Abstract
Imitation learning with a privileged teacher has proven effective for learning complex control behaviors from high-dimensional inputs, such as images. In this framework, a teacher is trained with privileged task information, while a student tries to predict the actions of the teacher with more limited observations, e.g., in a robot navigation task, the teacher might have access to distances to nearby obstacles, while the student only receives visual o servations of the scene. However, privileged imitation learning faces a key challenge: the student might be unable to imitate the teacher’s behavior dueto partial observability. This proble arises because the teacher is trained without considering if the student is capable of imitating the learned behavior. To address this teacher-student asymmetry, we propose a framework for joint training of the teacher and student poli ies, encouraging the teacher to learn behaviors that can be imitated by the student despite the latters’ limited access to information and its partial observability. Based on the performance bound in imitation learning, we add (i) the approximated action difference between teacher and student as a penalty term to the reward function of the teacher, and (ii) a supervised teacher-student alignment step. We motivate our method with a maze navigationtask and demonstrate its effectiveness on complex vision-based quadrotor flight and manipulation tasks.
Method
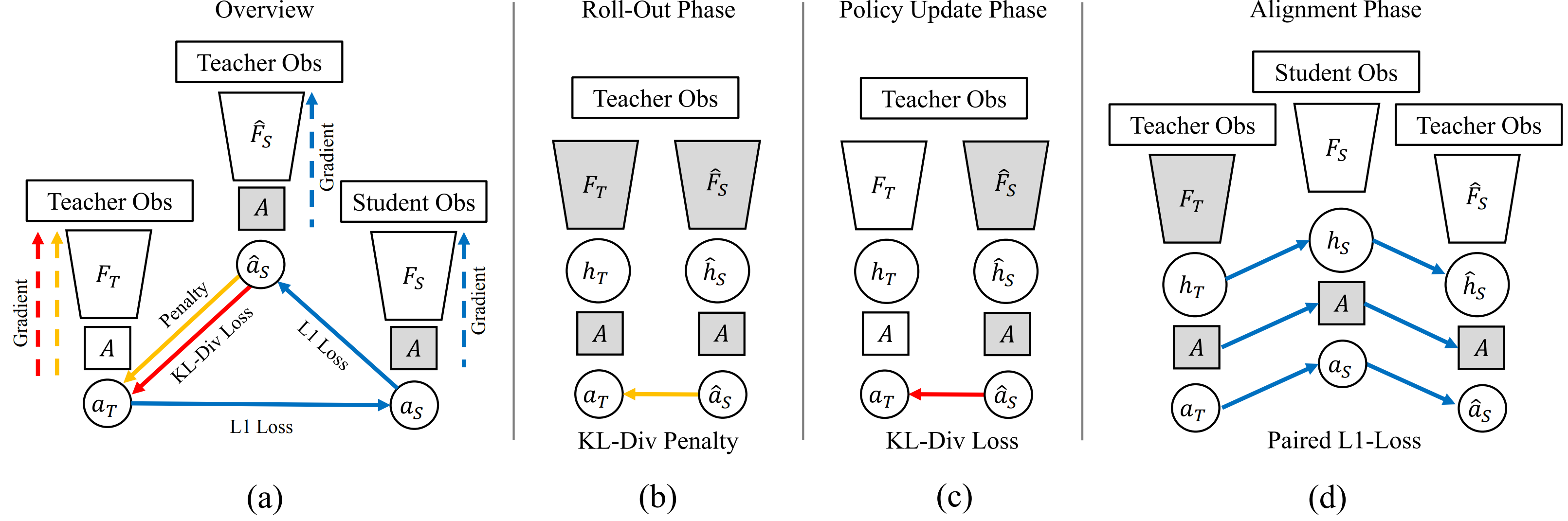
Our method leverages three networks (a), which are trained in three alternating phases: the roll-out phase (b), the policy update phase (c), and the alignment phase (d). The grey boxes represent networks frozen during the specific phase and the dashed arrows indicate the gradient flow. (b) In the roll-out phase, the KL-Divergence between the proxy student and teacher is used as a penalty term. (c) In addition to the policy gradient, the teacher encoder is updated by backpropagating through the KL-Divergence between the action distribution of the teacher and the proxy student. (d) Using student observations, the proxy student is aligned to the student while the student is aligned to the teacher network using consistency losses.
