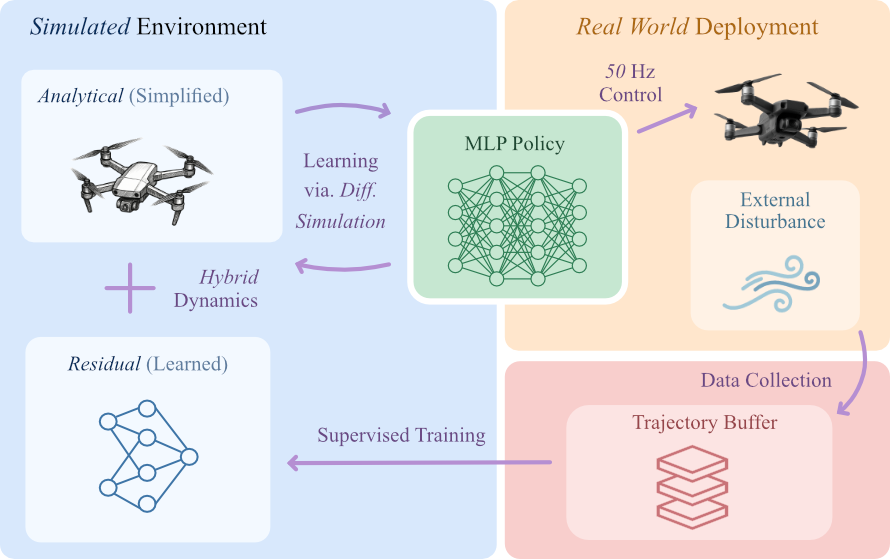
Adapt the policy to unknown disturbances within 5 seconds
Real-time online learning — both residual dynamics and control policy are continuously updated during deployment
vs. L1-MPC
vs. DATT
control
Abstract
Learning control policies in simulation enables rapid, safe, and cost-effective development of advanced robotic capabilities. However, transferring these policies to the real world remains difficult due to the sim-to-real gap, where unmodeled dynamics and environmental disturbances can degrade policy performance. Existing approaches, such as domain randomization and Real2Sim2Real pipelines, can improve policy robustness, but either struggle under out-of-distribution conditions or require costly offline retraining.
In this work, we approach these problems from a different perspective. Instead of relying on diverse training conditions before deployment, we focus on rapidly adapting the learned policy in the real world in an online fashion. To achieve this, we propose a novel online adaptive learning framework that unifies residual dynamics learning with real-time policy adaptation inside a differentiable simulation. Starting from a simple dynamics model, our framework refines the model continuously with real-world data to capture unmodeled effects and disturbances such as payload changes and wind. The refined dynamics model is embedded in a differentiable simulation framework, enabling gradient backpropagation through the dynamics and thus rapid, sample-efficient policy updates beyond the reach of classical RL methods like PPO.
All components of our system are designed for rapid adaptation, enabling the policy to adjust to unseen disturbances within 5 seconds of training. We validate the approach on agile quadrotor control under various disturbances in both simulation and the real world.
Method
Our approach consists of two phases: policy pretraining and online adaptation. During pretraining, we train a base policy using a low-fidelity analytical dynamics model without residual dynamics. During online adaptation, residual dynamics learning, policy adaptation, and real-world deployment run in parallel across multiple threads.
Differentiable Simulation
We model the quadrotor as a discrete-time dynamical system with a differentiable hybrid dynamics model comprising analytical and learned residual components. All components are fully differentiable, allowing gradient backpropagation through the simulation.
Residual Dynamics Learning
An MLP network is trained to predict residual acceleration - the difference between ground-truth acceleration measured on the real system and theoretical acceleration from the analytical dynamics model. This captures unmodeled effects and disturbances.
Online Policy Adaptation
The policy is optimized using analytical gradients via Back-Propagation Through Time (BPTT). An alternating optimization scheme interleaves residual model updates and policy learning, ensuring each real-world sample contributes to both model fidelity and control performance.
