

Unsupervised Moving Object Detection
via Contextual Information Separation
References

Unsupervised Moving Object Detection via Contextual Information Separation
Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
PDF Video Project CodeDescription
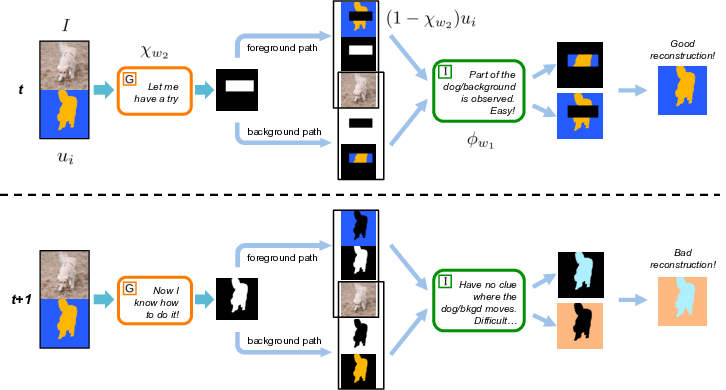
We formulate motion segmentation in an adversarial fashion: The motion of an object and of the background are uncorrelated, therefore they can't be recovered from one another.

Our training procedure is composed of two actors, a generator G and an impainter I. The generator G tries to compute a mask of the optical flow such that the impainter I would do the worst possible job in recovering the original optical flow from the masked one.
Download
Project Code
We publicly release our training and testing code. Code documentation available in the GitHub folder.
Precomputed Results [4MB]
This archive contains the object detection masks obtained by our method after post-processing for the DAVIS 2016, FBMS59 and SegTrackV2 datasets.

Pretrained Models [215MB]
This archive contains the trained weights of the models we used for our experiments.