Results: Maze
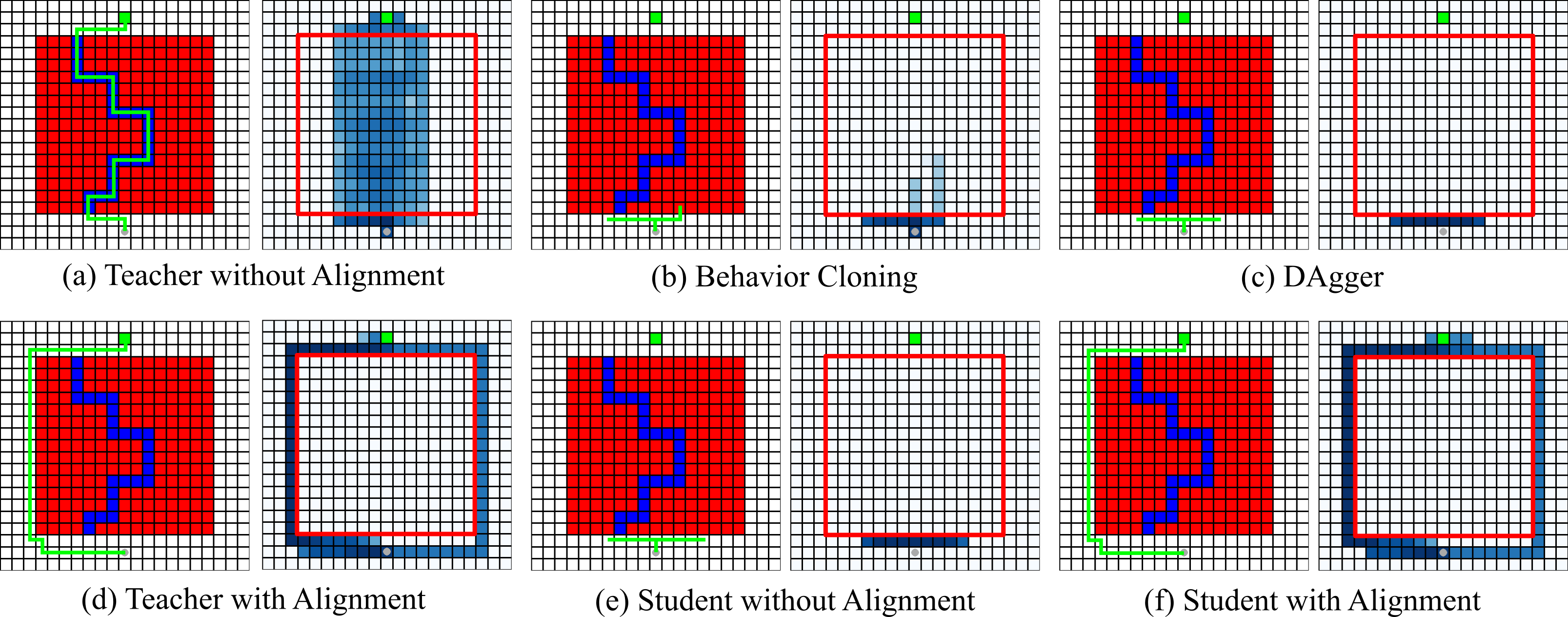
The goal of the agent is to navigate from the start (grey point) to the goal (green cell). The environment consists of four types of cells: empty (white), lava (red), and path (blue). The teacher can see all cell types while the student can not distinguish between lava and path. A teacher trained without alignment finds its optimal path through the maze (a), which can not be imitated by the student trained without alignment (e), Behavior Cloning (b), and DAgger (c). In contrast, a teacher trained with alignment navigates around the maze (d), which can be easily copied by the student (f).