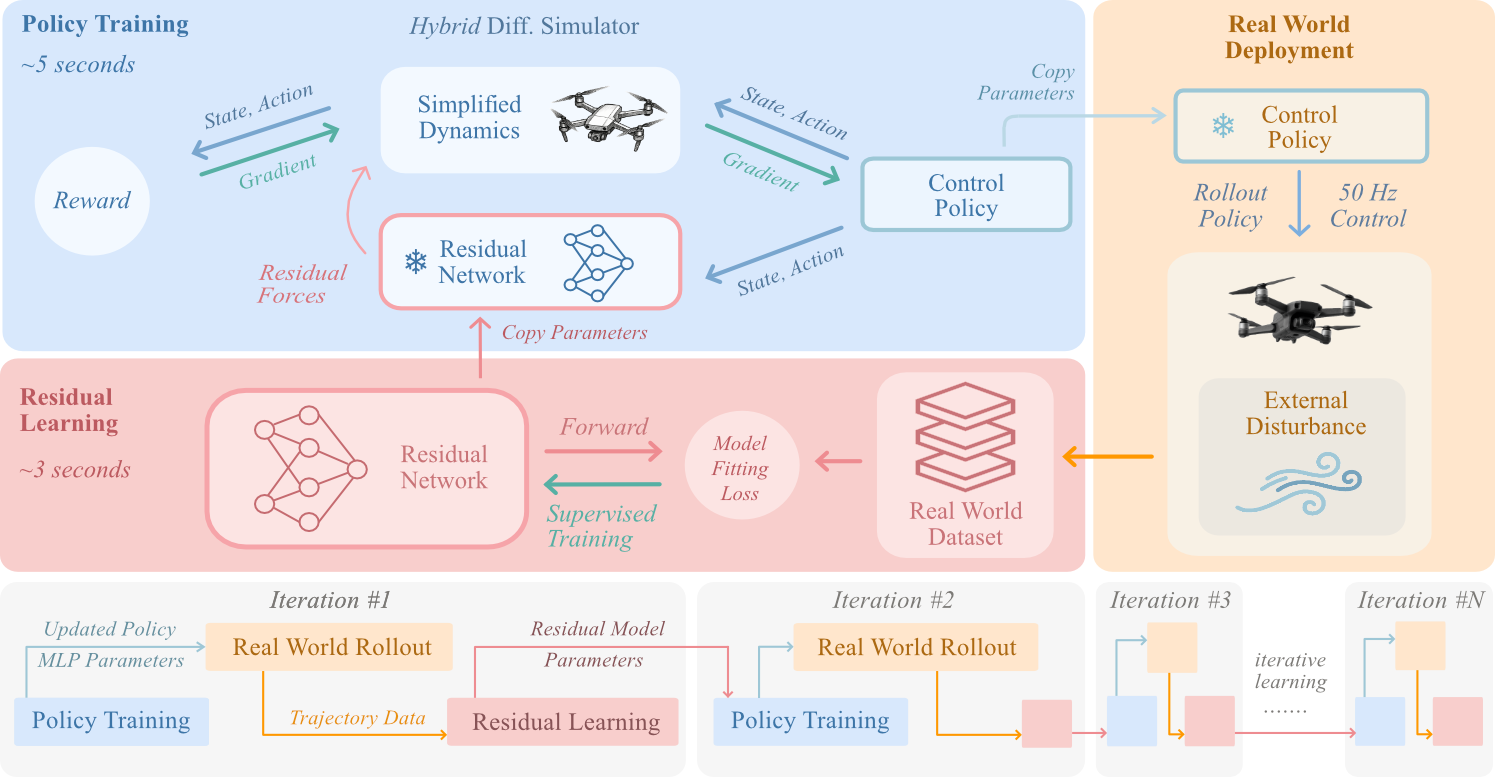
Detailed framework illustration. Information flow within and between the three interleaved components: residual dynamics learning, differentiable simulation, and policy adaptation. These components operate concurrently across multiple threads in separate ROS nodes.
