prior that can be regarded as a conditional positional embedding. Second, local- and dilated global self-attention for spatial feature interaction. Third, recurrent temporal feature aggregation to minimize latency while retaining temporal information. RVTs can be trained from scratch to reach state-of-the-art performance on event-based object detection - achieving an mAP of 47.2% on the Gen1 automotive dataset. At the same time, RVTs offer fast inference (12 ms on a T4 GPU) and favorable parameter efficiency (5 times fewer than prior art). Our study brings new insights into effective design choices that could be fruitful for research beyond event-based vision.
References
Pushing the Limits of Asynchronous Graph-based Object Detection with Event Cameras
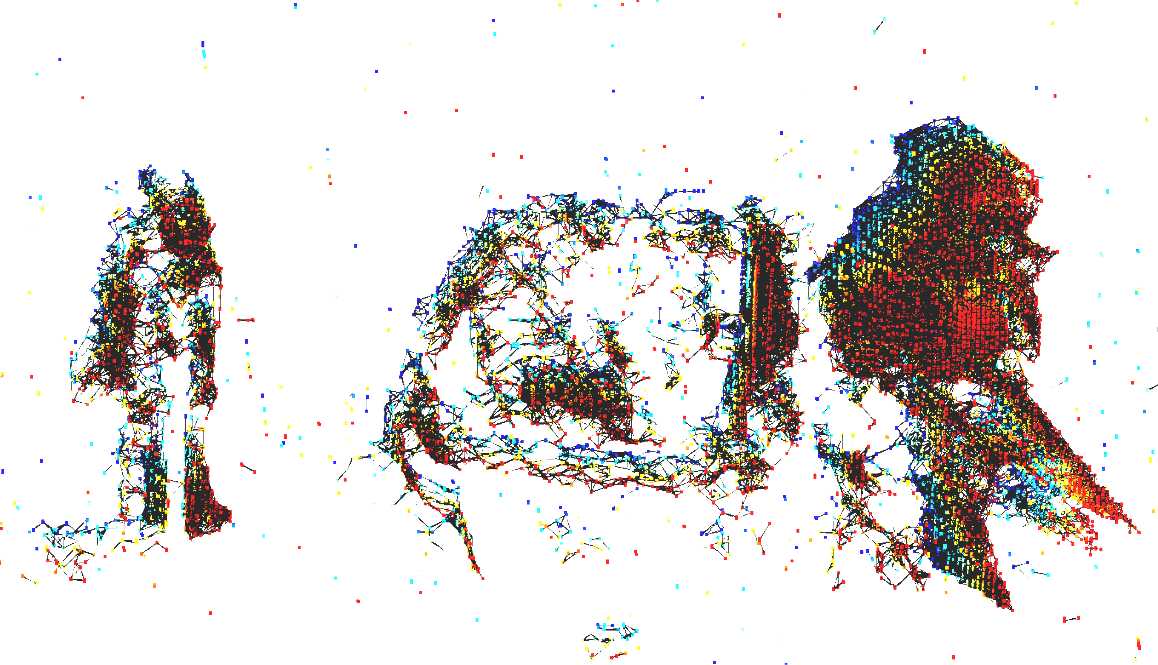
State-of-the-art machine-learning methods for event cameras treat events as dense representations and process them with conventional deep neural networks. Thus, they fail to maintain the sparsity and asynchronous nature of event data, thereby imposing significant computation and latency constraints on downstream systems. A recent line of work tackles this issue by modeling events as spatiotemporally evolving graphs that can be efficiently and asynchronously processed using graph neural networks. These works showed impressive computation reductions, yet their accuracy is still limited by the small scale and shallow depth of their network, both of which are required to reduce computation. In this work, we break this glass ceiling by introducing several architecture choices which allow us to scale the depth and complexity of such models while maintaining low computation. On object detection tasks, our smallest model shows up to 3.7 times lower computation, while outperforming state-of-the-art asynchronous methods by 7.4 mAP. Even when scaling to larger model sizes, we are 13% more efficient than state-of-the-art while outperforming it by 11.5 mAP. As a result, our method runs 3.7 times faster than a dense graph neural network, taking only 8.4 ms per forward pass. This opens the door to efficient, and accurate object detection in edge-case scenarios.
References
Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Cars
Event cameras are bio-inspired vision sensors that naturally capture the dynamics of a scene, filtering out redundant information. This paper presents a deep neural network approach that unlocks the potential of event cameras on a challenging motion-estimation task: prediction of a vehicle's steering angle. To make the best out of this sensor-algorithm combination, we adapt state-of-the-art convolutional architectures to the output of event sensors and extensively evaluate the performance of our approach on a publicly available large scale event-camera dataset (~1000 km). We present qualitative and quantitative explanations of why event cameras allow robust steering prediction even in cases where traditional cameras fail, e.g. challenging illumination conditions and fast motion. Finally, we demonstrate the advantages of leveraging transfer learning from traditional to event-based vision, and show that our approach outperforms state-of-the-art algorithms based on standard cameras.
References