Results: Quadrotor Flight
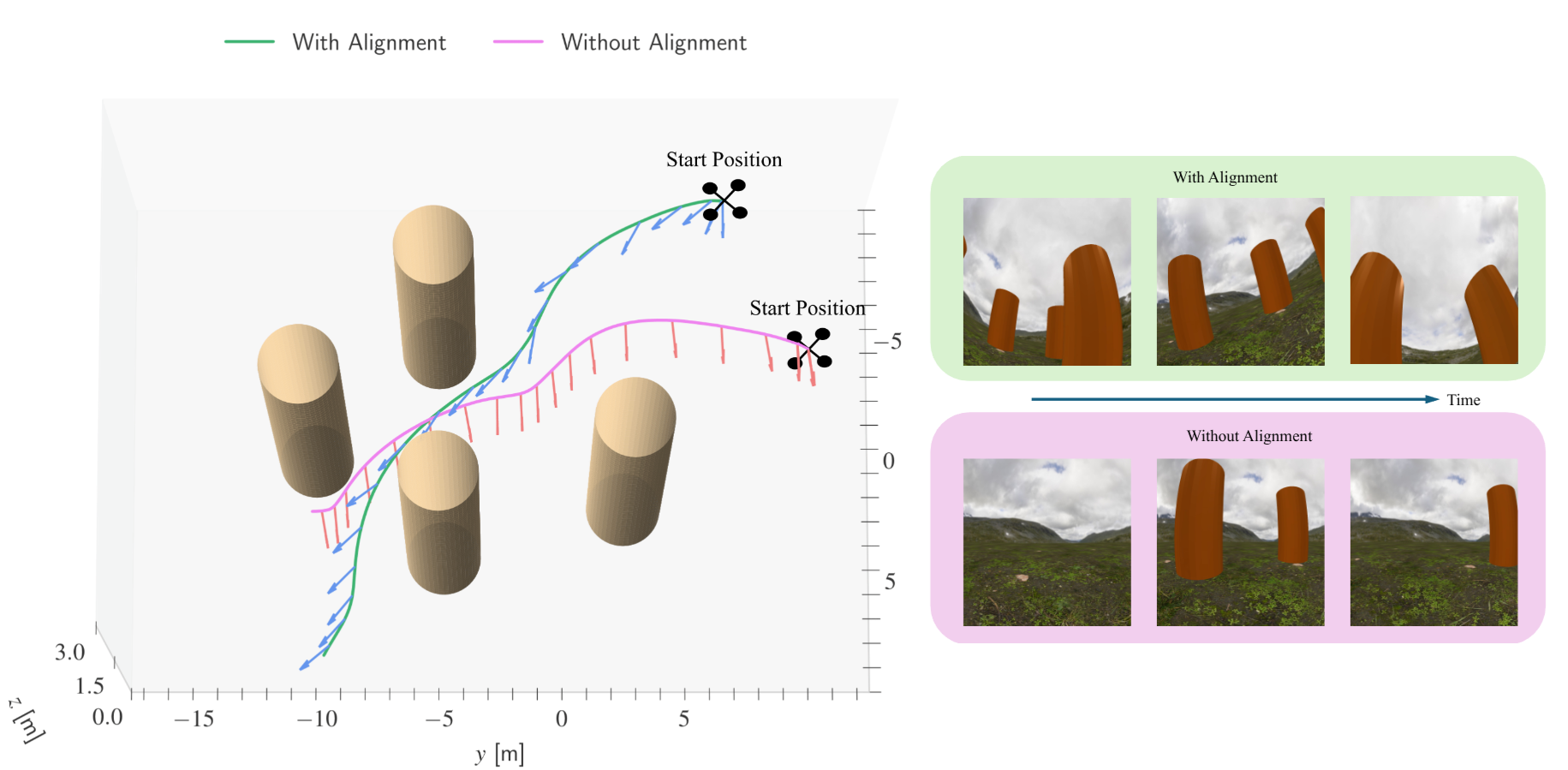
The teacher trajectory rollouts of the vision-based quadrotor obstacle avoidance tasks are visualized. Our approach results in a policy behavior where the quadrotor adjusts the camera’s viewing direction to capture sufficient environmental information for the student policy.
Results: Vision-based Manipulation

On the left, the task of opening a drawer with a robotic arm is visualized for all of the parallel environments. The two images in the center (Without Alignment) are sample images given to the student, which show the teacher behaviors trained without our alignment. Our approach with alignment leads to behaviors that the student can imitate more easily, i.e., the robot does not block the red drawer handle, as visualized in the two images on the right.
BibTeX
@article{messikommer2025student,
title = {Student-Informed Teacher Training},
author = {Messikommer, Nico and Xing, Jiaxu and Aljalbout, Elie and Scaramuzza, Davide},
journal = {International Conference on Learning Representations},
year = {2025},
}