Key Contributions
First Real-Time Differentiable Sim Adaptation
To the best of our knowledge, this is the first demonstration of coupling a differentiable simulator with real-time residual learning to achieve rapid, closed-loop policy adaptation in the real world.
Continuous Model Calibration
The framework continuously calibrates a lightweight analytical dynamics model with real-world data, allowing fast and stable adaptation to unseen disturbances.
Alternating Optimization
An alternating optimization scheme interleaves residual model updates and policy learning in a closed-loop manner, ensuring each real-world sample contributes to both model fidelity and control performance.
State and Vision-Based Control
The framework supports both state-based and visual feature-based inputs (without explicit state estimation), demonstrating effectiveness in both simulated and real-world experiments.
Experimental Results
We evaluate our approach on agile quadrotor control tasks including stabilizing hover and trajectory tracking under various environmental disturbances in both simulation and real-world settings.
State-Based Hovering Performance
| Method | No Disturbance | Small Disturbance | Large Disturbance |
|---|---|---|---|
| Base DiffSim | 0.128 m | 0.328 m | 1.228 m |
| L1-MPC | 0.091 m | 0.134 m | 0.552 m |
| DATT (PPO) | 0.013 m | 0.009 m | 0.231 m |
| Ours | 0.015 m | 0.008 m | 0.105 m |
Average steady-state error (in m) from the hovering target across 8 rollouts. Our method achieves 81% error reduction compared to L1-MPC and 55% compared to DATT under large disturbances.
Trajectory Tracking Performance
| Trajectory | Method | No Disturbance | Small Disturbance | Large Disturbance |
|---|---|---|---|---|
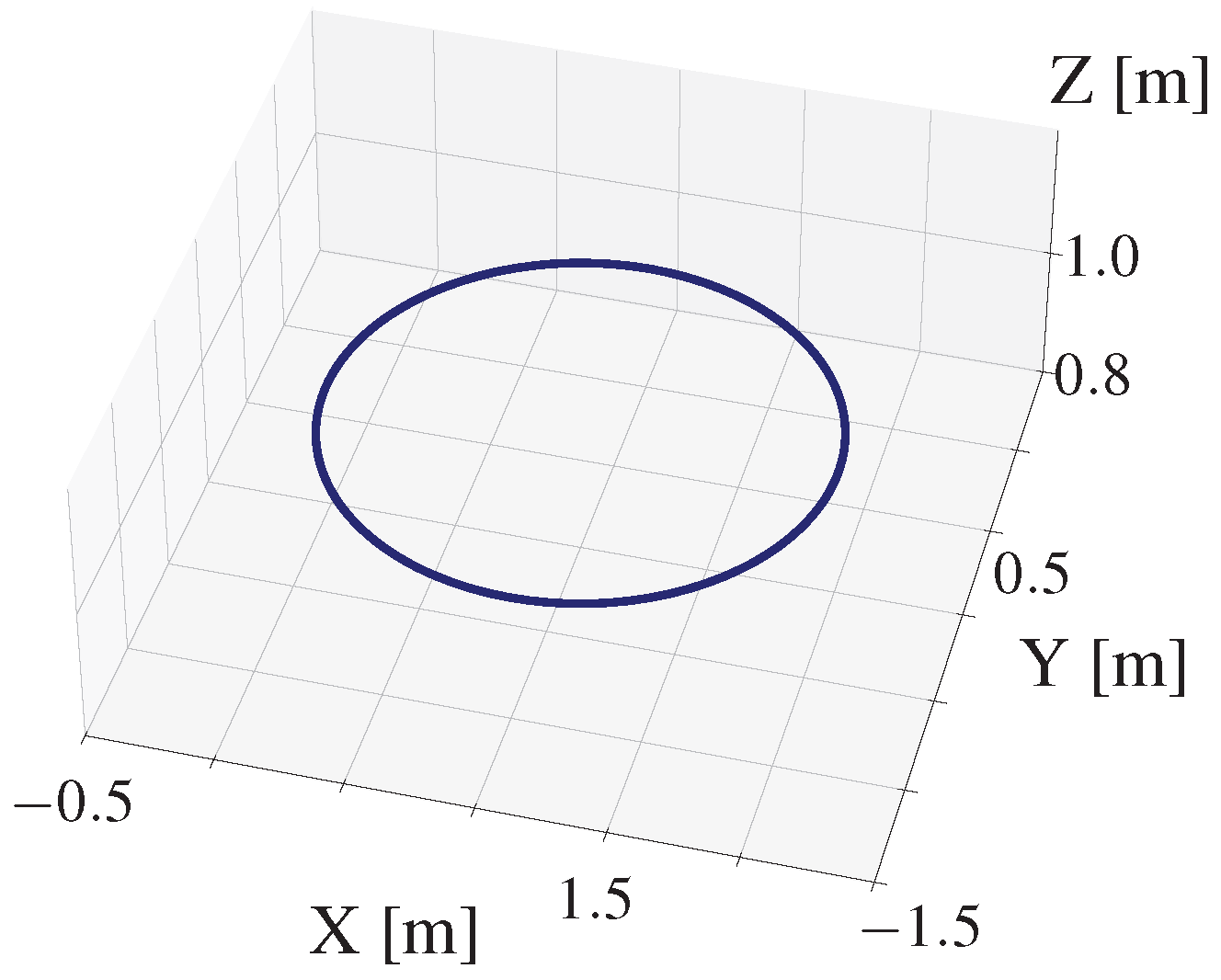
Circle
|
Base DiffSim | 0.365 m | 0.571 m | 1.479 m |
| L1-MPC | 0.113 m | 0.096 m | 0.410 m | |
| DATT (PPO) | 0.058 m | 0.040 m | crash | |
| Ours | 0.167 m | 0.135 m | 0.349 m | |
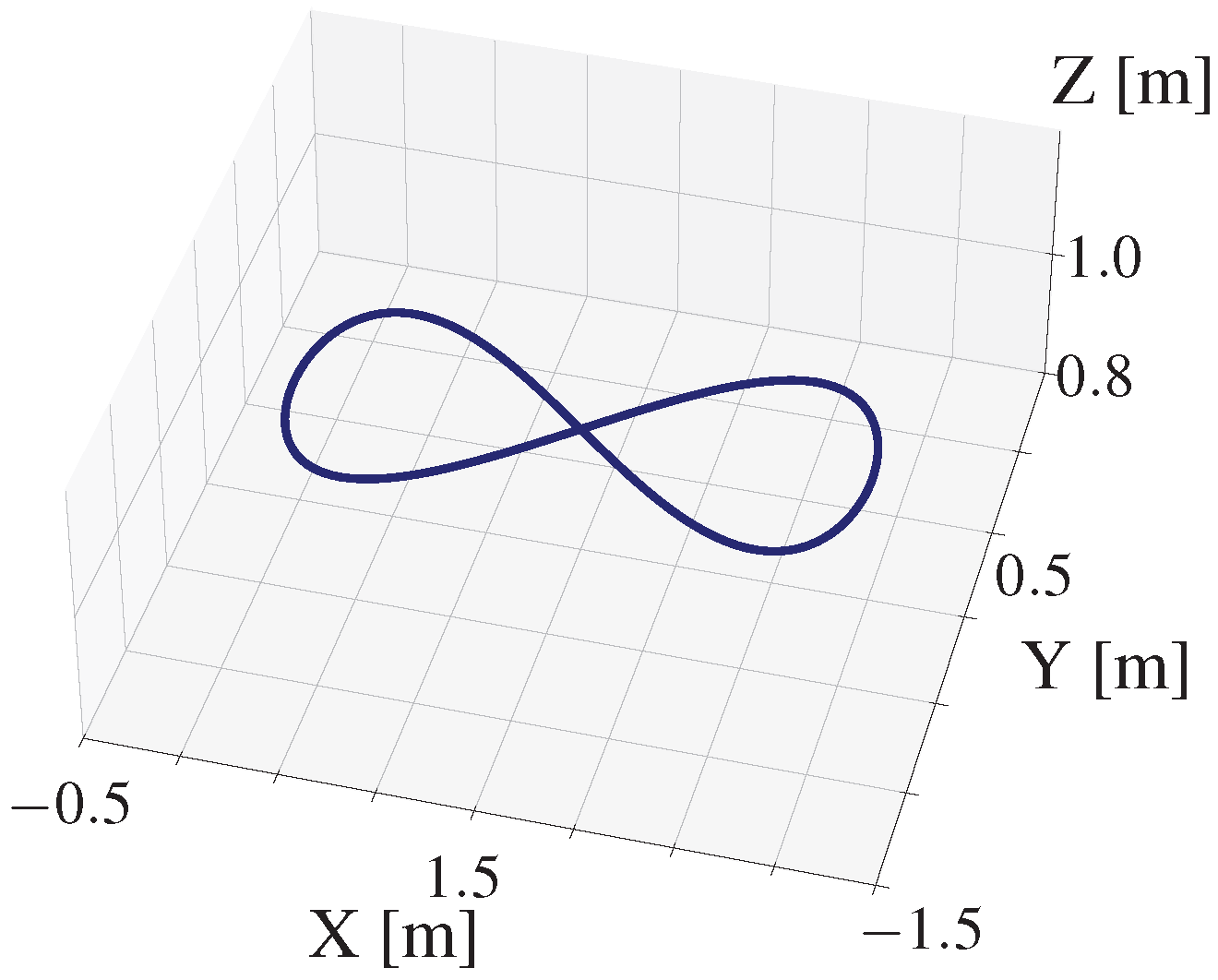
Figure-8
|
Base DiffSim | 0.313 m | 0.492 m | 1.363 m |
| L1-MPC | 0.109 m | 0.121 m | 0.281 m | |
| DATT (PPO) | 0.078 m | 0.082 m | crash | |
| Ours | 0.068 m | 0.045 m | 0.137 m | |
5-Point Star
|
Base DiffSim | 0.453 m | 0.467 m | 0.844 m |
| L1-MPC | 0.295 m | 0.218 m | 0.417 m | |
| DATT (PPO) | 0.087 m | 0.102 m | crash | |
| Ours | 0.126 m | 0.133 m | 0.211 m |
Average tracking errors (in m) for three different trajectories (Circle, Figure-8, and 5-Point Star). Our method achieves consistent performance across all trajectories and demonstrates robustness to large disturbances where DATT fails.
Rapid Adaptation Demonstration