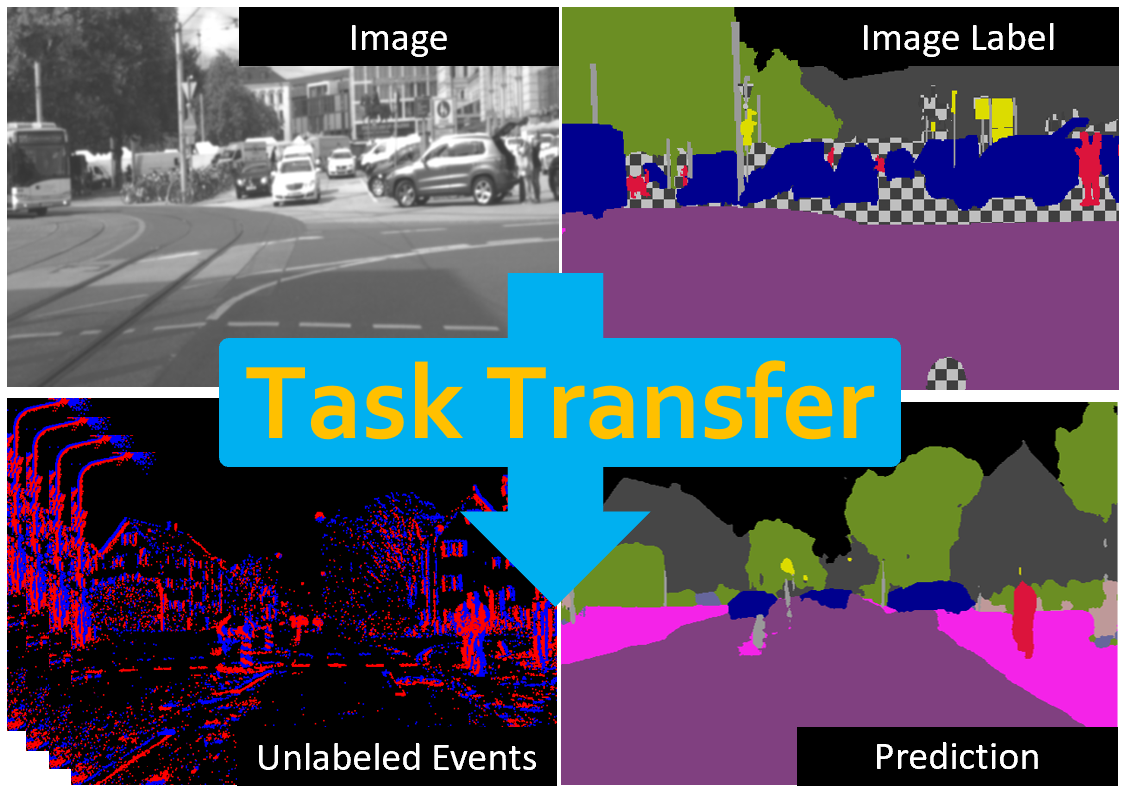
ESS: Learning Event-based Semantic Segmentation from Still Images
References
AEGNN: Asynchronous Event-based Graph Neural Networks

References

AEGNN: Asynchronous Event-based Graph Neural Networks
IEEE Conference of Computer Vision and Pattern Recognition (CVPR), 2022, New Orleans, USA.
Bridging the Gap between Events and Frames through Unsupervised Domain Adaptation
References

Event Guided Depth Sensing
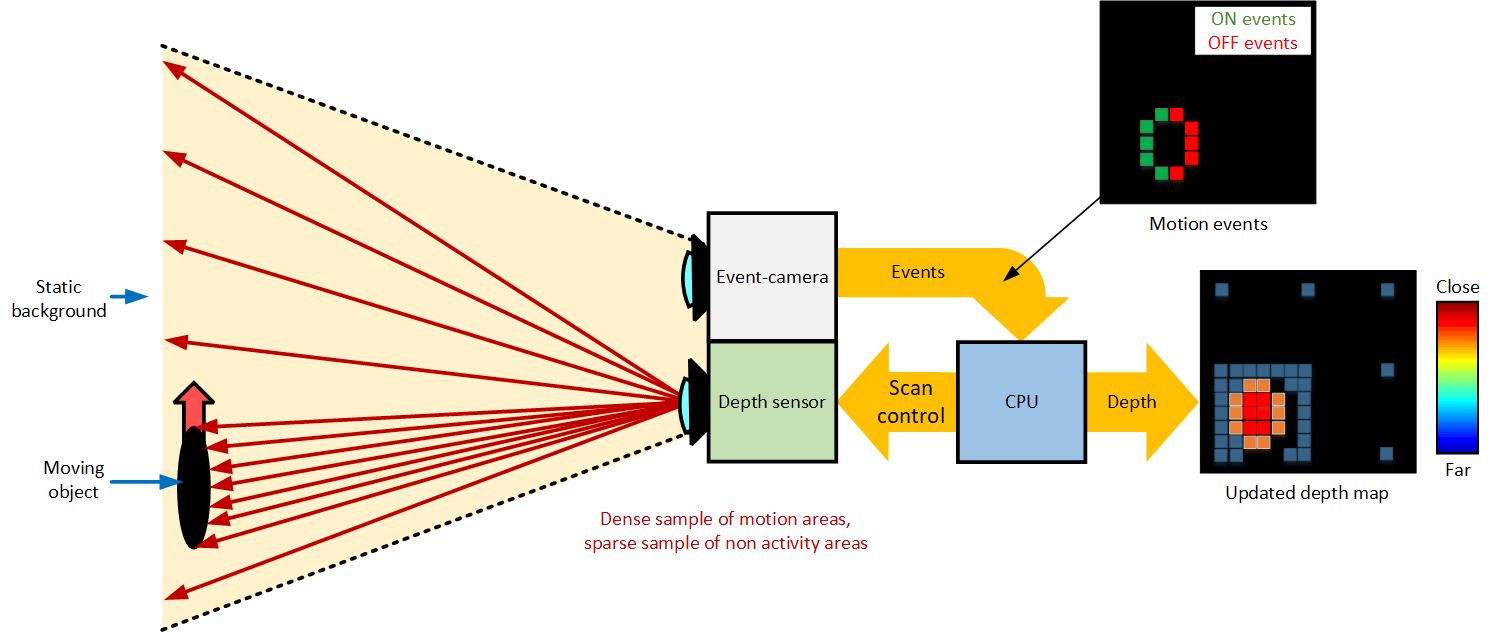
References
E-RAFT: Dense Optical Flow from Event Cameras

We propose to incorporate feature correlation and sequential processing into dense optical flow estimation from event cameras. Modern frame-based optical flow methods heavily rely on matching costs computed from feature correlation. In contrast, there exists no optical flow method for event cameras that explicitly computes matching costs. Instead, learning-based approaches using events usually resort to the U-Net architecture to estimate optical flow sparsely. Our key finding is that introducing correlation features significantly improves results compared to previous methods that solely rely on convolution layers. Compared to the state-of-the-art, our proposed approach computes dense optical flow and reduces the end-point error by 23% on MVSEC. Furthermore, we show that all existing optical flow methods developed so far for event cameras have been evaluated on datasets with very small displacement fields with a maximum flow magnitude of 10 pixels. We introduce a new real-world dataset that exhibits displacement fields with magnitudes up to 210 pixels and 3 times higher camera resolution based on this observation. Our proposed approach reduces the end-point error on this dataset by 66%.
References