Real-world trajectory tracking adaptation. The policy rapidly learns within 2 updates (10 seconds of flight) to compensate for the large sim-to-real gap caused by model mismatch in pretraining.
Computational Efficiency
In comparison, DATT requires 20 million simulation steps and approximately 2 hours of training.
Real-World Validation
We conducted real-world experiments using two quadrotors: a small lightweight quadrotor (190g) and a larger, heavier one (600g) with different dynamical properties. Experiments include added mass (37% increase), wind disturbances from a fan, and significant model mismatches.
Wind Disturbances
Complex, state-dependent forces on modified quadrotor with non-uniform drag profile
Added Mass
37% mass increase with altered inertial properties
Trajectory Tracking
Circle, Figure-8, and 5-Point Star trajectories with varying smoothness
Citation
@article{pan2025learning,
title={Learning on the Fly: Rapid Policy Adaptation via Differentiable Simulation},
author={Pan, Jiahe and Xing, Jiaxu and Reiter, Rudolf and Zhai, Yifan and Aljalbout, Elie and Scaramuzza, Davide},
journal={IEEE Robotics and Automation Letters},
year={2026},
publisher={IEEE}
}
Acknowledgements
This work was supported by the European Union's Horizon Europe Research and Innovation Programme under grant agreement No. 101120732 (AUTOASSESS) and the European Research Council (ERC) under grant agreement No. 864042 (AGILEFLIGHT).