DSEC: A Stereo Event Camera Dataset for Driving Scenarios

References

DSEC: A Stereo Event Camera Dataset for Driving Scenarios
IEEE Robotics and Automation Letters (RA-L), 2021.
PDF Project Page and Dataset Code Teaser ICRA 2021 Video Pitch Slides
Combining Events and Frames using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction
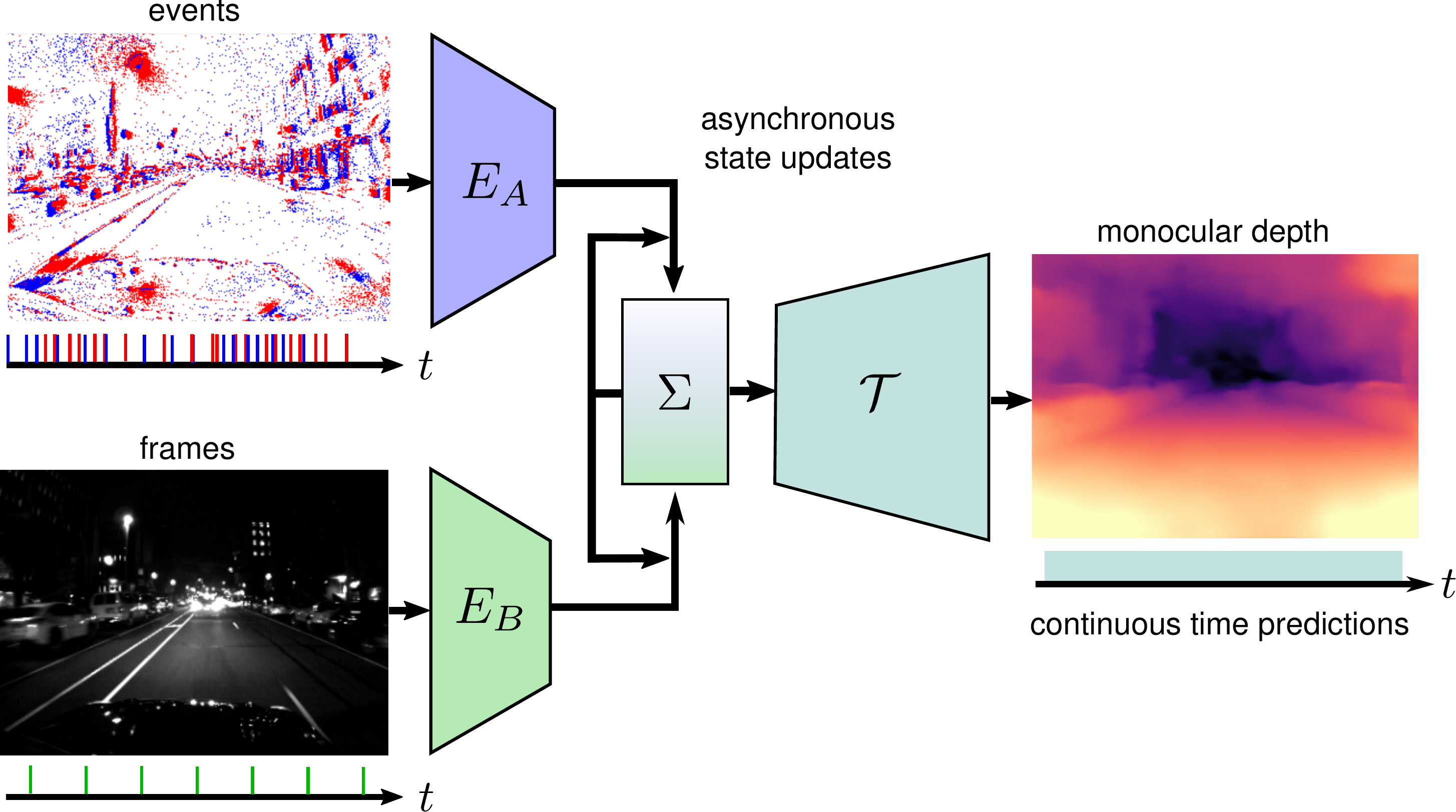
Event cameras are novel vision sensors that report per-pixel brightness changes as a stream of asynchronous "events". They offer significant advantages compared to standard cameras due to their high temporal resolution, high dynamic range and lack of motion blur. However, events only measure the varying component of the visual signal, which limits their ability to encode scene context. By contrast, standard cameras measure absolute intensity frames, which capture a much richer representation of the scene. Both sensors are thus complementary. However, due to the asynchronous nature of events, combining them with synchronous images remains challenging, especially for learning-based methods. This is because traditional recurrent neural networks (RNNs) are not designed for asynchronous and irregular data from additional sensors. To address this challenge, we introduce Recurrent Asynchronous Multimodal (RAM) networks, which generalize traditional RNNs to handle asynchronous and irregular data from multiple sensors. Inspired by traditional RNNs, RAM networks maintain a hidden state that is updated asynchronously and can be queried at any time to generate a prediction. We apply this novel architecture to monocular depth estimation with events and frames where we show an improvement over state-of-the-art methods by up to 30\% in terms of mean absolute depth error. To enable further research on multimodal learning with events, we release EventScape, a new dataset with events, intensity frames, semantic labels, and depth maps recorded in the CARLA simulator.
References
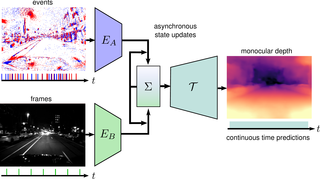
Combining Events and Frames using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction
IEEE Robotics and Automation Letters (RA-L), 2021.
Learning Monocular Dense Depth from Events
Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. Compared to conventional image sensors, they offer significant advantages: high temporal resolution, high dynamic range, no motion blur, and much lower bandwidth. Recently, learning-based approaches have been applied to event-based data, thus unlocking their potential and making significant progress in a variety of tasks, such as monocular depth prediction. Most existing approaches use standard feed-forward architectures to generate network predictions, which do not leverage the temporal consistency presents in the event stream. We propose a recurrent architecture to solve this task and show significant improvement over standard feed-forward methods. In particular, our method generates dense depth predictions using a monocular setup, which has not been shown previously. We pretrain our model using a new dataset containing events and depth maps recorded in the CARLA simulator. We test our method on the Multi Vehicle Stereo Event Camera Dataset (MVSEC). Quantitative experiments show up to 50% improvement in average depth error with respect to previous event-based methods.
References

Learning Monocular Dense Depth from Events
IEEE International Conference on 3D Vision (3DV), 2020.
Event-based Asynchronous Sparse Convolutional Networks
Event cameras are bio-inspired sensors that respond to per-pixel brightness changes in the form of asynchronous and sparse "events". Recently, pattern recognition algorithms, such as learning-based methods, have made significant progress with event cameras by converting events into synchronous dense, image-like representations and applying traditional machine learning methods developed for standard cameras. However, these approaches discard the spatial and temporal sparsity inherent in event data at the cost of higher computational complexity and latency. In this work, we present a general framework for converting models trained on synchronous image-like event representations into asynchronous models with identical output, thus directly leveraging the intrinsic asynchronous and sparse nature of the event data. We show both theoretically and experimentally that this drastically reduces the computational complexity and latency of high-capacity, synchronous neural networks without sacrificing accuracy. In addition, our framework has several desirable characteristics: (i) it exploits spatio-temporal sparsity of events explicitly, (ii) it is agnostic to the event representation, network architecture, and task, and (iii) it does not require any train-time change, since it is compatible with the standard neural networks' training process. We thoroughly validate the proposed framework on two computer vision tasks: object detection and object recognition. In these tasks, we reduce the computational complexity up to 20 times with respect to high-latency neural networks. At the same time, we outperform state-of-the-art asynchronous approaches up to 24% in prediction accuracy.
References

Event-based Asynchronous Sparse Convolutional Networks
European Conference on Computer Vision (ECCV), Glasgow, 2020.
Event-Based Motion Segmentation by Motion Compensation
In contrast to traditional cameras, whose pixels have a common exposure time, event-based cameras are novel bio-inspired sensors whose pixels work independently and asynchronously output intensity changes (called "events"), with microsecond resolution. Since events are caused by the apparent motion of objects, event-based cameras sample visual information based on the scene dynamics and are, therefore, a more natural fit than traditional cameras to acquire motion, especially at high speeds, where traditional cameras suffer from motion blur. However, distinguishing between events caused by different moving objects and by the camera's ego-motion is a challenging task. We present the first per-event segmentation method for splitting a scene into independently moving objects. Our method jointly estimates the event-object associations (i.e., segmentation) and the motion parameters of the objects (or the background) by maximization of an objective function, which builds upon recent results on event-based motion-compensation. We provide a thorough evaluation of our method on a public dataset, outperforming the state-of-the-art by as much as 10%. We also show the first quantitative evaluation of a segmentation algorithm for event cameras, yielding around 90% accuracy at 4 pixels relative displacement.
References

Event-Based Motion Segmentation by Motion Compensation
IEEE International Conference on Computer Vision (ICCV), 2019.
End-to-End Learning of Representations for Asynchronous Event-Based Data
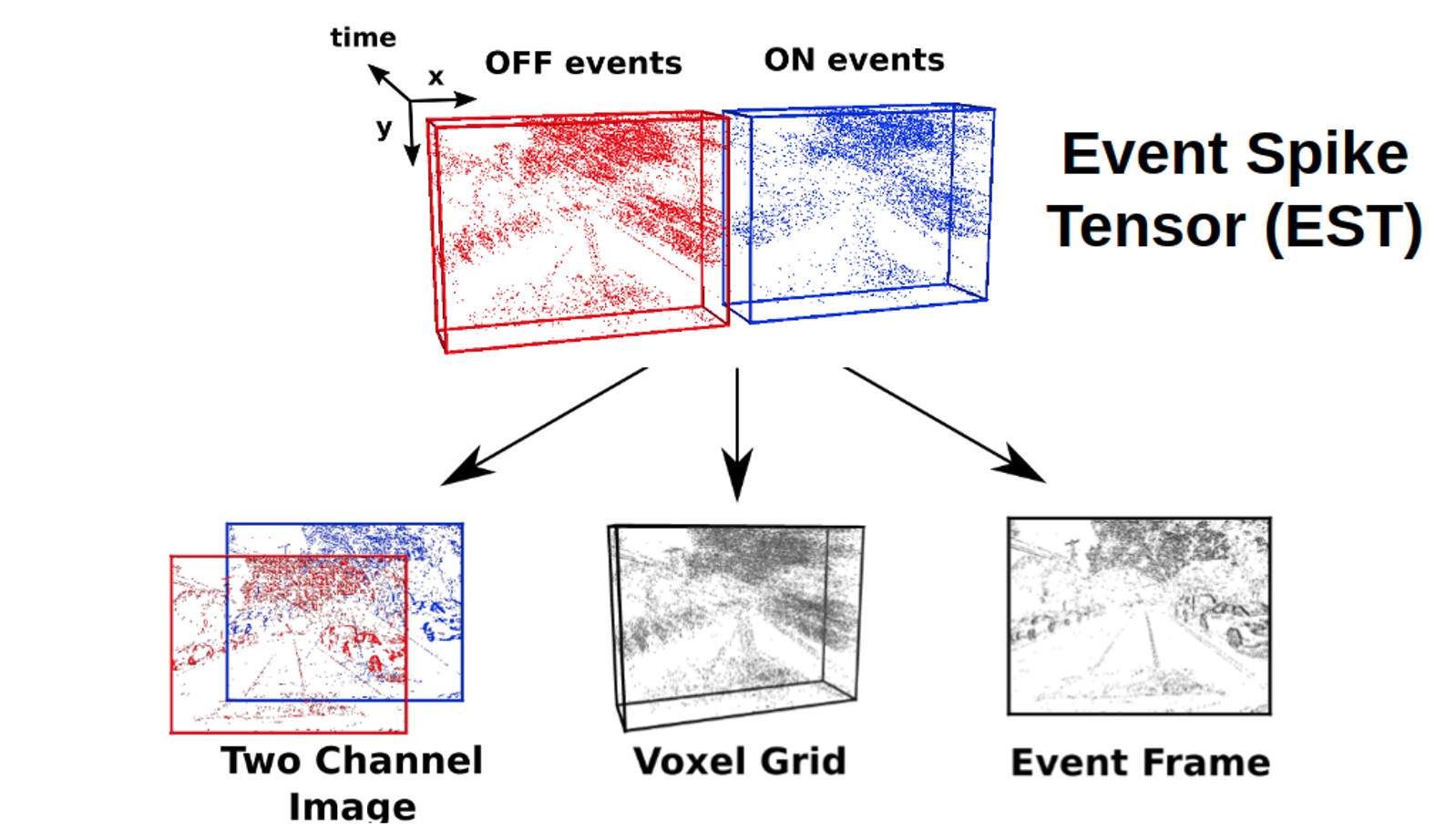
Event cameras are vision sensors that record asynchronous streams of per-pixel brightness changes, referred to as "events". They have appealing advantages over frame-based cameras for computer vision, including high temporal resolution, high dynamic range, and no motion blur. Due to the sparse, non-uniform spatiotemporal layout of the event signal, pattern recognition algorithms typically aggregate events into a grid-based representation and subsequently process it by a standard vision pipeline, e.g., Convolutional Neural Network (CNN). In this work, we introduce a general framework to convert event streams into grid-based representations through a sequence of differentiable operations. Our framework comes with two main advantages: (i) allows learning the input event representation together with the task dedicated network in an end to end manner, and (ii) lays out a taxonomy that unifies the majority of extant event representations in the literature and identifies novel ones. Empirically, we show that our approach to learning the event representation end-to-end yields an improvement of approximately 12% on optical flow estimation and object recognition over state-of-the-art methods.